庖丁解牛算法深入解析与实现
版权申诉
137 浏览量
更新于2024-07-03
收藏 186KB DOCX 举报
"庖丁解牛算法代码解读_y.docx"
庖丁解牛算法是一种高效的中文分词算法,主要应用于搜索引擎和自然语言处理领域,尤其在基于Lucene的系统中广泛使用。该算法的设计目的是为了提高中文文本的分词效率和准确性。
**1. 引言**
庖丁解牛算法的核心是PaodingAnalyzer,它是一个自定义的分析器,用于生成能够进行中文分词的TokenStream。其目标是提供一种高效的方法,将中文文本分割成有意义的词语,以供后续的搜索或分析操作。
**2. Paoding分词算法**
2.1 **算法基本思想描述**
算法的基本思想是结合词典和动态编程策略,通过扫描文本并利用词典信息来识别词语边界。它利用了汉字的组合特性,以减少误分词的可能性。
2.2 **庖丁系统的核心内容**
系统的关键在于对输入文本的预处理和词典匹配。预处理包括字符大小写转换和全角半角转换,以确保字符的一致性。词典匹配则通过查找词典中的词汇,确定最可能的分词结果。
2.3 **算法计算详细步骤**
2.3.1 **庖丁分词策略**
策略主要包括寻找最长匹配、最频繁匹配等,旨在找到文本中最有可能的词语组合。
2.3.2 **max-word-length**
这一参数控制最大词长,防止过长的词被误识别。
2.3.3 **most-words**
most-words策略是为了优化性能,选取最可能出现的词语组合,以减少计算量。
2.4 **词典**
2.4.1 **词典类型**
词典包含基础词典、用户自定义词典等,满足不同场景需求。
2.4.2 **词典加载流程**
词典加载涉及从文件读取词汇,构建词汇索引,并存储在内存中以供快速访问。
2.4.3 **词典文件格式**
通常采用特定格式,如文本文件,每一行代表一个词。
2.4.4 **读取词典文件**
读取过程包括解析文件内容,将词汇转换为内部数据结构。
2.4.5 **词典编译**
编译过程将词典文件转化为更高效的格式,以提升查找速度。
2.4.6 **编译词典时间测试**
测试编译过程的性能,以优化词典加载速度。
2.4.7 **词典变更侦测**
当词典内容变化时,系统能够检测到这些变更并自动更新。
**3. 举例说明**
通过具体的文本实例,展示算法如何分词以及在不同情况下的决策过程。
**4. 参考资料**
列举了用于深入研究庖丁解词算法的参考文献和资源。
总结来说,庖丁解牛算法是基于Lucene的中文分词解决方案,它通过巧妙的词典管理和分词策略,实现了高效准确的分词效果。算法的核心在于如何有效地匹配词典中的词汇,同时考虑词频和词长限制,以达到最佳的分词效果。
ii. XY ->XY 只有两个字的孤立字符串作为一个词
iii. XYZ ->XY/YZ 多个字(>=3)的孤立字符串"两两组合"作为一个词
iv. WXYZ ->WX/XY/YZ 同上
collectNumber(collector,beef,offset,limit,binoffset)
如果数字后面跟有单位,单位词单独进行收集
SkipNoiseWords(collector,beef,offset,end,binoffset)
如果 offset+2 的词在 noisewords 词典中查到,则收集该词,如果没有返回 offset
BinDissect(collector,beef,int,int)
孤立词二元切词方法
如果孤立词长度为 1,直接收集该词,不为 1 则进行二元切词
shouldBeWord(beef,int,int)
遇到单引号,书名号,单尖括号,则中间的词为一个词
Collector 接口
Collector 接收 Knife 切割文本得到的词语。
CollectorStdoutImpl 类实现 Collector 接口
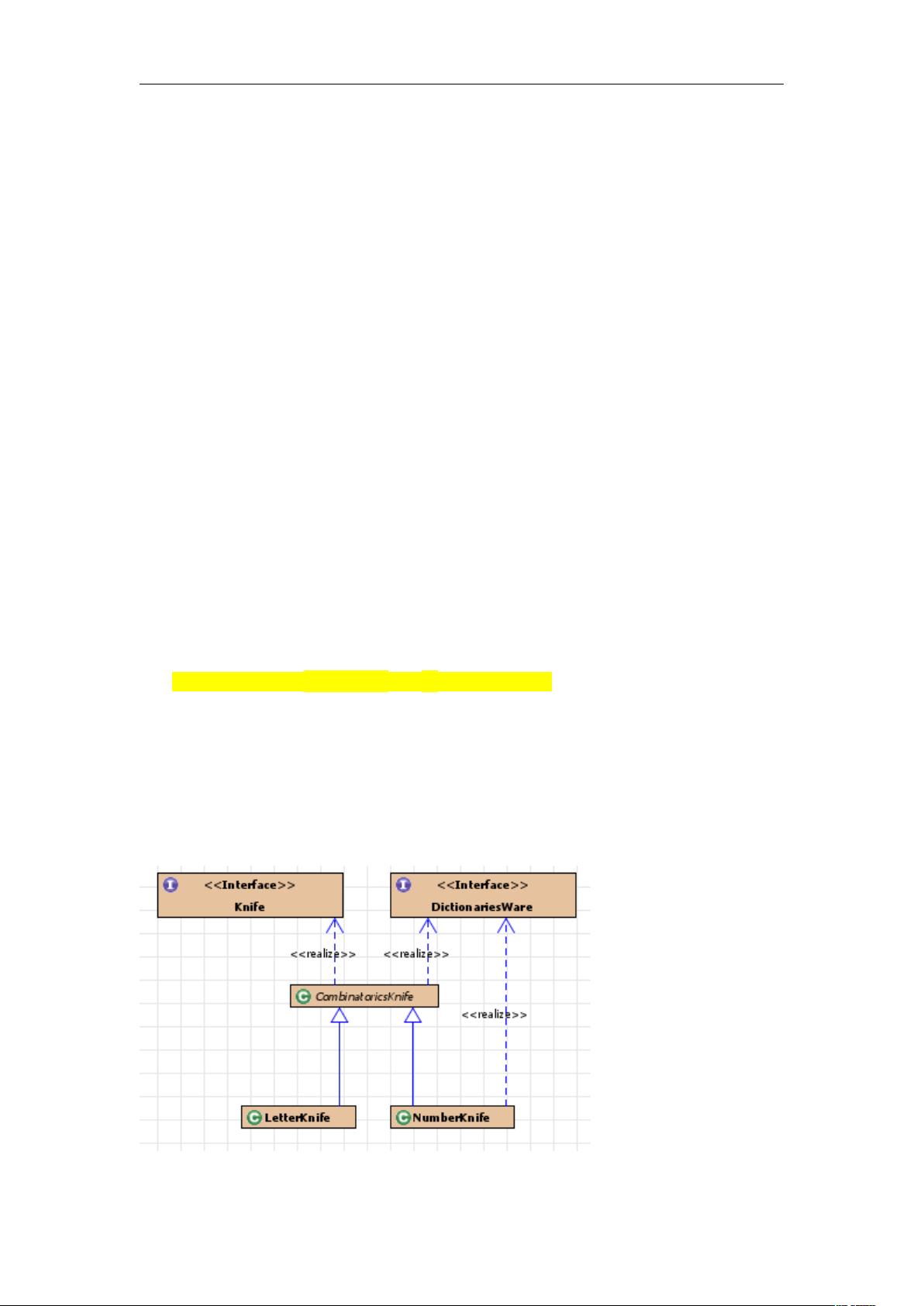
CombinatoricsKnife 抽象类实现 Knife,DiconariesWare
组合刀:遇到需要用 letterKnife,numberKnife 刀切词的统一用组合刀切词
定义变量:
Dictionary combinatoricsDictionary;
HashSet/* <String> */noiseTable value 为 noiseWords
- 4 -
剩余21页未读,继续阅读
160 浏览量
2022-06-19 上传
2022-06-14 上传
644 浏览量
2024-11-06 上传

omyligaga
- 粉丝: 101
 我的内容管理
展开
我的内容管理
展开







最新资源
- 足球模拟标记语言FerSML开源项目发布
- 精选awesome twitter工具列表:提升社交媒体管理效率
- 自制汇编语言计算器:基础运算与存储功能
- 泰迪科技数据产品分析及PowerBI可视化教程
- Elasticsearch聚合值过滤的实现方法
- Android网络通信组件EasyHttp:全面支持Get/Post及下载上传功能
- React元素平移组件:实现Google Maps式DOM操作
- 深入浅出Ajax开发讲义与完整源代码分析
- Vue.js + Electron打造的Twitter客户端功能全面上线
- PHP开发威客平台源码分享:前端后端及多技术项目资源
- 掌握XSS防护:使用xssProtect及核心jar包
- zTree_v3树形结构和拖拽效果的演示与API文档
- Matlab运动检测与测速GUI程序详解与打包指南
- C#中GridView Eval()方法实现数据格式化详解
- Flex快速入门到精通的电子资源与源码
- gulp与Maven结合的示例项目实践指南
