HBase事务处理机制详解:ACID属性和实现技术
需积分: 9 160 浏览量
更新于2024-07-17
收藏 3.82MB PDF 举报
HBase中的事务
HBase是一种基于Apache Hadoop的分布式、面向列的NoSQL数据库,旨在存储大量半结构化和非结构化数据。然而,在高并发环境中,HBase中的数据一致性和事务处理变得非常重要。本节将详细介绍HBase中的事务处理机制,包括事务的目标、Optimistic Concurrency Control、 Apache 项目(Omid、Tephra、Trafodion)以及ACID属性等。
为什么需要事务?
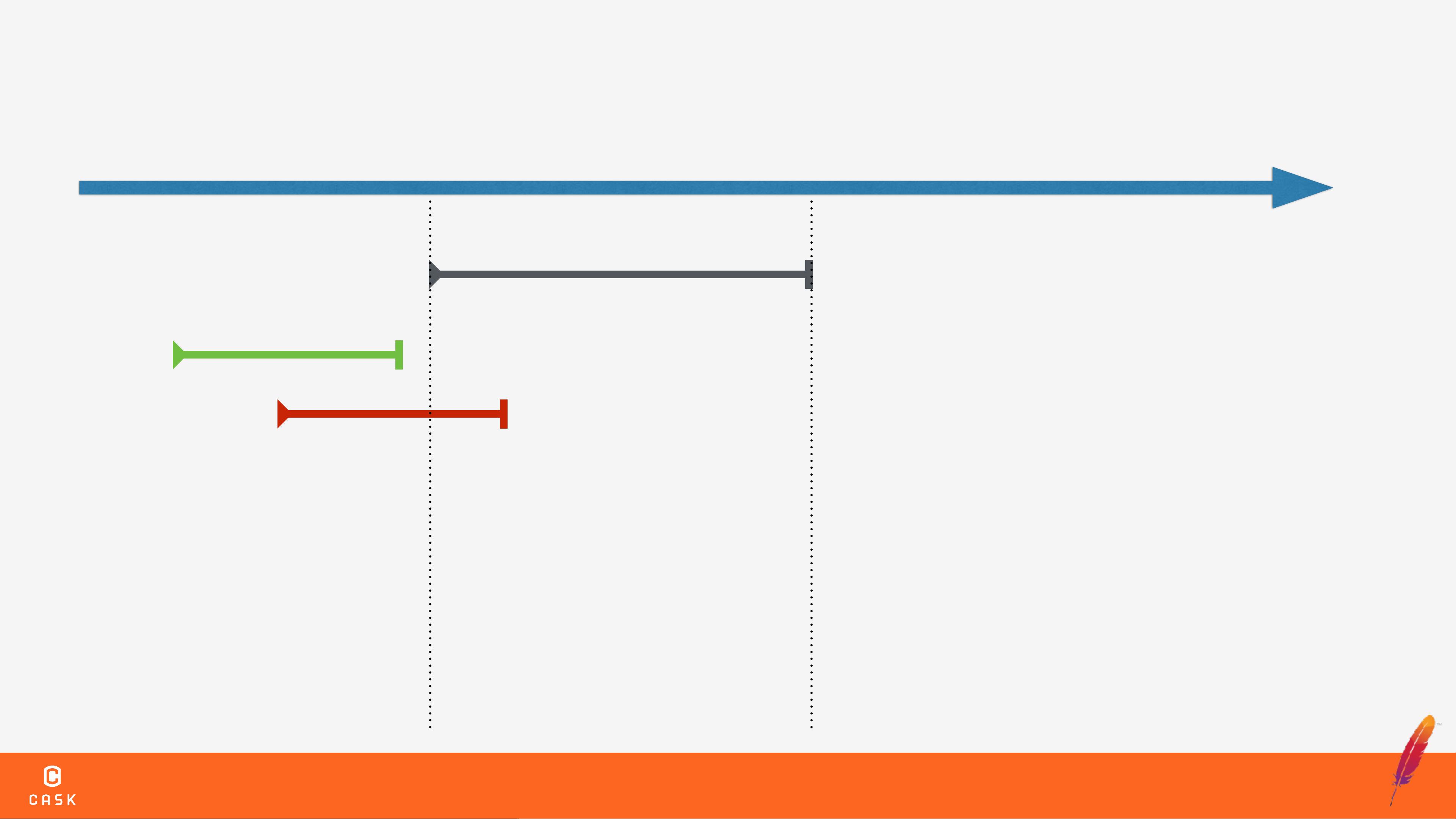
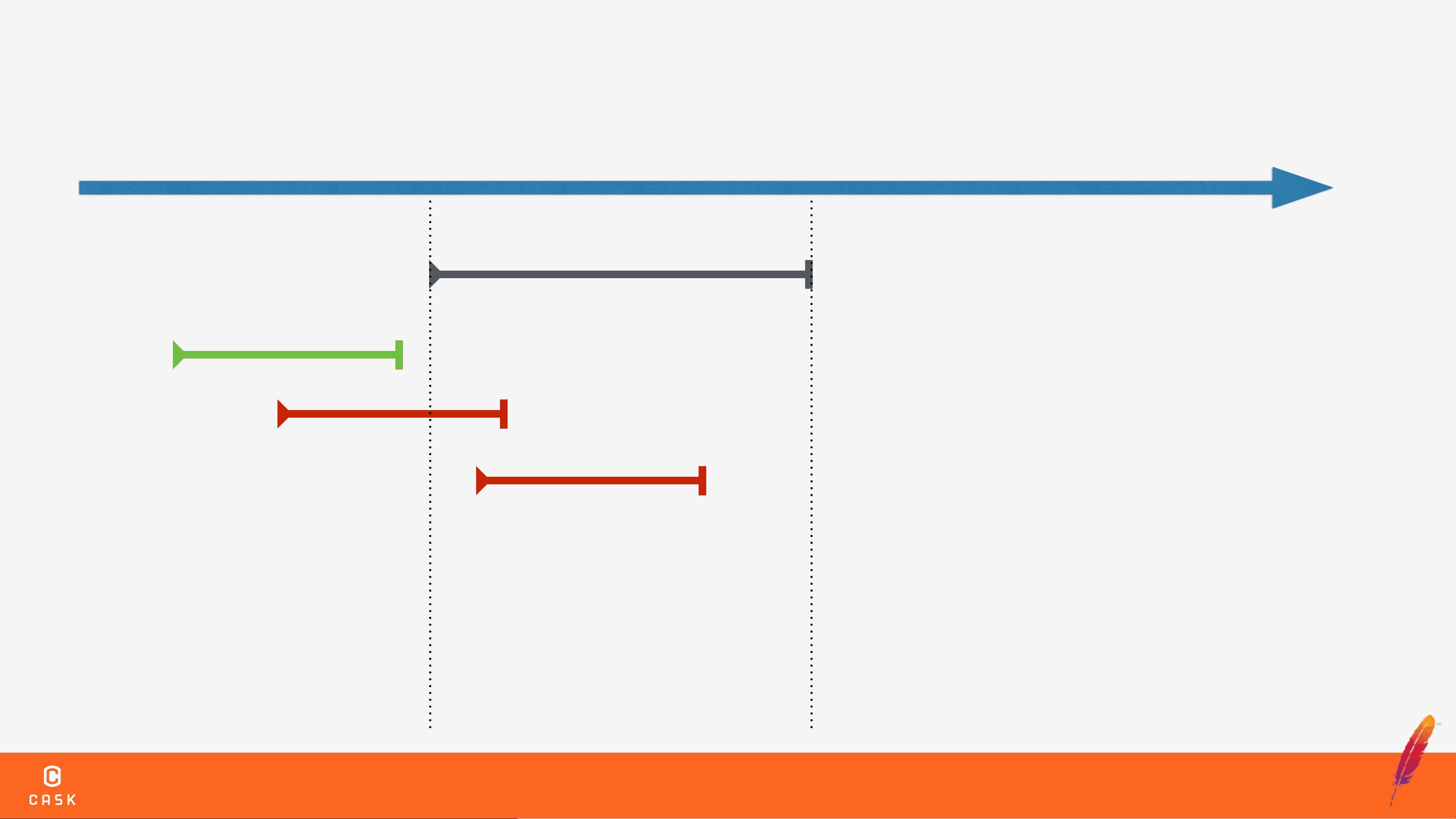
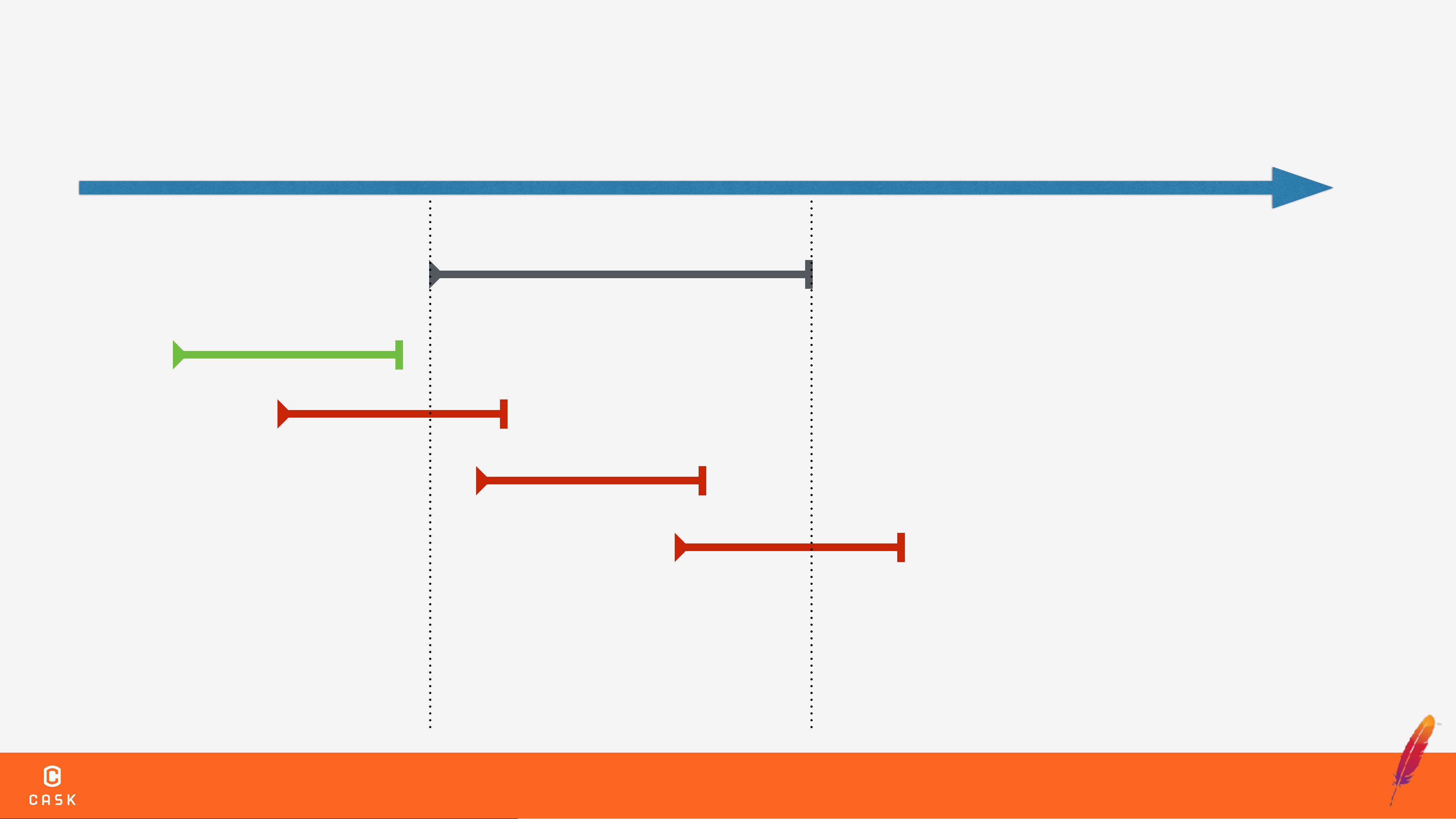
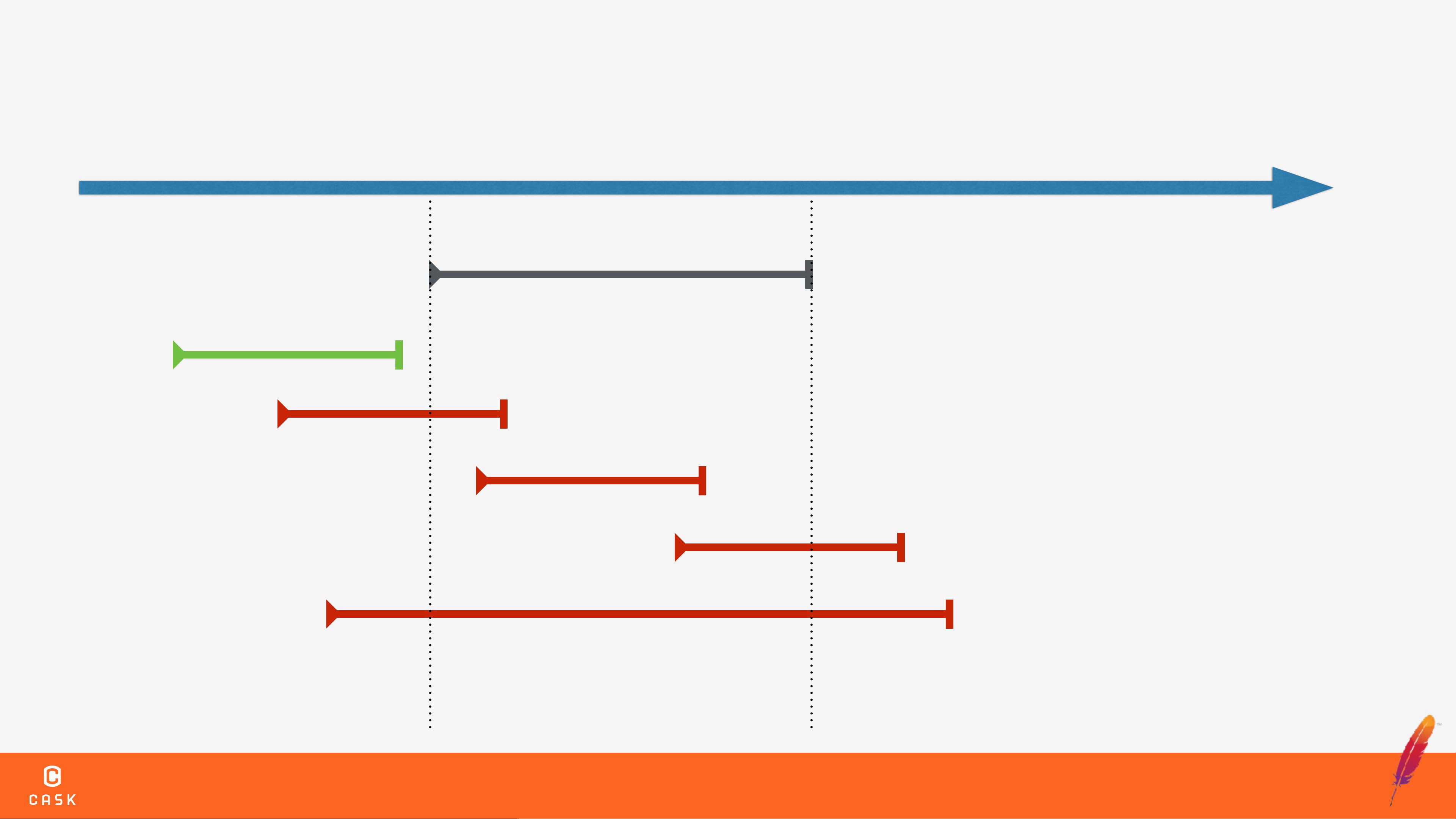
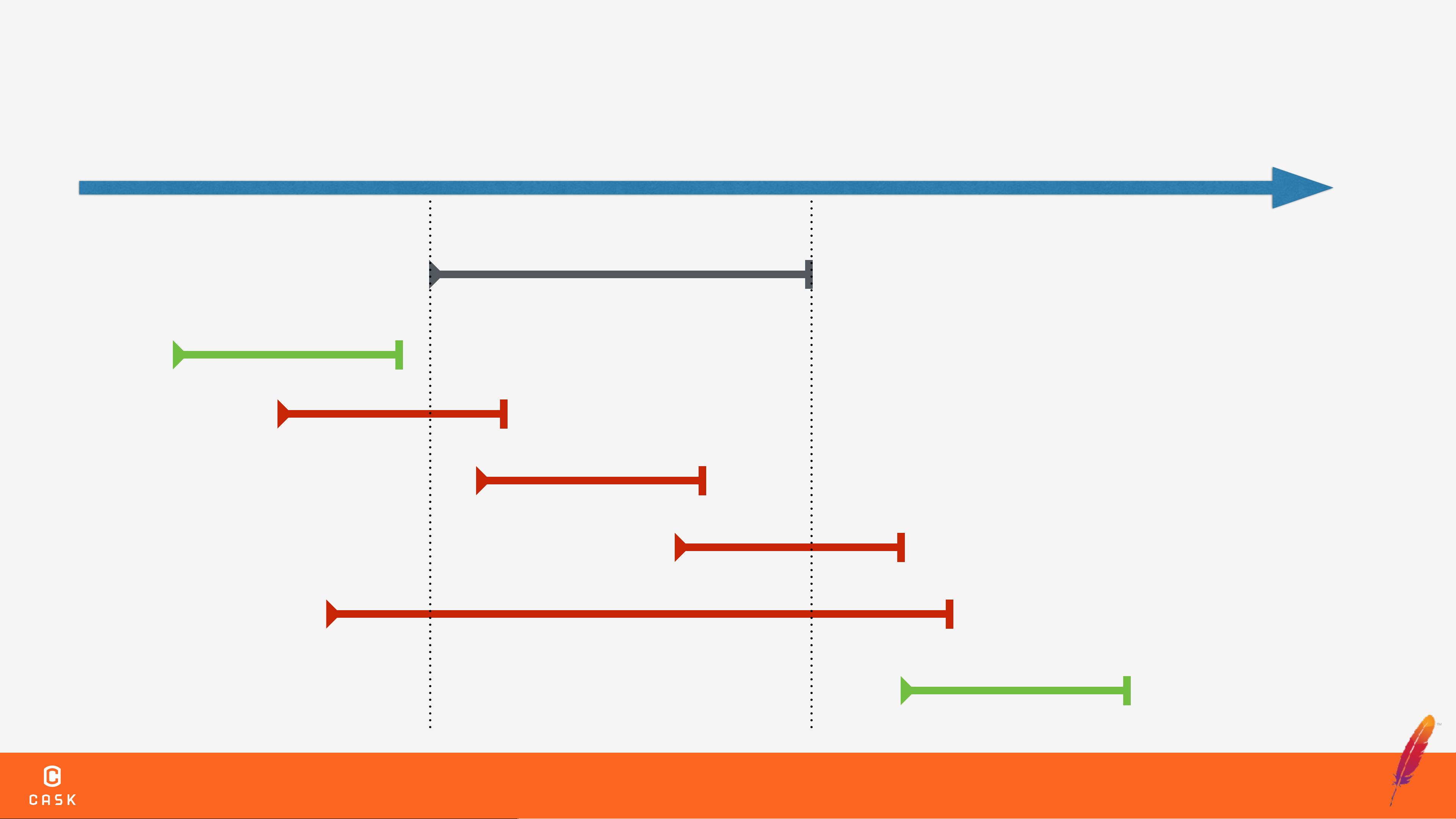
在高并发环境中,数据的一致性和可靠性是非常重要的。如果没有事务处理机制,可能会导致数据不一致、部分输出失败、长时间运行的作业中断等问题。事务处理机制可以确保数据的一致性和可靠性,提供了可靠的数据存储和处理能力。
Optimistic Concurrency Control
Optimistic Concurrency Control是一种乐观的并发控制机制,用于解决高并发环境中的数据一致性问题。该机制假设多个事务之间不会冲突,直到事务提交时才检查是否有冲突。如果发现冲突,事务将被回滚,以确保数据的一致性。
Apache 项目:Omid、Tephra、Trafodion
Omid、Tephra、Trafodion都是Apache项目,旨在解决HBase中的事务处理问题。Omid提供了高性能的事务处理机制,Tephra提供了灵活的事务处理机制,Trafodion提供了基于SQL的事务处理机制。
如何区分这些项目?
Omid、Tephra、Trafodion都提供了事务处理机制,但是它们之间有所区别。Omid提供了高性能的事务处理机制,适合高并发环境;Tephra提供了灵活的事务处理机制,适合复杂的业务场景;Trafodion提供了基于SQL的事务处理机制,适合传统的关系数据库用户。
HBase中的事务处理机制
HBase中的事务处理机制基于Optimistic Concurrency Control机制。HBase使用RegionServer来管理Region,Region是HBase中的基本存储单元。Client可以通过RegionServer来访问HBase中的数据。Write Conflict是HBase中的一个常见问题,解决该问题需要使用事务处理机制。
ACID属性
ACID属性是事务处理机制的基本属性,包括Atomic、Consistent、Isolated、Durable四个方面。
* Atomic:整个事务作为一个单元提交,确保数据的一致性。
* Consistent:事务提交后,数据保持一致性,不存在部分状态改变。
* Isolated:事务之间不相互影响,事务提交后才可见。
* Durable:事务提交后,数据可靠地存储。
HBase中的事务处理机制是确保数据的一致性和可靠性的关键。通过使用Optimistic Concurrency Control机制和ACID属性,HBase可以提供可靠的数据存储和处理能力。
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-12-11 上传
2017-05-25 上传
2022-07-10 上传
2023-05-28 上传
2023-05-28 上传
2023-05-27 上传

weixin_38744435
- 粉丝: 373
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







