"了解MySQL的“order by”语句的执行流程及原理"
需积分: 0 30 浏览量
更新于2024-01-11
收藏 1.05MB PDF 举报
在执行"order by"语句时,MySQL会按照以下步骤进行排序:
1. 初始化sort_buffer,确定放入name、city、age这三个字段。sort_buffer大小取决于MySQL的配置参数sort_buffer_size,默认值为2MB。
2. 从索引city找到第一个满足city='杭州'条件的主键id,并记为id1。这个步骤利用了索引的优势,只需要扫描索引就可以找到匹配条件的数据行,而不用扫描整个表。这样可以大大提高查询效率。
3. 根据id1从t表中取出第一条匹配条件的数据行,并将name、city、age字段放入sort_buffer中。这个数据行也被称为current row。
4. 重复步骤2和3,直到取出了包含满足条件的name、city、age字段的前1000个数据行(根据limit子句指定的数量)。
5. sort_buffer中的数据按照name字段进行排序,得到排序后的结果。这里使用的排序算法通常是快速排序(quick sort)或归并排序(merge sort)。
6. 从排序后的结果中取出前1000个数据行,并返回给应用程序。
需要注意的是,如果排序所需的内存超过了sort_buffer的大小限制,MySQL会自动使用磁盘临时文件来存储排序数据。这样会导致排序速度变慢,因为磁盘IO的速度远低于内存的速度。
此外,在执行"order by"语句时,MySQL还可以利用索引的排序功能来优化查询。在这个例子中,我们可以看到表t定义了一个索引city,该索引的键值是按照city字段的值进行排序的。因此,执行这个查询时,MySQL可以直接利用索引city来排序,而不必使用额外的排序操作。
综上所述,“order by”语句的执行流程大致如上所述。使用合适的索引、适当配置sort_buffer_size以及优化查询语句,可以提高"order by"语句的执行效率,从而使查询结果快速返回。
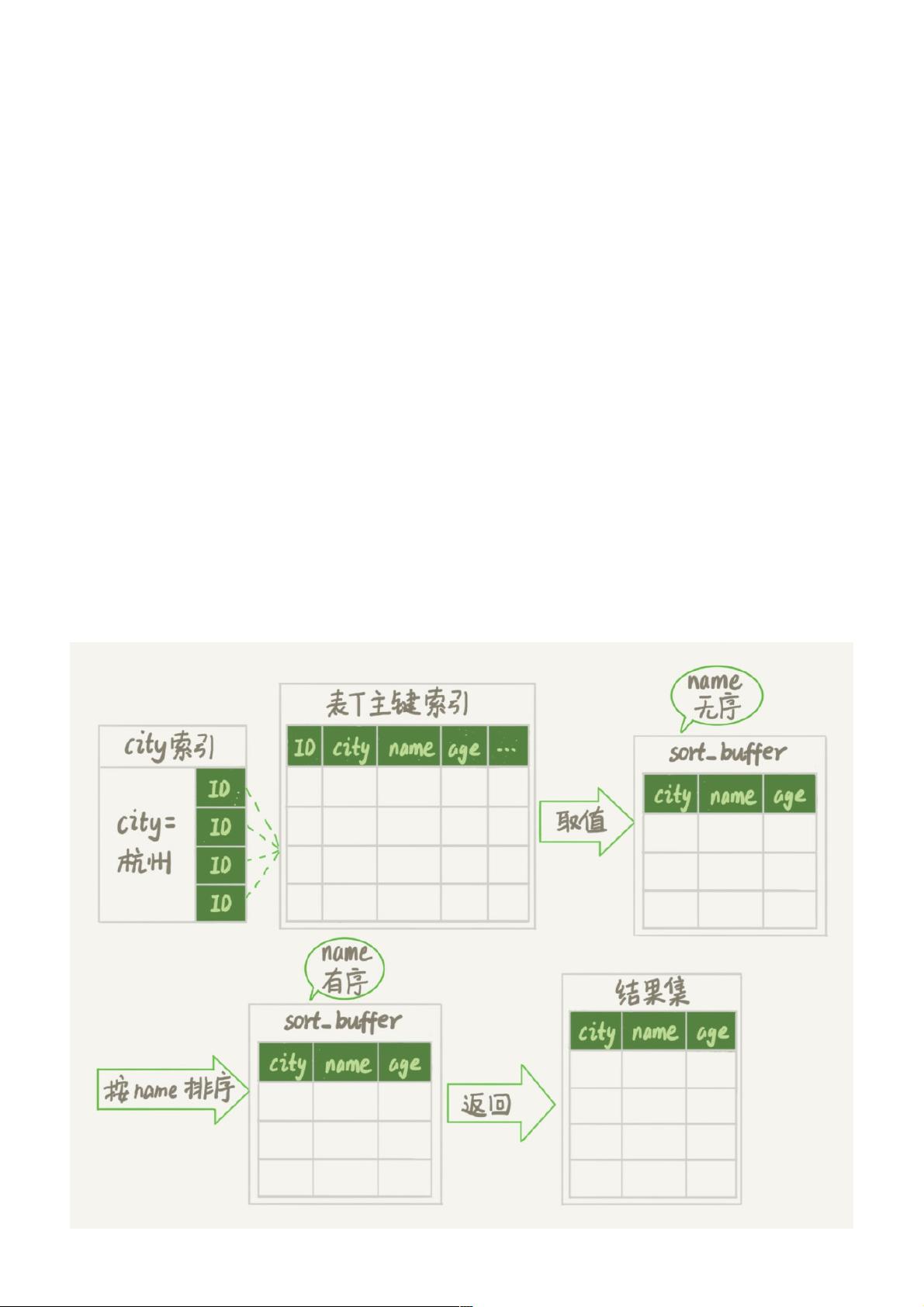
图2 city字段的索引示意图
从图中可以看到,满足city='杭州’条件的行,是从ID_X到ID_(X+N)的这些记录。
通常情况下,这个语句执行流程如下所示 :
1. 初始化sort_buffer,确定放入name、city、age这三个字段;
2. 从索引city找到第一个满足city='杭州’条件的主键id,也就是图中的ID_X;
3. 到主键id索引取出整行,取name、city、age三个字段的值,存入sort_buffer中;
4. 从索引city取下一个记录的主键id;
5. 重复步骤3、4直到city的值不满足查询条件为止,对应的主键id也就是图中的ID_Y;
6. 对sort_buffer中的数据按照字段name做快速排序;
7. 按照排序结果取前1000行返回给客户端。
我们暂且把这个排序过程,称为全字段排序,执行流程的示意图如下所示,下一篇文章中我们还
会用到这个排序。
剩余14页未读,继续阅读
2022-08-03 上传
2022-08-03 上传
2021-09-20 上传
2023-04-29 上传
2023-07-12 上传
2023-06-07 上传
2023-05-26 上传
@foreach (var g1 in Model.DataList.GroupBy(x => x.Ou1).OrderBy(x => x.Key)) { @(g1.Key ?? "-") @foreach (var (g2, i) in g1.GroupBy(x => x.Ou2).OrderBy(x => x.Key).Select((g2, i) => (g2, i))) { if (i != 0) { @: } @(g2.Key ?? "-") foreach(var (item, j) in g2.OrderBy(x => x.Ou3).Select((item, j) => (item, j))) { if(j != 0) { @: } @(item.Ou3 ?? "-") 用JS给第二个标签添加样式 2023-06-08 上传 2023-02-07 上传 2023-05-26 上传  两斤香菜
两斤香菜 -
粉丝: 20
- 资源: 297
 我的内容管理
展开
我的内容管理
展开

最新资源
-
JHU荣誉单变量微积分课程教案介绍
-
Naruto爱好者必备CLI测试应用
-
Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
-
ASP学生信息档案管理系统毕业设计及完整源码
-
Java商城源码解析:酒店管理系统快速开发指南
-
构建可解析文本框:.NET 3.5中实现文本解析与验证
-
Java语言打造任天堂红白机模拟器—nes4j解析
-
基于Hadoop和Hive的网络流量分析工具介绍
-
Unity实现帝国象棋:从游戏到复刻
-
WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
-
Android开源项目精选:优秀项目篇
-
黑色设计商务酷站模板 - 网站构建新选择
-
Rollup插件去除JS文件横幅:横扫许可证头
-
AngularDart中Hammock服务的使用与REST API集成
-
开源AVR编程器:高效、低成本的微控制器编程解决方案
-
Anya Keller 图片组合的开发部署记录
2023-06-08 上传
2023-02-07 上传
2023-05-26 上传
两斤香菜
- 粉丝: 20
- 资源: 297
- 我的内容管理
展开






最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
