华为诺亚方舟实验室:GPT驱动的乐府诗词与对联创作
版权申诉
106 浏览量
更新于2024-07-05
收藏 1.65MB PDF 举报
本研究论文《8-4乐府:预训练语言模型在诗词对联生成中的应用》由华为诺亚方舟实验室的廖亿撰写,主要探讨了大规模预训练语言模型(如GPT)在创作中国传统诗词,特别是对联方面的应用。中文诗歌,尤其是对联,有着严格的格律、平仄和押韵要求,这为模型的生成带来了挑战。传统的生成模型往往受限于这些规则,而GPT系列由于其强大的文本生成能力,能够突破这些限制。
论文首先介绍了中文诗歌对联生成的背景,强调了其格式规范的重要性。GPT作为OpenAI开发的预训练模型,其在大规模中文语料上的预训练使得它具备了生成符合中文诗歌特征的能力。训练过程中,作者使用了30GB的中文文本,构建了一个单向Transformer模型,参数量达到了1.1亿个。
训练流程分为两步:第一步是预训练中文GPT模型,通过大量语料库学习语言的普遍规律;第二步则是利用小规模的古诗词数据进行微调,以便更好地适应诗词的特定风格和格式。具体到五言绝句的“静夜思”例子中,展示了如何将格式、主题等信息转化为模型输入,生成符合要求的诗歌。
论文指出,GPT在诗词生成方面表现出色,不仅能遵循格律和押韵,还能展现出丰富的多样性,甚至在深层的艺术表达上有时能超越人类创作者。生成的诗歌质量高,且能以假乱真,使得识别真伪变得困难。研究还展示了乐府作诗机的成功应用,生成的四首诗歌中有三首实际上是机器生成,表明模型在模拟古人的创作风格上取得了显著成果。
这项研究展示了预训练语言模型在诗词对联生成中的巨大潜力,为自动文学创作提供了新的可能性,并对未来的自然语言生成技术产生了深远影响。
…
…
…
…
…
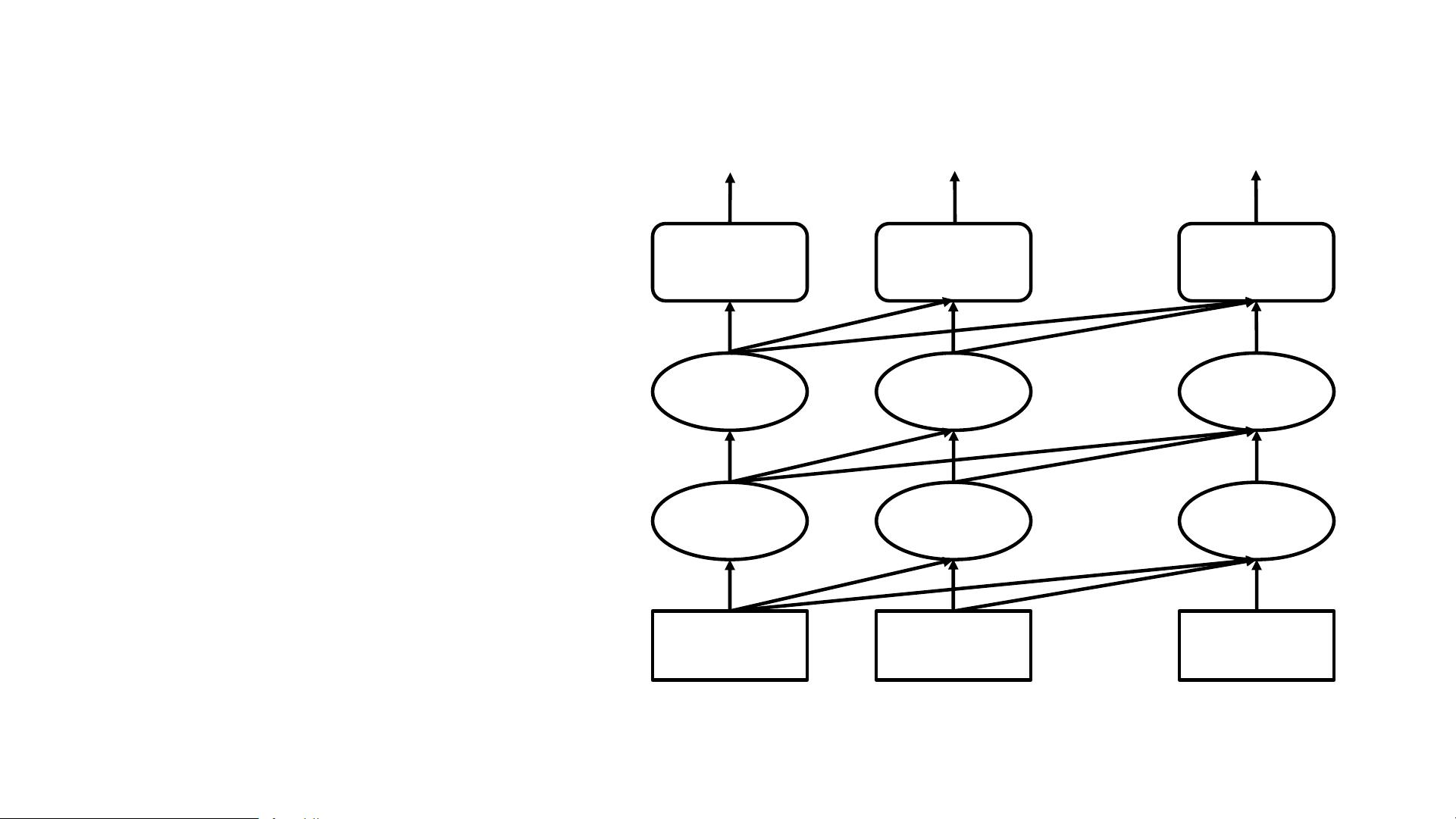
第一步:预训练中文GPT 模型
• 训练语料:30GB 中文文本
• 单向Transformer
• 模型大小:
• Layer=12
• Hidden size= 768
• Intermediate size =3076
• Attention head = 12
• 总参数量:1.1亿
GPT模型结构
剩余26页未读,继续阅读
666 浏览量
2021-03-27 上传
143 浏览量
243 浏览量
149 浏览量
2023-05-26 上传
187 浏览量
163 浏览量
2024-10-05 上传

普通网友
- 粉丝: 13w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- React.js实现的简单HTML5文件拖放上传组件
- iReport:强大的开源可视化报表设计器
- 提升代码整洁性:Eclipse虚线对齐插件指南
- 迷你时间秀:个性化系统时间显示与管理工具
- 使用ruby-install一次性安装多种Ruby版本
- Logality:灵活自定义的JSON日志记录器
- Mogre3D游戏开发实践教程免费分享
- PHP+MySQL实现的简单权限账号管理小程序
- 微信支付统一下单签名错误排查与解决指南
- 虚幻引擎4实现的多边形地图生成器
- TouchJoy:专为触摸屏Windows设备打造的屏幕游戏手柄
- 全方位嵌入式开发工具包:ARM平台必备资源
- Java开发必备:30个实用工具类全解析
- IBM475课程资料深度解析
- Java聊天室程序:全技术栈源码支持与学习指南
- 探索虚拟房屋世界:house-tour-VR应用体验
