BWN技术手册:基于深度学习的语音识别与FPGA加速
需积分: 0 199 浏览量
更新于2024-06-30
收藏 553KB DOCX 举报
"该资源是BWN技术手册的中文版,主要探讨了深度学习在语音识别中的应用,特别是在FPGA可定制逻辑上的运用,以及如何在Matlab2018a平台上实现语音识别的程序。手册提及的数据集来源于谷歌TensorFlow的开源音频库,用于识别六个特定单词的语音片段。核心算法是一个基于语音帧特征图的卷积神经网络(CNN)模型,结合了MFCC预处理技术。"
深度学习在语音识别领域的应用已经成为了一种主流趋势,其中LSTM、RNN和CNN等神经网络模型发挥着关键作用。LSTM(长短期记忆网络)和RNN(循环神经网络)能够处理序列数据,捕捉时间序列中的长期依赖关系,适合于语音信号的时间序列分析。CNN(卷积神经网络)则擅长于提取局部特征,尤其适用于从音频信号中提取频谱特征,进一步提升识别的准确性。这些技术的广泛应用,使得像科大讯飞和百度这样的企业能够实现高质量的实时语音翻译和识别服务。
FPGA(现场可编程门阵列)作为一种可编程的硬件平台,因其可定制化和高效率的特性,成为了深度学习加速的理想选择。相对于CPU,FPGA可以提供更高的并行计算能力,而且在功耗和成本方面相对更优。设计者可以通过硬件描述语言如Verilog HDL来定义电路逻辑,经过仿真、综合和布局步骤,生成比特流文件,最终烧录到FPGA中,实现特定的计算加速任务。尽管FPGA的工作频率可能低于CPU,但其灵活性和效率使其在深度学习的特定计算需求中展现出优势。
运行环境是Matlab2018a,它具备完整的并行计算库和音频处理工具箱,能更好地支持语音识别的计算需求。手册中的程序使用了谷歌TensorFlow的开源音频数据集,这个数据集包含了多个单词的语音片段,每个单词都有多个音频文件和对应的标签。音频预处理采用了MFCC(梅尔频率倒谱系数)技术,将原始音频转换为20维的49帧特征图矩阵,这为CNN模型提供了输入。模型的结构包括两个卷积层和三个全连接层,设计用于识别六个特定的单词标签:'yes', 'up', 'down', 'right', 'left', 'unknown'。
这份BWN手册详细介绍了基于深度学习的语音识别系统,包括技术背景、硬件加速策略、运行平台选择以及具体的实现流程,为读者提供了全面的理解和实践指导。
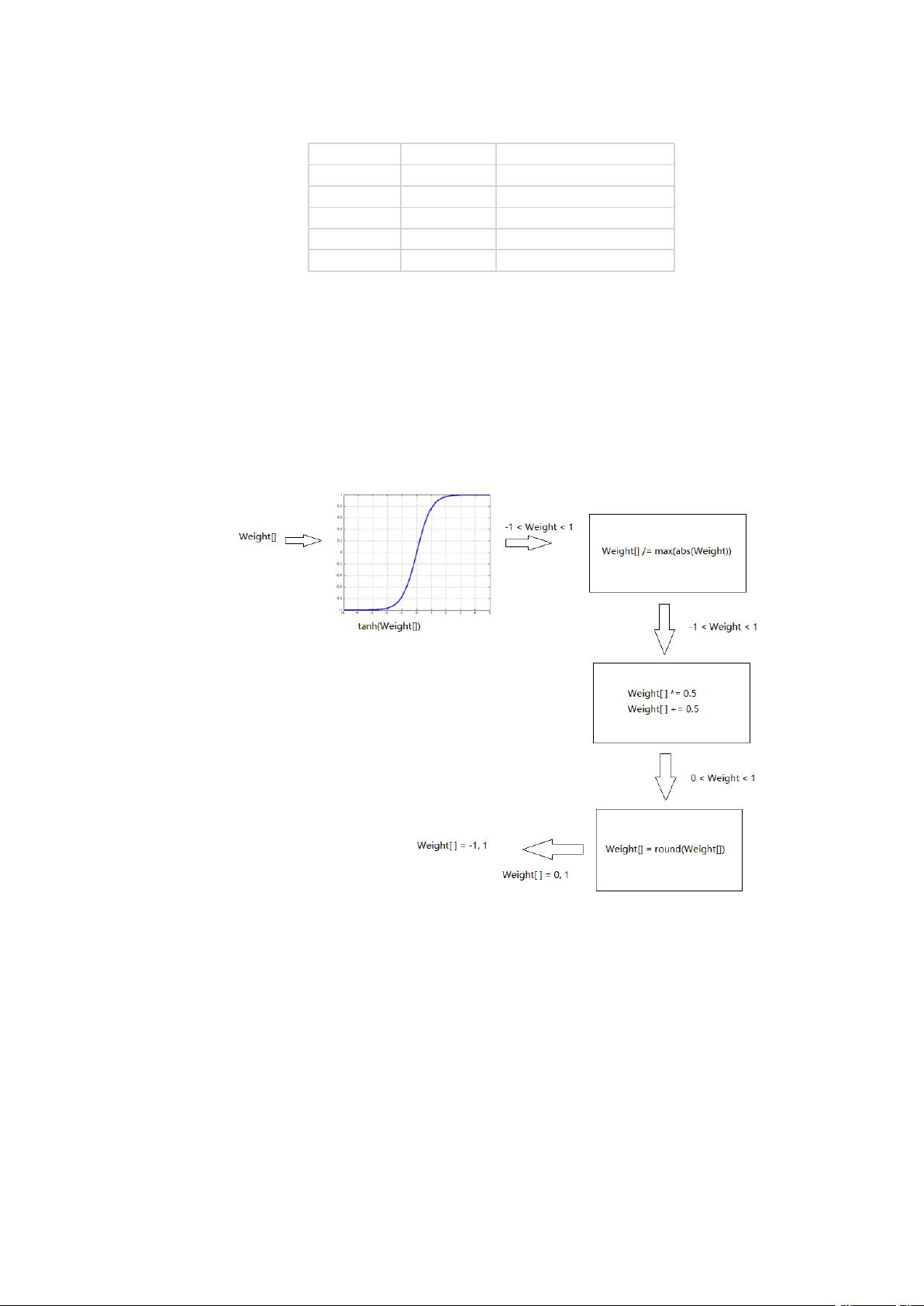
因此从上述两方面考虑,该模型还需要进行量化处理。
表 1
2.3 网络量化
为了解决上述问题,本设计使用两种量化方法优化算法原型:(1)权值的二值化;
(2)激活值的定点化。
本设计将网络中的以浮点数格式表示的原始权值通过一系列处理(具体流程见图 3)
转化为表示值为+1, -1 的二值数据。二值化的数据在硬件上可以通过一个二进制位的 01
状态来储存,即一个 64 位浮点权值在二值量化后只需一个比特位就可存储,大大减少
了模型参数的存储需求。二值化后输出的权值形如图 4.
图 3
层数 参数量 参数大小(float64)(Byte)
卷积层1 288 2304
卷积层2 9216 73728
全连接层1 737280 5898240
全连接层2 1024 8192
全连接层3 192 1536
剩余14页未读,继续阅读
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2018-10-14 上传
2022-03-14 上传
2021-10-12 上传
2021-10-13 上传

H等等H
- 粉丝: 43
- 资源: 337
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
