利用Hadoop+Nutch+Solr优化分布式搜索引擎
72 浏览量
更新于2024-06-22
收藏 686KB DOCX 举报
"大数据技术文档样本.docx"
本文档主要探讨了大数据技术在应对信息爆炸时代挑战中的作用,特别是在搜索引擎优化方面。文档指出,随着互联网的快速发展,数据量急剧增长,传统的信息检索方式已经无法满足需求。因此,转向分布式处理能力更强的系统成为必然趋势。系统选择了hadoop作为基础,结合nutch和solr来提升搜索引擎的性能。
hadoop作为分布式处理框架,具备高效的数据处理能力,尤其在大规模数据集上,相比单机系统能显著节省时间。此外,hadoop的高扩展性允许通过增加集群节点来适应不断增长的数据量,同时保持系统的稳定性和安全性。其内置的数据冗余机制可以防止数据丢失,确保服务的连续性。
nutch是一个开放源代码的网络爬虫,不仅能够抓取网页,还能解析网页、建立链接数据库、评分网页以及生成solr索引。nutch的插件机制增强了系统的可扩展性、灵活性和可维护性,开发者可以根据特定需求定制抓取和解析规则,提高系统对用户的适应性。
solr则作为一个强大的全文搜索引擎,通过分布式索引实现并行处理,加速检索速度。它支持基于主题的索引和查询,增强了搜索引擎的相关性。
研究目标聚焦于分布式搜索引擎的深入分析和索引构建策略的优化。具体包括对hadoop分布式平台(如HDFS和MapReduce)的详尽研究,以及对Nutch架构、插件系统(尤其是协议插件、URL过滤和信息解析插件)的深入探讨,以提升搜索结果的相关度。此外,还将涉及使用MapReduce实现Google的排序算法,以改进系统的关联度性能。
系统功能结构设计包含两大部分:一是本地资源解析模块,负责对PDF、Word、Excel等本地文件的内容进行解析和索引,按主题分类后纳入搜索范围;二是搜索模块,允许用户根据不同主题进行索引查询,并返回与查询内容最相关的结果。
这份文档详细阐述了如何利用hadoop、nutch和solr构建一个高效的分布式搜索引擎,以解决大数据环境下信息检索的难题,同时也指出了研究的主要方向和系统设计的关键点。
资料内容仅供您学习参考,如有不当之处,请联系改正或者删除。
MapReduce 编程模型
MapReduce 是一种编程模型, 该模型将数据扩展到多个数据节点上进
行处理, 它最早是 Google 提出的一个软件架构, 用于大规模数据集( 大
于 1TB) 的并行运算。并行编程模式的最大优点是容易扩展到多个计算节
点上处理数据。开发者能够很容易就编写出分布式并行程序。
mapreduce 的主要思想是将自动分割要执行的问题( 例如程序) 拆解
成 map( 映射) 和 reduce( 化简) 的方式; 一个 MapReduce 作业( job)
首先会把输入的数据集分割为多个独立的数据块, 再以键值对形式输给
Map 函数并行处理。Map 函数接受一个输入键值正确值, 产生一个中间键
值对集合, 由 MapReduce 保存并集合所有具有相同中间 key 值的中间
value 值传递给 Reduce 函数, reduce 对这些 value 值进行合并, 形成一
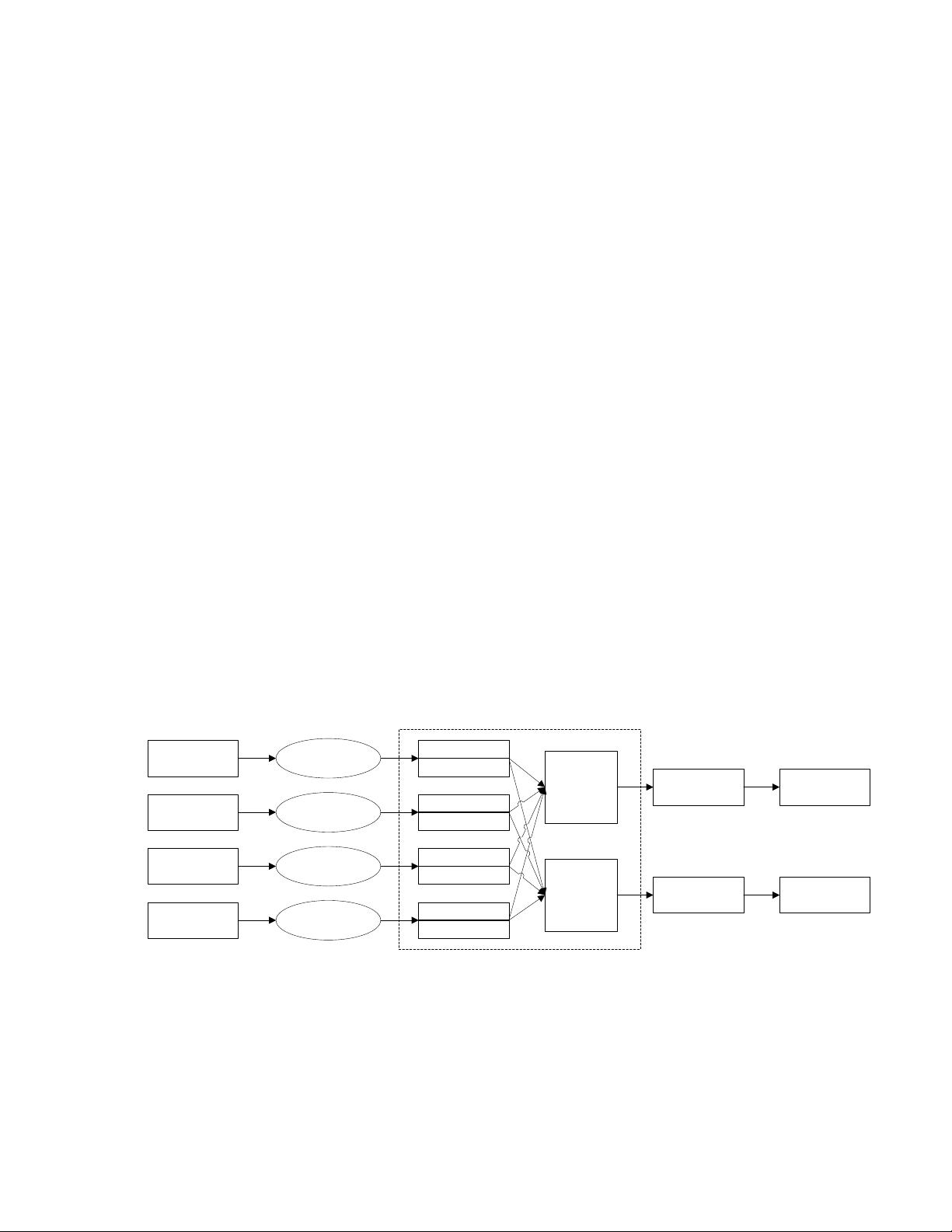
个 value 值集合, 最终形成输出数据。 处理流程如下图:
数据块1
数据块2
数据块3
数据块4
Map()
Map()
Map()
Map()
K1,list(vl,v3
,v5,v7)
K2,list(v2,v4
,v6,v8)
Reduce()
Reduce()
K1,v9
K2,v10
输入
Map任务
K1,v1
K2,v2
K1,v3
K2,v4
K1,v5
K2,v6
K1,v7
K2,v8
中间结果
Reduce任务
输出
MapReduce 的处理流程

剩余47页未读,继续阅读
2022-06-21 上传
2022-12-24 上传
2022-12-24 上传
2022-06-21 上传
2022-01-26 上传
2022-12-24 上传
2022-06-21 上传

yyyyyyhhh222
- 粉丝: 452
- 资源: 6万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
