数据挖掘十大经典算法详解:C4.5与深度解析
需积分: 9 198 浏览量
更新于2024-09-11
收藏 19KB DOCX 举报
在数据挖掘领域,算法的重要性不言而喻,本文将深入探讨国际权威组织ICDM于2006年评选出的十大经典算法,这些算法在数据挖掘实践中具有广泛的应用和影响力。以下是其中的详细介绍:
1. **C4.5** - 作为决策树算法的一种,C4.5是对ID3算法的改进,它利用信息增益率而非简单的信息增益来选择最优属性进行划分。信息增益率考虑了属性选择对不确定性的影响,并通过调整比例平衡来更精确地确定最佳特征。C4.5的决策树构造过程基于每次选择最优的特征和分裂点,使得模型更加稳健。
2. **k-Means** - 这是一种无监督聚类算法,用于将数据集划分为多个互不重叠的类别,每个类别内的数据点相似度最高。k-Means通过迭代的方式不断调整每个类别中心(质心)的位置,直到达到预定的收敛条件。
3. **支持向量机(SVM)** - SVM是一种强大的分类器,尤其在高维空间中表现优异。它通过构建最大间隔超平面来进行分类,能有效处理非线性问题,通过核函数映射数据到高维空间。
4. **Apriori** - Apriori算法是关联规则学习的基础,用于发现频繁项集和关联规则,常用于市场篮子分析和推荐系统中。
5. ** Expectation-Maximization (EM)算法** - EM是隐马尔可夫模型(HMM)中的优化算法,用于参数估计,特别适用于处理带有缺失数据的问题,例如在自然语言处理和生物信息学中的序列数据分析。
6. **PageRank** - 由Google开发,是网页排名算法的核心,它通过计算网页之间的链接权重来评估网页的重要性,对搜索引擎排名有重大影响。
7. **AdaBoost** - 这是一种集成学习方法,通过结合多个弱分类器形成强分类器,提高整体性能。AdaBoost特别强调那些难分类样本,对噪声数据有较好的鲁棒性。
8. **k-近邻(kNN)** - kNN算法是基于实例的学习,通过寻找最近邻居进行预测,简单易用,但对数据存储和计算量要求较高。
9. **朴素贝叶斯(Naive Bayes)** - 基于贝叶斯定理,假设特征之间相互独立,适用于文本分类和垃圾邮件过滤等场景,具有高效的预测速度。
10. **CART (Classification and Regression Trees)** - CART是另一种决策树算法,不仅可以进行分类,还能进行回归分析,具有灵活性和直观性。
每种算法都有其独特的优点和适用场景,理解并熟练运用这些经典算法,有助于提升数据挖掘项目的效率和准确性。对于想进一步研究数据挖掘的人来说,深入理解这些算法背后的原理和优化策略是至关重要的。博主强调,尽管文章翻译参考了一些已有的资源,但力求提供权威且详细的解读,以帮助读者在实际应用中更好地掌握和应用这些算法。
数据挖掘领域十大经典算法初探
分类:02.Algorithms (后续) 30.Machine L&Data Mining2011-01-15 15:3136163 人阅读评论(47)收藏举报
算法数据挖掘classificationalgorithmvectorgoogle
数据挖掘领域十大经典算法初探
译者:July二零一一年一月十五日
-----------------------------------------
参考文献:
国际权威的学术组织 ICDM,于 06 年 12 月年评选出的数据挖掘领域的十大经典算法:
C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART.
==============
博主说明:
1、原文献非最新文章,只是本人向来对算法比较敏感、感兴趣,便把原文细看了下,
翻译过程中,有参考一些网友翻译的文章,但个人认为,阐述皆不够精准,且都是泛泛而谈,
故此,做了此份翻译,希望,为读者提供一个较权威而详细的文档资料。
2、同时,也可于闲余之际择其一二好好研究、剖析下此数据挖掘领域的十大经典算法。
文中,添加了一些个人自己的理解,请自行辨明。
---------------------------------------------------------------------
以下就是从参加评选的 18 种候选算法中,最终决选出来的十大经典算法:
一、C4.5
C4.5,是机器学习算法中的一个分类决策树算法,
它是决策树(决策树也就是做决策的节点间的组织方式像一棵树,其实是一个倒树)核心算法
ID3 的改进算法,所以基本上了解了一半决策树构造方法就能构造它。
决策树构造方法其实就是每次选择一个好的特征以及分裂点作为当前节点的分类条件。
C4.5 相比于 ID3 改进的地方有:
1、用信息增益率来选择属性。
ID3 选择属性用的是子树的信息增益,这里可以用很多方法来定义信息,ID3 使用的是熵(entropy,
熵是一种不纯度度量准则),
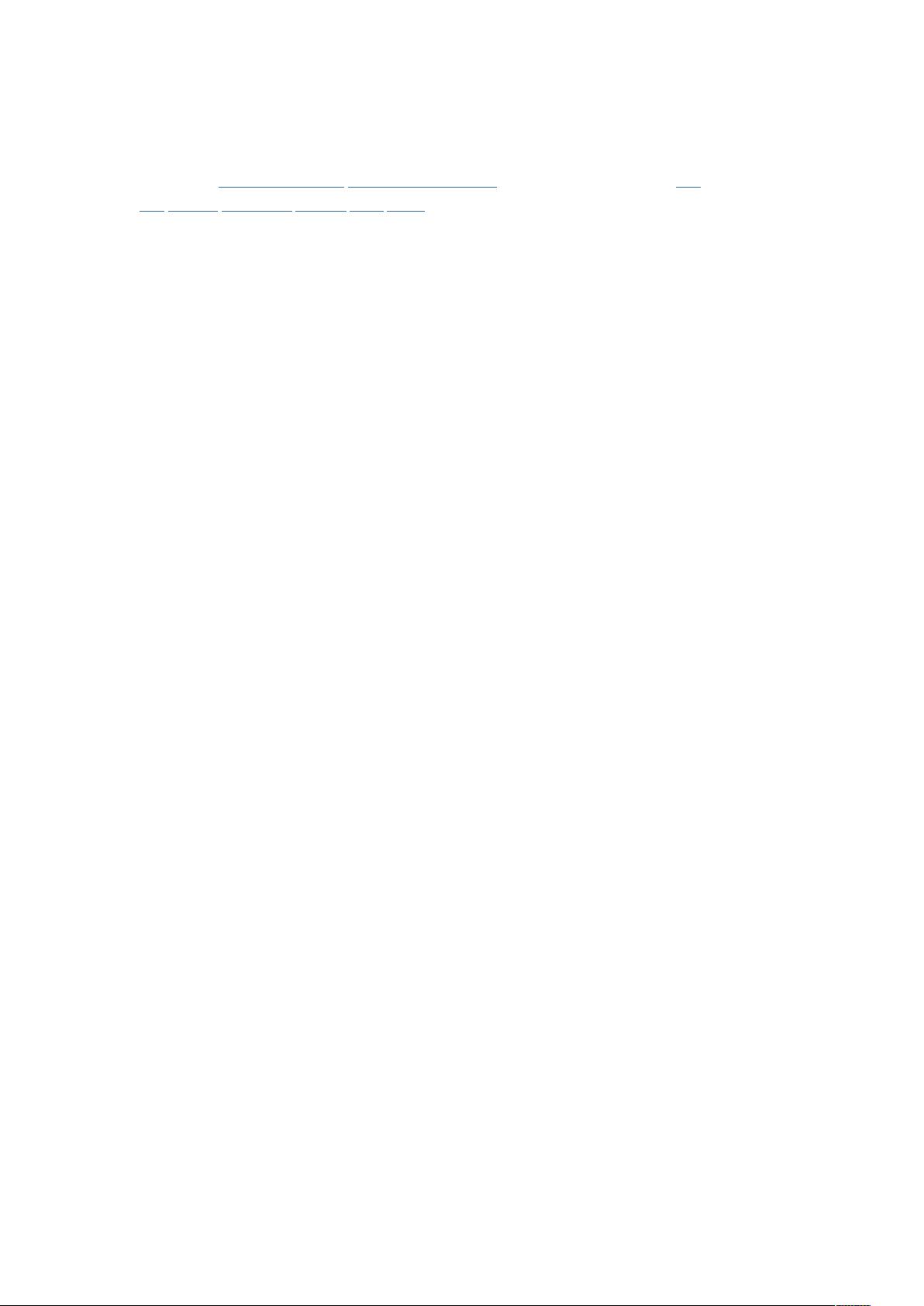
也就是熵的变化值.
而 C4.5 用的是信息增益率。对,区别就在于一个是信息增益,一个是信息增益率。
一般来说率就是用来取平衡用的,就像方差起的作用差不多,
比如有两个跑步的人,一个起点是 10m/s 的人、其 10s 后为 20m/s;
另一个人起速是 1m/s、其 1s 后为 2m/s。
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-04-23 上传
2021-07-14 上传
2021-07-14 上传
2021-07-14 上传
2021-07-14 上传
2021-06-13 上传

eric_sadan
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chrome ESLint扩展:实时运行ESLint于网页脚本
- 基于 Webhook 的 redux 预处理器实现教程
- 探索国际CMS内容管理系统v1.1的新功能与应用
- 在Heroku上快速部署Directus平台的指南
- Folks Who Code官网:打造安全友好的开源环境
- React测试专用:上下文提供者组件实现指南
- RabbitMQ利用eLevelDB后端实现高效消息索引
- JavaScript双向对象引用的极简实现教程
- Bazel 0.18.1版本发布,Windows平台构建工具优化
- electron-notification-desktop:电子应用桌面通知解决方案
- 天津理工操作系统实验报告:进程与存储器管理
- 掌握webpack动态热模块替换的实现技巧
- 恶意软件ep_kaput: Etherpad插件系统破坏者
- Java实现Opus音频解码器jopus库的应用与介绍
- QString库:C语言中的高效动态字符串处理
- 微信小程序图像识别与AI功能实现源码
