AP聚类算法详解:从分类到无监督学习的探索
需积分: 0 110 浏览量
更新于2024-08-05
收藏 484KB PDF 举报
在IT领域中,AP聚类算法是一种用于数据挖掘的重要工具,它涉及到两种主要的分析方法:分类和聚类。分类与聚类是数据分析的两个关键步骤,它们在处理数据时有着不同的目标和应用场景。
1. 分类算法:这是一种机器学习技术,其目标是通过训练数据建立模型,以便对新的、未知的数据进行预测,将其归入预定义的类别。分类算法通常包括以下几个步骤:首先,使用训练集(包含特征向量和类别标签)进行特征选择,然后训练模型(如决策树、KNN、SVM、VSM、贝叶斯或神经网络等),最后对新样本应用特征提取并进行分类。分类的主要目的是了解数据的内在结构和规律,从而对未来数据进行精确的预测。
2. 聚类算法:相比之下,聚类是无监督学习方法,它不预先设定类别,而是自动寻找数据内部的自然分群。聚类的目标是发现数据的潜在结构,将相似的对象聚集在一起形成簇,同时保持簇内的紧密度和簇间的差异性。常见的聚类算法类型包括:划分法(如K-means和K-centers)、层次法(如层次聚类)、密度为基础的方法(如DBSCAN)、网格方法(如Grid-based clustering)以及模型驱动的方法(如Gaussian Mixture Models)。聚类分析的结果是对数据的一种直观理解,有助于洞察数据的自然组织和模式。
分类与聚类之间的区别在于,分类是有监督的学习,需要预先知道每个样本的类别标签,而聚类则是无监督的,不依赖于事先提供的类别信息。分类侧重于预测,聚类更关注数据的结构发现。在实际应用中,这两种方法常常结合使用,例如在市场细分中,先通过聚类分析识别用户群体,再通过分类算法为每个群体定制个性化服务。
AP聚类算法作为一项基础技术,在数据分析和挖掘中扮演着至关重要的角色,它帮助人们理解和组织数据,从而支持决策制定和业务优化。熟练掌握这些算法对于IT专业人士来说,无论是数据科学家、机器学习工程师还是数据分析师,都是一项必不可少的技能。通过深入研究和实践,我们可以更好地利用这些工具在复杂的数据环境中提取有价值的信息。
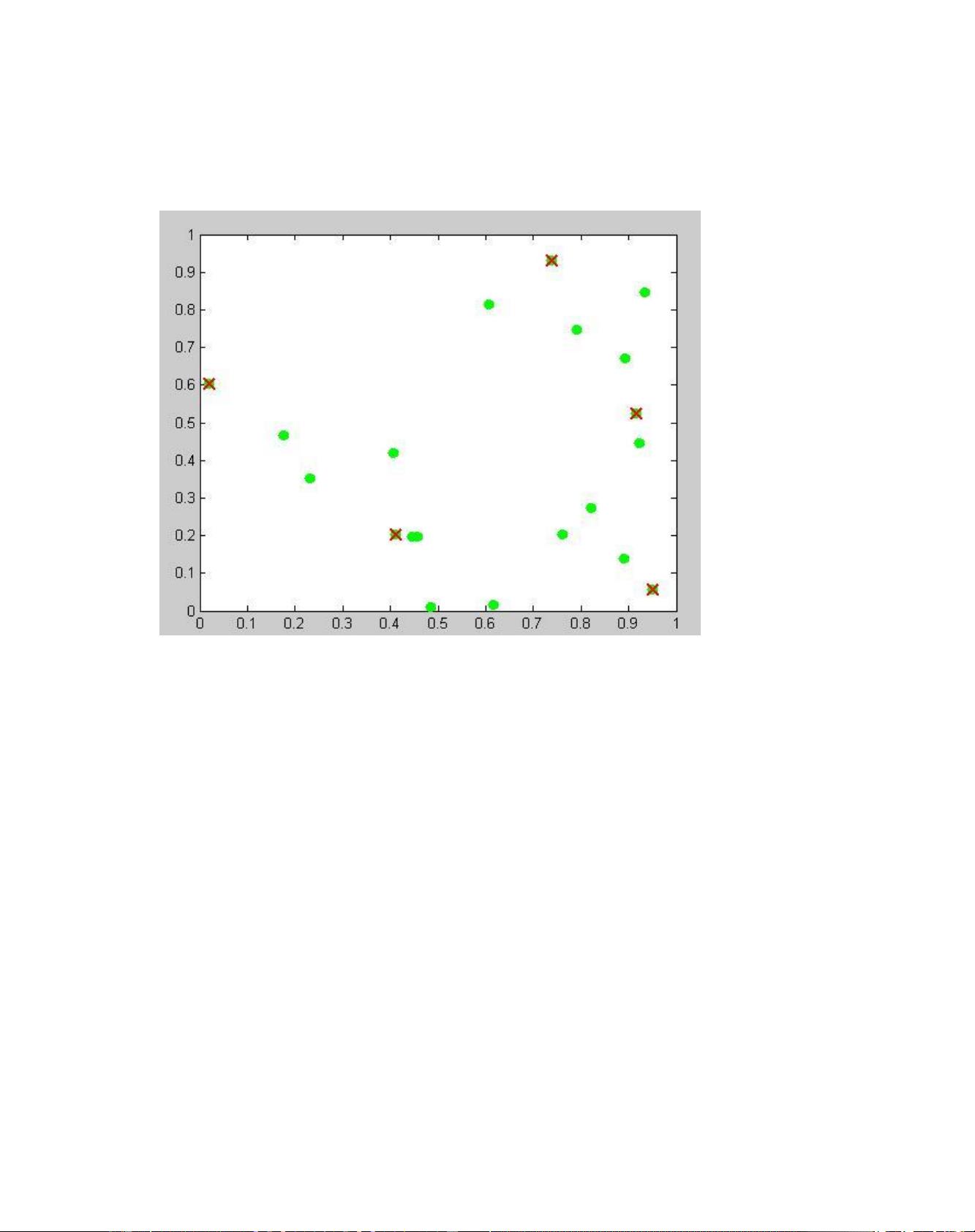
例 1:我们在二维空间中随机的生成 20 个数据点,将聚类数目指定为 5 个,并
随机生成一个聚类中心(用“×”来标注),根据对象与簇中心的距离,每个对象分成
于最近的簇。初始示例图如下:
图 1.随机生成的数据点及初始聚类中心示例图
下一步,更新簇中心。也就是说,根据簇中的当前对象,重新计算每个簇的
均值。使用这些新的簇中心,将对象重新分成到簇中心最近的簇中。
不断迭代上面的过程,直到簇中对象的重新分布不再发生,处理结束。最终
的聚类结果示例图如下:
剩余11页未读,继续阅读
2022-07-15 上传
2021-10-06 上传
2022-07-13 上传
2022-09-22 上传
2016-03-28 上传
2023-03-11 上传
2023-03-11 上传
2023-03-11 上传

实在想不出来了
- 粉丝: 36
- 资源: 318
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
