Google MapReduce框架下的分布式计算解析
版权申诉
"这篇文档是关于分布式计算的毕业设计,主要探讨了Google的MapReduce框架在Hadoop中的应用。MapReduce是一种处理大规模数据集的编程模型,它将复杂的分布式计算任务简化为两个主要阶段:Map和Reduce。在Map阶段,输入数据被分割成多个部分,每个部分在不同的机器上并行处理,生成中间结果;在Reduce阶段,这些中间结果被汇总以产生最终的输出。这种框架特别适合处理和存储大量分布式的数据。文档中还可能涉及了MapReduce的相关术语和基本架构,包括作业服务器(JobTracker)的角色,以及如何在集群中协调和执行任务。"
在分布式计算领域,MapReduce是一种重要的计算模型,由Google提出并广泛应用于大数据处理。它将复杂的数据处理任务分解为两个可并行执行的简单函数:Map和Reduce。Map阶段将原始输入数据拆分为键值对,并在多台机器上并行地应用用户定义的映射函数,生成中间结果。这个过程允许数据在分布式环境中本地处理,减少了网络传输的负担,提高了效率。
Reduce阶段则负责收集Map阶段产生的中间结果,并通过聚合操作整合这些数据,生成最终的输出。这个阶段通常用于汇总、聚合或过滤数据,确保整个计算过程的正确性和完整性。在Hadoop中,JobTracker(在新的Hadoop版本中被YARN取代)是关键组件,它负责调度作业,监控任务进度,以及在集群中分配Map和Reduce任务。
MapReduce的设计理念在于容错性和可伸缩性。即使在部分节点故障的情况下,系统也能通过数据复制和任务重试来保证作业的顺利完成。此外,由于数据和计算可以分布在整个集群上,MapReduce能够处理PB级别的数据,非常适合于大数据分析、搜索引擎索引构建等场景。
在理解MapReduce时,需要关注几个核心概念:作业(Job)、任务(Task)、槽位(Slot)以及Shuffle和Sort阶段。作业是用户提交的完整计算请求,可以被拆分为多个Map和Reduce任务。槽位是集群中工作节点(TaskTracker)可用的计算资源,用于执行Map或Reduce任务。Shuffle阶段是Reduce任务的一部分,它负责整理Map阶段产生的中间数据,按键排序,以便于Reduce函数处理;Sort则是为了保证相同键的数据在一起,便于归约操作。
此外,文档中提到的术语对照表可能列举了Google、Hadoop和其他相关系统中对于MapReduce概念的不同称呼,以帮助理解和对比。而基本架构部分则可能详细介绍了JobTracker、TaskTracker(在Hadoop中)以及其他组成部分的工作原理,阐述了它们如何协同完成MapReduce作业的调度和执行。
MapReduce是分布式计算领域的重要工具,它提供了一种简单而强大的方式来处理大规模的数据。这篇毕业设计论文深入探讨了这一框架,包括其原理、实现和在Hadoop中的应用,对于理解大数据处理和分布式计算有着极高的价值。
分布式计算(Map/Reduce)
分布式式计算,同样是一个宽泛的概念,在这里,它狭义的指代,按 Google Map/Reduce 框
架所设计的分布式框架。在 Hadoop 中,分布式文件系统,很大程度上,是为各种分布式计算
需求所服务的。我们说分布式文件系统就是加了分布式的文件系统,类似的定义推广到分布式计
算上,我们可以将其视为增加了分布式支持的计算函数。从计算的角度上看,Map/Reduce 框
架接受各种格式的键值对文件作为输入,读取计算后,最终生成自定义格式的输出文件。而从分
布式的角度上看,分布式计算的输入文件往往规模巨大,且分布在多个机器上,单机计算完全不
可支撑且效率低下,因此 Map/Reduce 框架需要提供一套机制,将此计算扩展到无限规模的机
器集群上进行。依照这样的定义,我们对整个 Map/Reduce 的理解,也可以分别沿着这两个流
程去看。。。
在 Map/Reduce 框架中,每一次计算请求,被称为作业。在分布式计算 Map/Reduce 框架中,
为了完成这个作业,它进行两步走的战略,首先是将其拆分成若干个 Map 任务,分配到不同的
机器上去执行,每一个 Map 任务拿输入文件的一部分作为自己的输入,经过一些计算,生成某
种格式的中间文件,这种格式,与最终所需的文件格式完全一致,但是仅仅包含一部分数据。因
此,等到所有 Map 任务完成后,它会进入下一个步骤,用以合并这些中间文件获得最后的输出
文件。此时,系统会生成若干个 Reduce 任务,同样也是分配到不同的机器去执行,它的目标,
就是将若干个 Map 任务生成的中间文件为汇总到最后的输出文件中去。当然,这个汇总不总会
像 1 + 1 = 2 那么直接了当,这也就是 Reduce 任务的价值所在。经过如上步骤,最终,作业
完成,所需的目标文件生成。整个算法的关键,就在于增加了一个中间文件生成的流程,大大提
高了灵活性,使其分布式扩展性得到了保证。。。
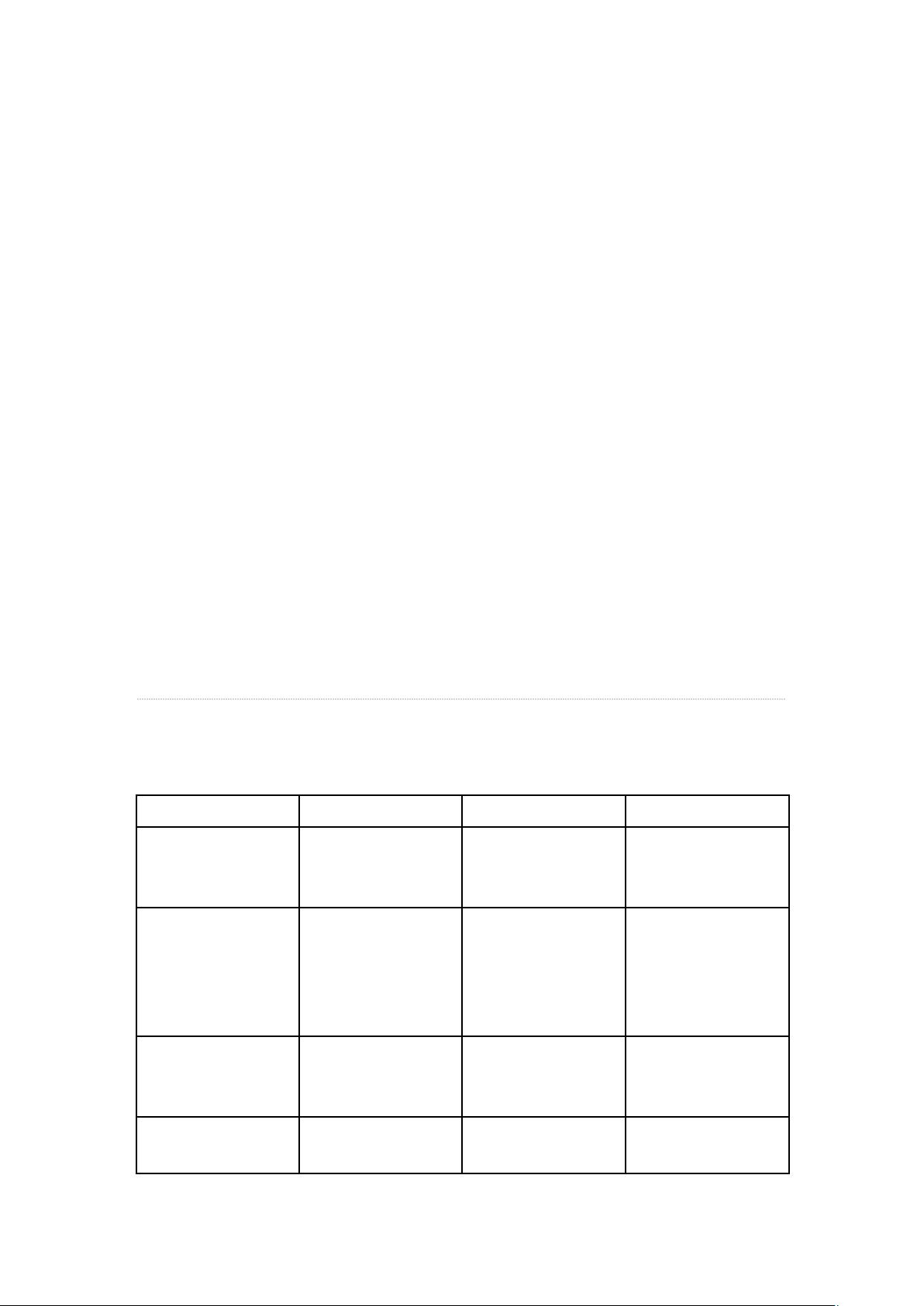
I. 术语对照
和分布式文件系统一样,Google、Hadoop 和....我,各执一种方式表述统一概念,为了保证其
统一性,特有下表。。。
文中翻译
Hadoop 术语
Google 术语
相关解释
作业
Job
Job
用户的每一个计算
请求,就称为一个
作业。
作业服务器
JobTracker
Master
用户提交作业的服
务器,同时,它还
负责各个作业任务
的分配,管理所有
的任务服务器。
任务服务器
TaskTracker
Worker
任劳任怨的工蜂,
负责执行具体的任
务。
任务
Task
Task
每一个作业,都需
要拆分开了,交由
下载后可阅读完整内容,剩余9页未读,立即下载
2019-06-18 上传
2022-07-11 上传
2019-11-03 上传
2021-02-17 上传
2019-11-24 上传
2024-05-17 上传
2024-05-24 上传
2020-10-10 上传
2022-06-17 上传

小小哭包
- 粉丝: 1934
- 资源: 4081
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
