水平分库分表策略与挑战:从规则选择到实践解析
200 浏览量
更新于2024-08-31
收藏 232KB PDF 举报
在IT行业中,水平分库分表是一种常见的技术手段,用于应对关系型数据库在面对海量数据和高并发访问时的性能瓶颈。水平分库(也称作Sharding或分片)通过将数据分布在多个独立的数据库服务器上,实现了系统的横向扩展,提高系统的并发处理能力和存储容量。
关键步骤:
1. 理解分片基础:首先,要理解数据库的性能限制,包括存储容量、连接数和处理能力,以及数据库的“有状态性”使得它不易于扩展。技术人员在此背景下提出分库分表,以应对互联网业务的需求。
2. 避免全局唯一ID冲突:在分库环境下,不能依赖数据库自增ID生成主键,因为这可能导致不同分片间的ID重复。常用的ID生成算法包括Twitter的Snowflake、UUID/GUID、MongoDBObjectID和TicketServer,如Snowflake通过时间戳、机器码和计数器生成唯一的64位ID。
3. 选择合适的分片字段:确定分片字段(片键),通常基于频繁使用的或重要的业务字段,例如用户ID或时间戳。通过SQL语句分析可以更好地决策。
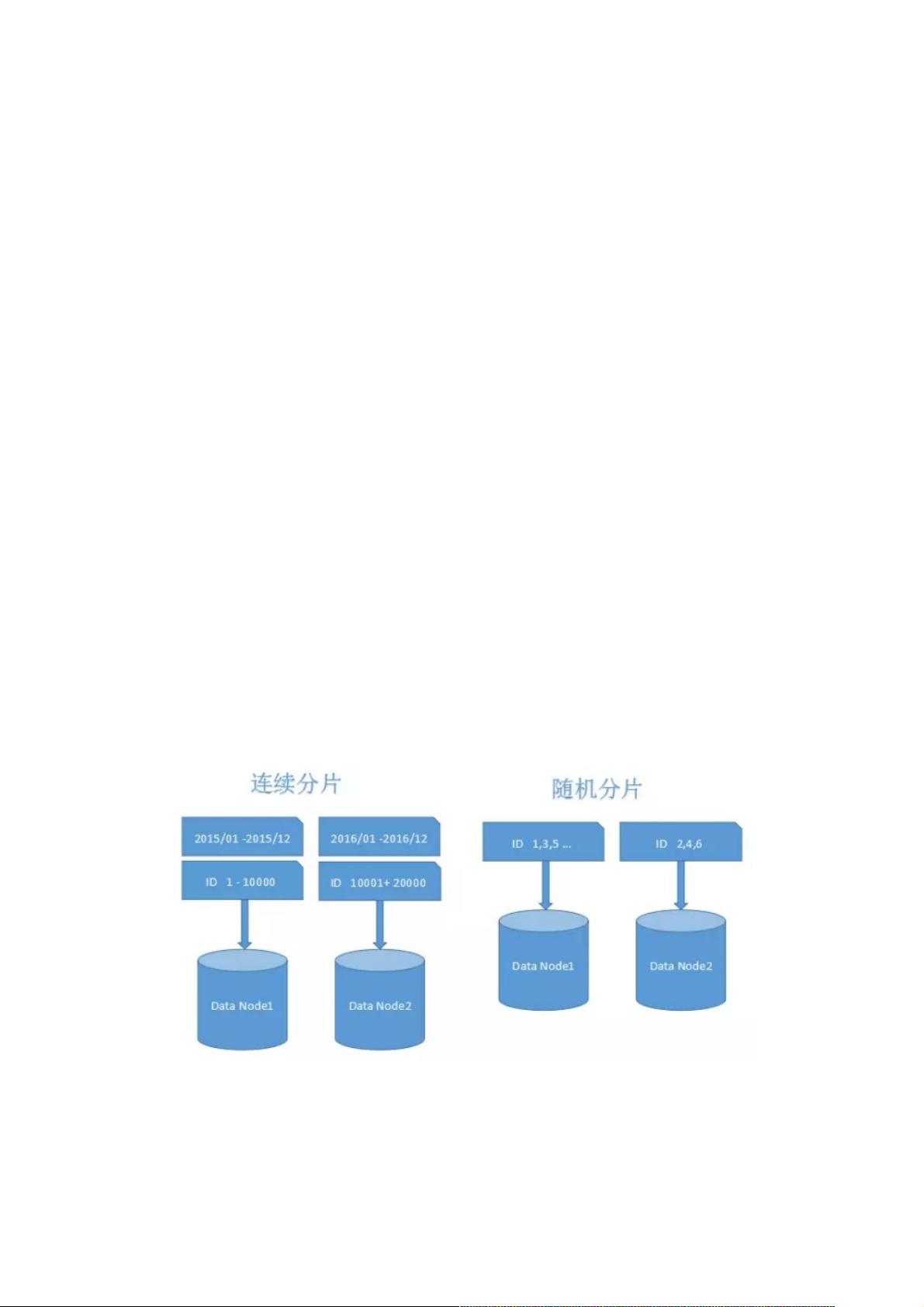
4. 制定分片规则:常见的分片策略有随机分片和连续分片。随机分片适用于无特定顺序的数据,而连续分片有利于范围查找,但可能需要考虑后续扩容时的便捷性,可能涉及数据迁移问题。
5. 实施和监控:在实际操作中,需要设计合理的路由算法,确保数据的正确分布,并持续监控系统的性能,以便及时调整分片策略。
可能遇到的问题:
- 数据一致性挑战:分片可能会增加跨分片查询的复杂性,对数据一致性管理带来挑战,需要借助复制、事务管理和分布式事务解决方案。
- 路由与负载均衡:如何高效地将请求路由到正确的分片是关键,这涉及到数据分片、路由算法以及负载均衡的设计。
- 维护与扩展:随着业务的增长,可能需要动态调整分片数量,这时需要考虑如何平滑地添加或删除分片,同时保证服务的稳定性。
- 数据冗余:在某些情况下,为了保证查询效率,可能会牺牲部分数据冗余,需要权衡数据一致性和性能之间的平衡。
总结来说,水平分库分表是一个涉及业务理解、技术选型和系统运维的复杂过程,需要根据具体业务需求和系统架构精心设计和优化。
水平分库分表的关键步骤以及可能遇到的问题水平分库分表的关键步骤以及可能遇到的问题
在之前的文章中,我介绍了分库分表的几种表现形式和玩法,也重点介绍了垂直分库所带来的问题和解决方法。本篇中,我们
将继续聊聊水平分库分表的一些技巧。
分片技术的由来
关系型数据库本身比较容易成为系统性能瓶颈,单机存储容量、连接数、处理能力等都很有限,数据库本身的“有状态性”导致
了它并不像Web和应用服务器那么容易扩展。在互联网行业海量数据和高并发访问的考验下,聪明的技术人员提出了分库分
表技术(有些地方也称为Sharding、分片)。同时,流行的分布式系统中间件(例如MongoDB、ElasticSearch等)均自身友
好支持Sharding,其原理和思想都是大同小异的。
分布式全局唯一ID
在很多中小项目中,我们往往直接使用数据库自增特性来生成主键ID,这样确实比较简单。而在分库分表的环境中,数据分布
在不同的分片上,不能再借助数据库自增长特性直接生成,否则会造成不同分片上的数据表主键会重复。简单介绍下使用和了
解过的几种ID生成算法。
Twitter的Snowflake(又名“雪花算法”)
UUID/GUID(一般应用程序和数据库均支持)
MongoDB ObjectID(类似UUID的方式)
Ticket Server(数据库生存方式,Flickr采用的就是这种方式)
其中,Twitter 的Snowflake算法是笔者近几年在分布式系统项目中使用最多的,未发现重复或并发的问题。该算法生成的是64
位唯一Id(由41位的timestamp+ 10位自定义的机器码+ 13位累加计数器组成)。这里不做过多介绍,感兴趣的读者可自行查
阅相关资料。
常见分片规则和策略
分片字段该如何选择
在开始分片之前,我们首先要确定分片字段(也可称为“片键”)。很多常见的例子和场景中是采用ID或者时间字段进行拆分。
这也并不绝对的,我的建议是结合实际业务,通过对系统中执行的sql语句进行统计分析,选择出需要分片的那个表中最频繁
被使用,或者最重要的字段来作为分片字段。
常见分片规则
常见的分片策略有随机分片和连续分片这两种,如下图所示:
当需要使用分片字段进行范围查找时,连续分片可以快速定位分片进行高效查询,大多数情况下可以有效避免跨分片查询的问
题。后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移。但是,连续分片也有可能存
在数据热点的问题,就像图中按时间字段分片的例子,有些节点可能会被频繁查询压力较大,热数据节点就成为了整个集群的
瓶颈。而有些节点可能存的是历史数据,很少需要被查询到。
随机分片其实并不是随机的,也遵循一定规则。通常,我们会采用Hash取模的方式进行分片拆分,所以有些时候也被称为离
散分片。随机分片的数据相对比较均匀,不容易出现热点和并发访问的瓶颈。但是,后期分片集群扩容起来需要迁移旧的数
据。使用一致性Hash算法能够很大程度的避免这个问题,所以很多中间件的分片集群都会采用一致性Hash算法。离散分片也
很容易面临跨分片查询的复杂问题。
下载后可阅读完整内容,剩余4页未读,立即下载
2360 浏览量
点击了解资源详情
212 浏览量
413 浏览量
812 浏览量
点击了解资源详情
172 浏览量
144 浏览量
点击了解资源详情

weixin_38705558
- 粉丝: 4
- 资源: 943
 我的内容管理
展开
我的内容管理
展开







