密度峰值法:高效聚类的算法利器
需积分: 13 93 浏览量
更新于2024-07-20
收藏 9.86MB PDF 举报
在信息技术领域,"快速高效的聚类方法"是一个关键的主题,特别是在数据挖掘和机器学习中。聚类是一种无监督学习技术,用于将一组数据对象分成自然形成或有意义的组,这些组内部的数据相似度较高,而组间差异较大。传统的聚类算法如K-means、层次聚类等可能在处理大规模数据集时效率较低,特别是当数据密度不均匀或者存在噪声时。
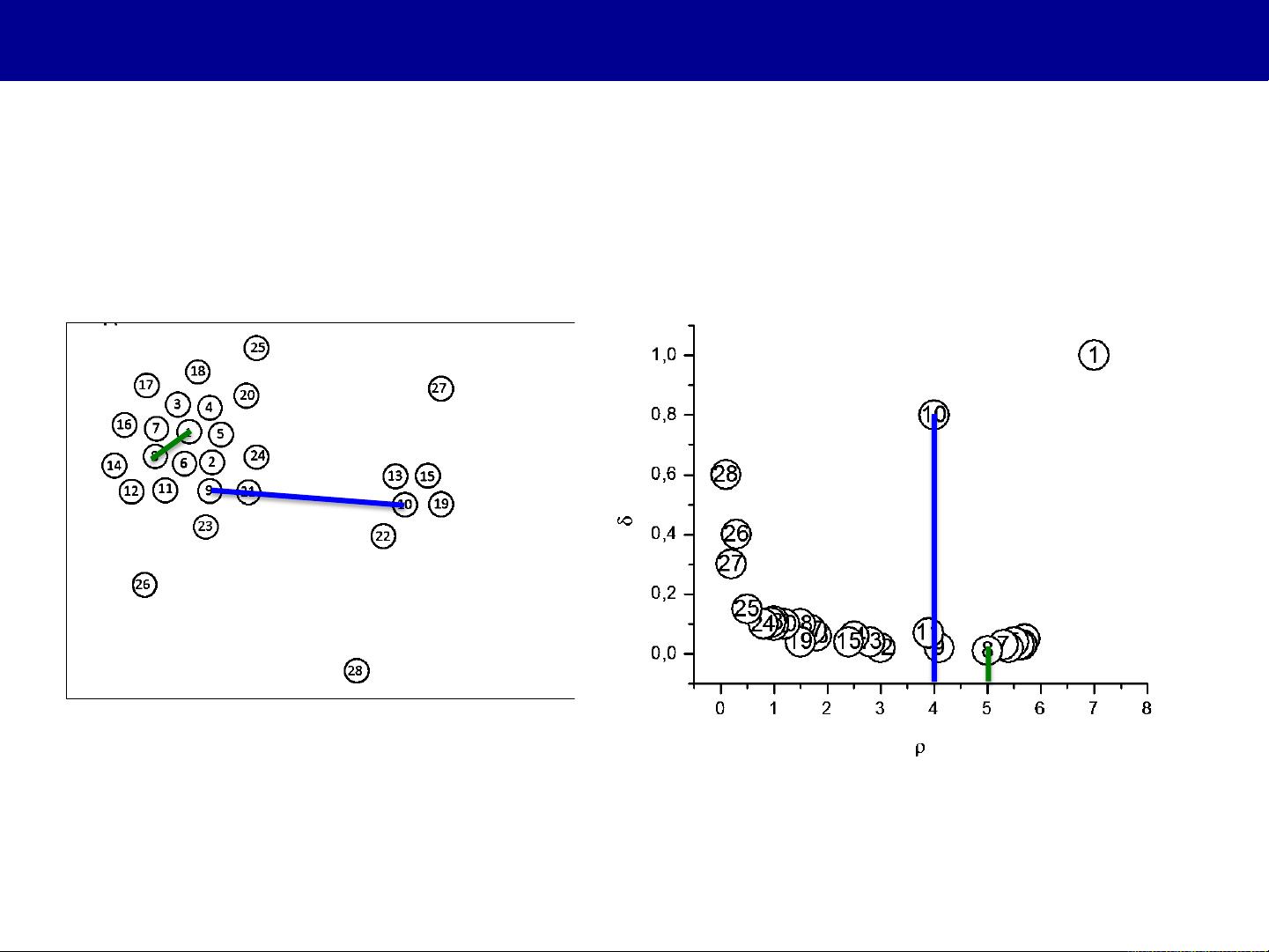
Alessandro Laio, Maria d'Errico, 和 Alex Rodriguez 等学者提出了基于密度峰值(Density Peaks Clustering,DPC)的方法,这是一种新颖且高效的聚类算法。DPC的核心思想是通过搜索数据集中那些同时具有高密度(周围有许多邻近的数据点)和相对高的顶点连接度(与周围低密度区域有明显连接)的点来识别潜在的簇中心。这种方法的优势在于它不需要预先设定簇的数量,能够自动发现簇的数量,并且对于噪声和局部密集区域有较好的鲁棒性。
在使用DPC时,计算机首先对数据进行扫描,找到那些满足高密度和高连接度条件的候选簇中心。然后,它们会把邻居点分到最近的中心所属的簇中,形成一个由簇中心和其邻域构成的结构。整个过程强调了局部特征的重要性,这使得DPC在处理非凸形状的簇和复杂数据分布时表现得相当出色。
相比于传统方法,DPC的执行速度通常更快,因为它不需要多次迭代调整簇中心,而且在大数据集上也能保持良好的扩展性。然而,DPC也并非完美无缺,它可能会对异常值敏感,对初始点的选择有一定依赖性,所以在实际应用中可能需要结合其他预处理步骤或调整参数以优化性能。
快速高效的聚类方法,如密度峰值聚类,是现代数据分析中不可或缺的一部分,尤其在处理实时或大规模数据集时,能够显著提高分析效率并提供更准确的结果。掌握这种技术不仅可以提升数据科学家的工具箱,还能推动研究领域的发展,帮助人们更好地理解和利用海量信息。
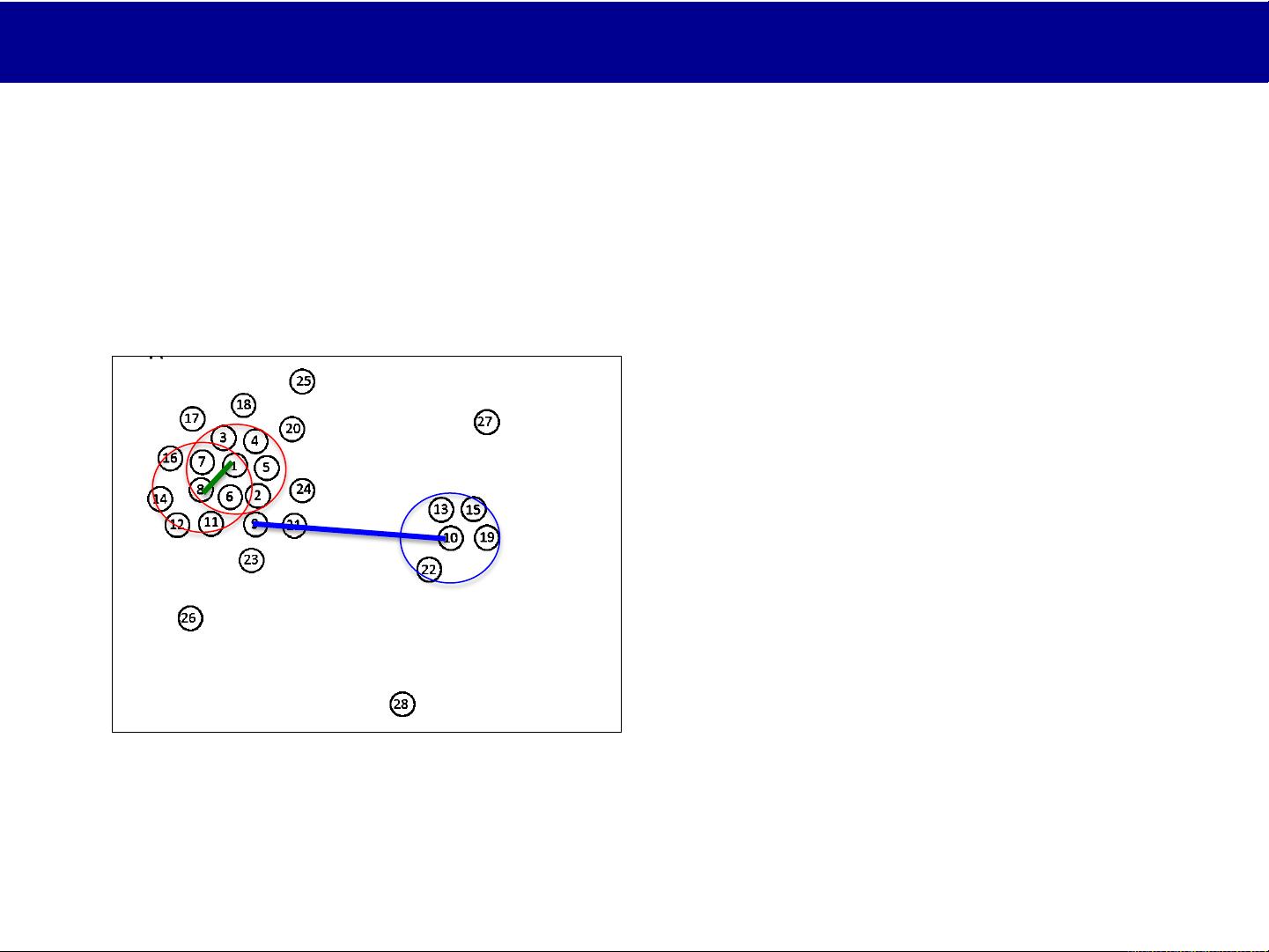
*K5(*%LL()%1@M*N%$;*$#%(1@A%&'AO&'*)N*'#&$,;P*L#%?$*
DEFGHID<+!"#$%&'()*+()+/+J23(8&)$(5)/"+$6/0&+
KL+!586#%&+%1&+"50/"+3&)$(%-+
/'5#)3+&/01+65()%+
ρ9C<QR*
ρ9S<QH*
ρ9CT<QG*
JL+M5'+&/01+65()%+0586#%&+%1&+
3($%/)0&+:(%1+/""+%1&+65()%$+
:(%1+1(*1&'+3&)$(%->+N/7&+%1&+
8()(8#8+@/"#&>+
O!PDQ!D9+KRSJ9+@5"+TJJ+UJVKRL++
剩余39页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2012-08-22 上传
2021-06-01 上传
2016-05-27 上传
2021-06-13 上传
2016-05-27 上传
点击了解资源详情

跬步达千里
- 粉丝: 239
- 资源: 43
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于JAVA WEB SSH框架的客户管理系统(源码+数据库).zip
- coolValidation:jQuery自动验证插件
- 行业文档-设计装置-英语教学卡片放置装置.zip
- 小狐狸Ai系统 小狐狸ai付费创作系统V2.8.0 ChatGPT智能机器人
- js基础知识18张脑图.zip
- 简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- transcription:基于语音识别API的实时转录
- 第二课_python_自然语言处理_
- react-nativ-redux:React Ajay的Native Redux
- scroll-depth:一个用于跟踪滚动深度JavaScript库
- 对一幅灰度图像进行运动模糊并叠加高斯噪声,并采用维纳滤波进行复原+含代码操作演示视频
- 行业文档-设计装置-语文阅读书桌.zip
- jsp-企业人事管理系统.rar
- chordpicker:基于榆树的班卓琴和弦选择器
- 小米机型清除 备份 恢复基带EFS分区 开DIAG端口写分区工具 强力推荐
- moongame:初次使用CreateJS的经验
