SHDA-RF:随机森林驱动的异构域自适应特征迁移
183 浏览量
更新于2024-06-16
收藏 1.66MB PDF 举报
"这篇文章主要探讨了在异质域自适应中如何应用基于随机森林的特征迁移学习算法。它提出了一种新的监督域自适应算法(SHDA-RF),旨在解决跨异质特征空间的迁移学习问题,特别是当目标域只有少量训练实例时。通过随机森林识别连接源域和目标域的关键特征,利用决策树路径与标签分布的关系生成特征变换矩阵,从而将源特征映射到目标特征空间。实验表明,这种方法在不同数据集上优于其他基线和先进的迁移学习方法。"
在监督学习中,模型的构建依赖于充足的标记数据,但实际情况下,获取这样的数据往往成本高昂。迁移学习提供了解决这一问题的途径,通过利用源域已有的知识来辅助目标域的学习。在本文中,作者特别关注的是异构域自适应,即源域和目标域的特征表示不同,这在多领域如情感分析和活动识别中常见。
随机森林作为一种强大的机器学习算法,被引入到特征迁移学习中。它由多棵决策树组成,每一棵树都可以识别出一部分特征的重要性。在SHDA-RF算法中,随机森林用于识别那些对源域和目标域都重要的“枢轴”特征。这些特征是连接两个域的桥梁,它们的存在使得尽管特征空间不同,仍能进行有效的知识迁移。
文章的核心创新在于,它利用随机森林中决策树路径与特定标签分布的关系,构建一个稀疏特征变换矩阵。这个矩阵能够将源域的模式转换到与目标域特征空间兼容的形式。之后,目标模型与投影后的源数据一起重新训练,从而提升在目标域上的性能。
实验部分展示了SHDA-RF在多种数据集上的优越性,无论是在不同的维度还是在不同稀疏度的情况下,它都能有效地减少源域和目标域之间的分布差异,实现知识的有效迁移。这些结果验证了该方法在应对现实世界异构域问题时的有效性和适用性。
这篇文章揭示了随机森林在处理异构域自适应问题上的潜力,为特征迁移学习提供了一个新的视角和实用工具,尤其在源数据和目标数据特征表示存在显著差异的情景下。这不仅深化了我们对迁移学习的理解,也为未来相关研究提供了有价值的参考。
34
S.
北卡罗来纳州苏希亚克 里希南
/
人工智能
268
(
2019
)
30-53
∈
P
S
n
2
2
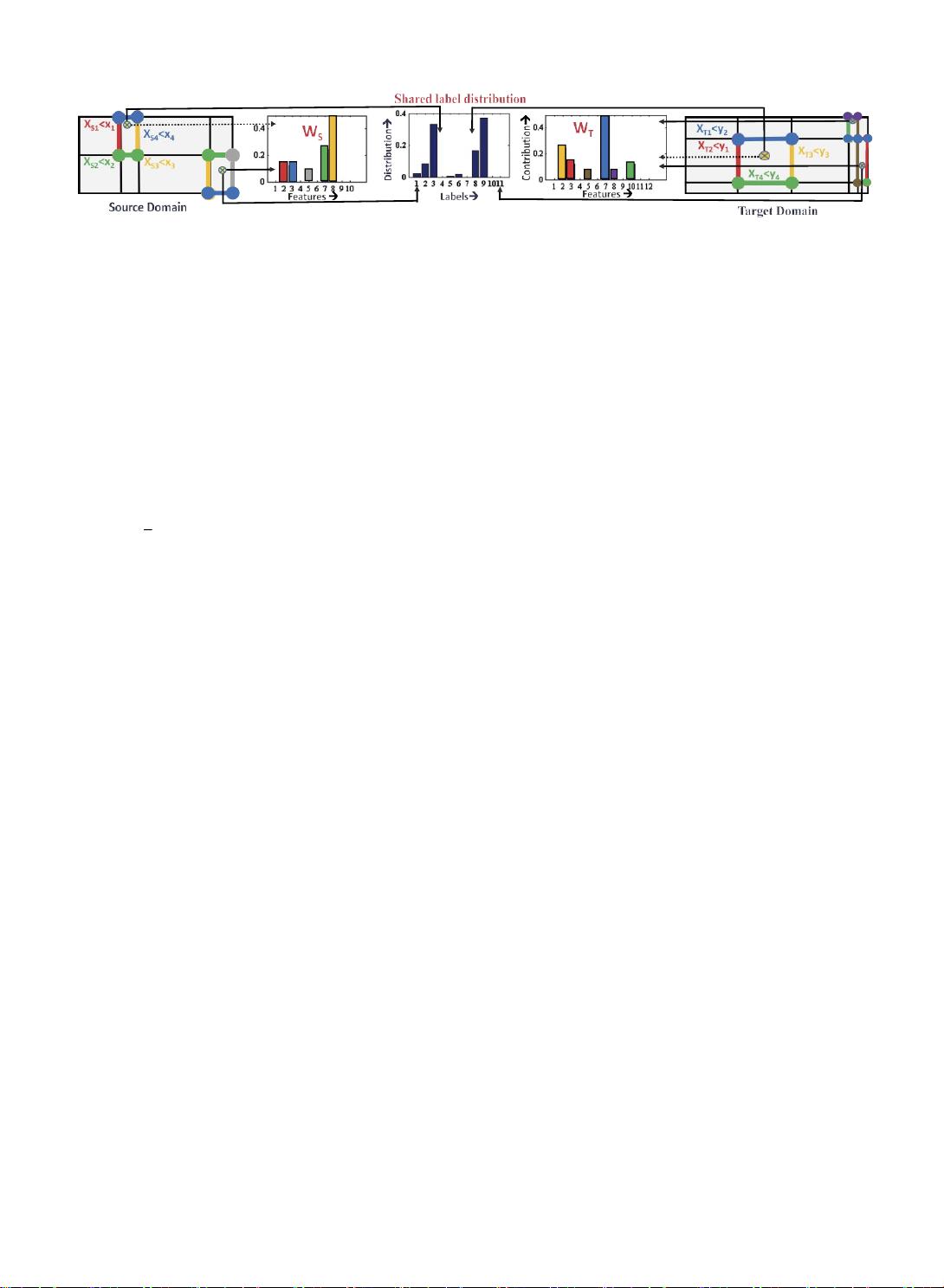
图二
. 边界框表示实例空间的分区,其中分区的边界(彩色线)使用特征的子集定义。每个分区包含遵循特定标签分布的训练示例。
SHDA-RF
通过加权定义
分区的特征来估计域中特征对分区标签分布的贡献。遵循相同标签分布的多个分区被分组在一起。源域中特征的估计贡献为
W
S
,目标域中特征的估计贡献
为
W
T
。
SHDA-RF
假设相同标签分布的
W
S
和
W
T
必须彼此相关
在具有不同模态(如文本和图像)的两个域上概括共同特征可能是不实际的。我们的新解决方案通过利用源域和目标域之间的
公共标签信息作为知识转移的支点,桥接了异构的特征空间。所提出的算法确定源和目标特征之间的映射
P
S
的
该算法的视觉表示
如图2所示。该算法分为三个步骤。 第一步确定跨域具有相似标签分布的数据分区。第二步估计 特征对创建数据分区的贡
献。 最后一步涉及从估计的特征贡献学习变换。
3.1.
发现跨域
特征转移问题主要是由源域和目标域的数据点之间的对应关系不可用所挑战的。 如果有足够的对应关系,我们可以学习一
个鲁棒的变换
P
S
R
d
S
×
d
T
,如公式(2)所示,通过最小化变换损耗这里,
λ
是正则化参数,
n
是
的通信。
min
1
||X
T
−X
S
P
S
||
2
+λ||P
S
||
2
(二)
在大多数现实世界的HDA场景中,这些对应关系是不存在的。因此,需要识别域之间的一些公共信息,这些信息可以用来桥接
它们。我们的方法不假设任何重叠的功能或域/任务相关的信息,可以被利用来桥接域相关的功能。然而,所提出的算法依赖于
域之间的公共标签空间,即源域和目标域具有公共标签集。我们的特征转移方法利用公共标签空间来生成对应的特征向量,
两个领域。在最简单的场景中,每个共享标签都是一个pivot。如果域之间的公共标签的数量 很小,学习特征变换成为一个
具有挑战性的问题,因为我们需要足够数量的跨域对应[5]。我们的新标签空间驱动算法克服了这一限制,依赖于自然发生的标
签分布在复杂的标签空间,而不是个别标签。共享标签分发是连接源域和目标域的枢纽。由于跨域的公共标签的数量是有限
的,我们提取跨域的数据分区,显示类似的标签分布。源特征的估计贡献, 朝向相同标签分布的目标特征被认为是跨域对应。
为了得到这些标签分布,我们的方法着眼于在数据集上建模的未修剪决策树的叶节点。决策树遵循贪婪策略,基于某些特征
值测试递归地划分数据。的路径 在决策树中,从根到叶节点包含被选择为分裂函数的特征序列。候选拆分 在一个节
点涉及一个局部最优分割的基础上一些度量像基尼杂质,信息增益或增益比。决策树的叶节点表征数据的不同分区,每个分区
具有特定的标签分布
L
。训练单个决策树的问题是它过度拟合数据,我们没有得到足够数量的共同点。 标签在两个域中的分
布。因此,我们训练了一个随机森林[47,48],以确保有足够数量的关键标签分布来学习域之间的映射。随着树的深度增加,
它倾向于过度拟合表现出高方差和低偏差的数据。 随机森林模型从众多决策树中进行多数投票,以减少这种高方差而不影响偏
差,其中森林中的每个未修剪决策树都是使用具有替换的随机特征子集构建的[49]。我们的算法分别从
S
和
T
构造
ns
和
nt
树
3.2.
估计特征关系
W
S
和
W
T
该算法的下一步分别计算源域和目标域中的域相关特征与共享枢轴之间的关系矩阵
W
S
和
W
T
。 由于我们的枢轴是标签分布,
我们将这种关系定义为域相关特征对创建枢轴标签分布的贡献。这种关系可以很容易地从决策树结构中提取出来在叶节点处的
数据分区的边界可以
剩余23页未读,继续阅读
2018-07-05 上传
2024-10-05 上传
2023-10-19 上传
2021-08-18 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
