哈弗H2s蓝标汽车用户指南:操作与安全提示
版权申诉
31 浏览量
更新于2024-07-19
收藏 12.65MB PDF 举报
本篇文档是长城哈弗H2s蓝标汽车的用户操作说明书PDF电子版,提供了全面的车辆使用指导。用户手册旨在帮助车主更好地理解和操作他们的车辆,确保安全和高效驾驶体验。以下是一些关键知识点:
1. **车辆熟悉度与安全提示**:
- 手册强调了在启动车辆前阅读的重要性,因为它提供了操作车辆的重要提示,有助于车主了解和利用哈弗H2s的技术优势。
- 手册关注行驶安全性和交通安全性,提醒读者注意车辆装备的差异,某些功能可能因车辆型号、地区或市场配置不同而存在。
2. **车辆装备和配置信息**:
- 手册涵盖了所有标准、国别和特殊装备,但读者需确认车辆实际配置,因为手册中的描述可能与个别车辆不符,需参考销售资料或经销商获取准确信息。
- 在右座驾驶型车辆上,操作元件的位置可能与插图有所差异,提示用户实际操作时需要参照车辆本身。
3. **手册时效性和更新**:
- 手册中的信息至印刷日期是最新的,但长城汽车的产品持续改进,未来可能会有更新,用户应保持关注。
4. **视听系统**:
- 提供了单独的视听系统手册链接,可能包含音频和视频设备的操作指南。
5. **附件、备件与改装**:
- 用户可以购买长城汽车原厂配件,建议使用原厂配件以确保质量和保修。非原厂配件可能导致车辆损坏和性能问题,长城公司对此不负责。
6. **安全警示与注意事项**:
- 文档中包含三种类型的信息标记:警告(严重后果)、注意事项(潜在损坏风险)和提示(辅助信息),帮助车主理解操作过程中的潜在风险和最佳实践。
7. **驾驶时的通用注意事项**:
- 清醒驾驶是强调的基本安全要点,确保驾驶者在驾驶过程中保持清醒,避免疲劳驾驶。
通过阅读这份手册,车主不仅能够掌握哈弗H2s蓝标汽车的具体操作,还能了解如何维护车辆安全,确保车辆的最佳性能表现。定期查阅和遵循手册的指导将极大地提升驾驶体验和行车安全。
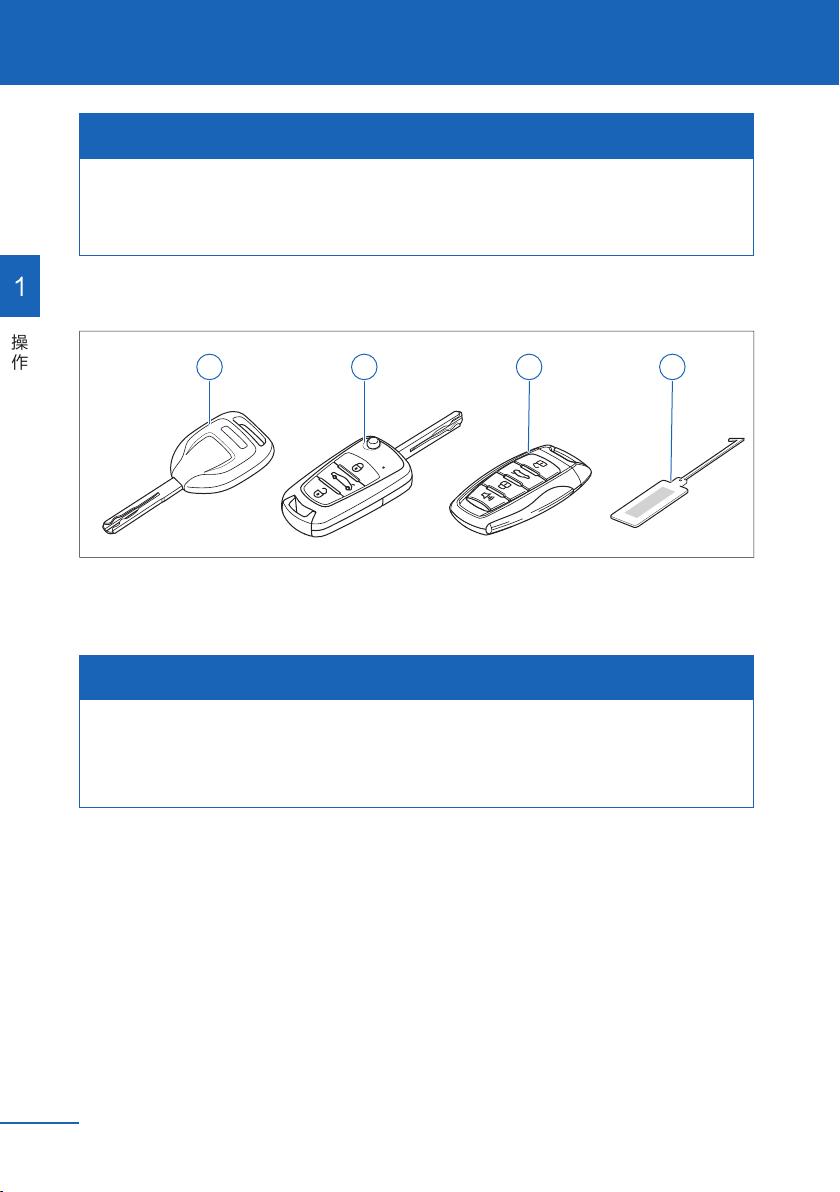
操作
A B C
D
A
B
C
D
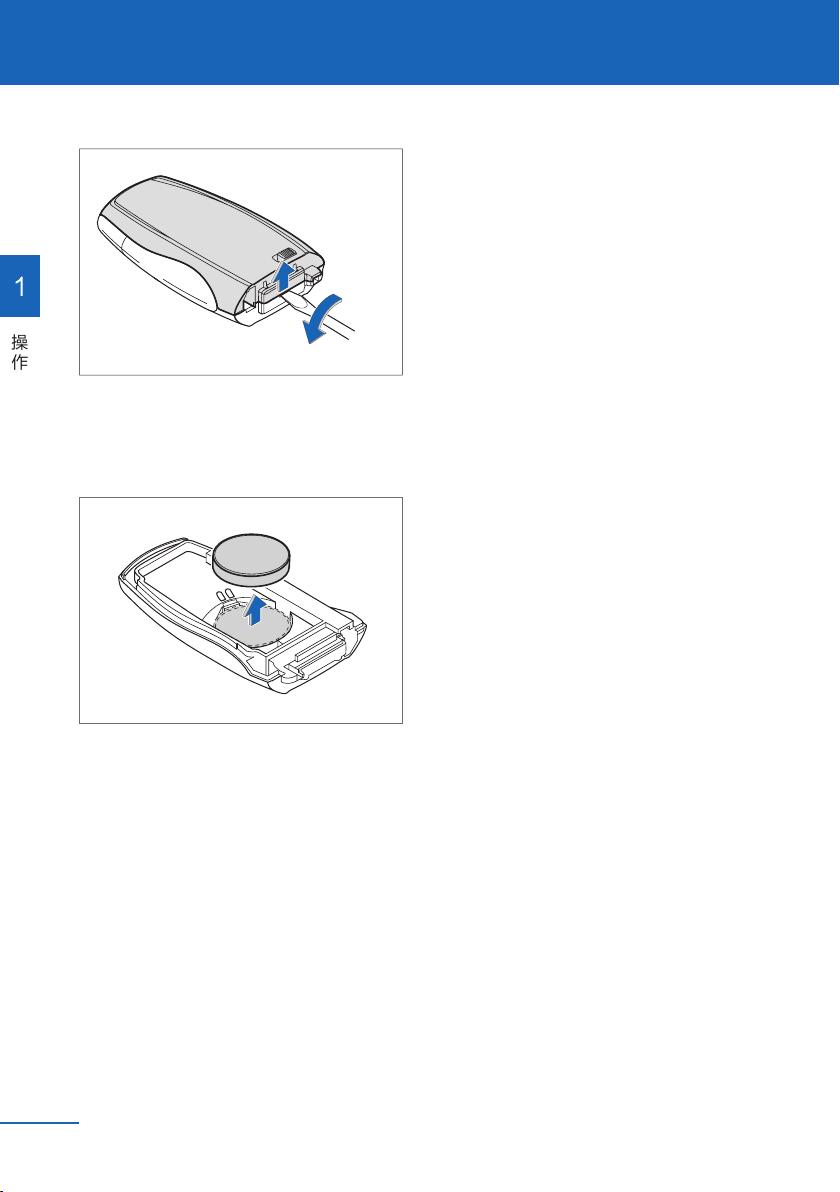
剩余174页未读,继续阅读
315 浏览量
503 浏览量
253 浏览量
748 浏览量
1353 浏览量









