商务数据分析:自变量选择与逐步回归策略详解
版权申诉
187 浏览量
更新于2024-07-03
收藏 1.17MB PPT 举报
商务数据分析与统计建模的第三章深入探讨了自变量的选择与逐步回归这一核心议题。自变量选择在统计建模中至关重要,因为它直接影响模型的精度和预测能力。回归分析中,全模型(包含所有可能的自变量)与选模型(仅选取部分变量)是两种基本策略。全模型(如公式(1)所示)试图捕捉所有潜在影响因素,而选模型(如公式(2)所示)则是在众多变量中寻找最能解释因变量变化的有效组合。
对于自变量选择,章节首先介绍了全模型和选模型的概念,强调了在实际问题中如何根据可用变量进行选择。全模型的子集数目可以通过组合数学计算得出,即2的m次方减一,其中m代表变量总数,这体现了模型复杂度和可能变数数量的关系。
章节进一步提出了两种常见的自变量选择准则。准则1是通过自由度调整的复相关系数(Adjusted R-squared)最大化,该准则试图找到能够最大程度上解释因变量变异的模型。然而,这种方法可能存在过拟合的风险,因为R-squared本身容易受到模型复杂度的影响。
另一种准则,准则2是赤池信息量(Akaike Information Criterion,简称AIC),由日本统计学家赤池在1974年提出。AIC综合了模型的拟合度和复杂度,通过最小化模型的AIC值来选择最优模型。AIC准则适用于回归和时间序列分析中的模型选择,它平衡了模型的拟合性能和模型的简单性,避免过度复杂导致的泛化能力下降。
此外,章节还详细讲解了逐步回归方法,这是一种迭代的过程,通过添加或删除一个变量来逐步优化模型。这种方法有助于在众多变量中逐步确定最佳的变量组合,同时保持模型的解释性和预测力。
本章内容深入剖析了自变量选择在商务数据分析中的重要性,提供了多种评估和选择自变量的方法,包括直观的残差平方和最小原则、复相关系数、AIC等,以及逐步回归的具体实施步骤。掌握这些内容对于构建有效且可靠的统计模型具有实际操作指导意义。

所有子集回归
准则 2 赤池信息量 AIC 达到最小
AIC 准则是日本统计学家赤池 (Akaike)1974 年根据极
大似然估计原理提出的一种较为一般的模型选择准则,人
们称它为 Akaike 信息量准则 (Akaike Information
Criterion, 简记为 AIC) 。 AIC 准则既可用来作回归方程自
变量的选择,又可用于时间序列分析中自回归模型的定阶
上。由于该方法的广泛应用,使得赤池乃至日本统计学家
在世界的声誉大增。
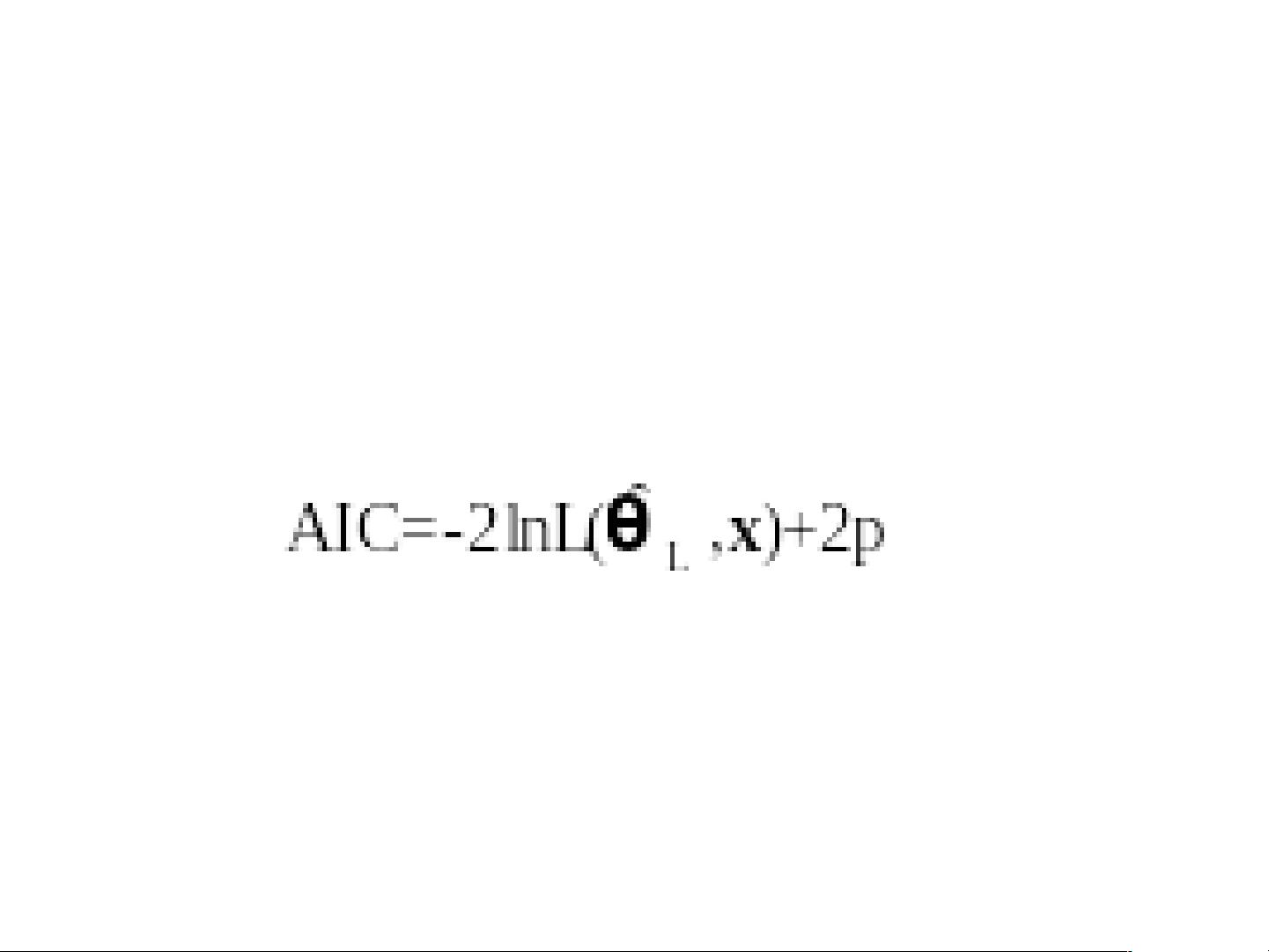
剩余48页未读,继续阅读
2022-06-17 上传
2022-06-17 上传
2022-07-04 上传
2023-11-24 上传
2023-12-25 上传
2023-08-25 上传
2023-06-02 上传
2023-07-12 上传
2023-05-22 上传
2024-01-03 上传

智慧安全方案
- 粉丝: 3812
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
