YOLO训练自定义数据集指南:迁移学习与预训练权重使用
需积分: 0 165 浏览量
更新于2024-08-04
收藏 350KB DOCX 举报
"该资源主要涉及使用PyTorch框架训练自定义数据集的过程,特别是针对YOLO模型的训练。在训练前需要准备VOC格式的数据集,并可能涉及到COCO数据集的权重转换。"
在训练自定义数据集时,首先要理解YOLO模型的工作原理。YOLO(You Only Look Once)是一种实时目标检测系统,它将图像划分为多个网格,并在每个网格中预测物体的边界框和类别概率。YOLO模型通常由多个卷积层和全连接层组成,其中最后一层输出包含边界框坐标和类别概率的特征图。
对于【标题】中提到的"如何训练自己的数据集05191",以下是一些关键步骤和注意事项:
1. **预处理数据集**:
- 数据集应遵循VOC(PASCAL VOC)格式,包括JPEGImages文件夹存放图像,Anotations文件夹存放XML标注文件。
- 图像需为jpg格式,标签为VOC标准的XML文件,确保每个XML文件对应一个jpg图像,并包含物体的边界框信息。
- 如果原始数据集不是VOC格式,例如COCO的json格式,需要使用工具将其转换为VOC XML格式。
2. **预训练权重**:
- YOLO模型的预训练权重通常在大型数据集如COCO(包含80个类别)上训练得到。
- 使用预训练权重可以加速训练并提高模型性能,但需要确保自定义数据集的类别与COCO类别的子集一致或进行适当调整。
- 如果自定义数据集类别数量不同,只需要修改模型最后一层的输出通道数,其他部分可以直接加载预训练权重。
3. **训练准备**:
- 删除`logs`文件夹中的旧权重和日志,避免混淆。
- 清理`VOCdevkit/VOC2007/ImageSets/Main`文件夹中的txt文件,这些文件用于指示训练集和验证集。
- 删除`map_out`文件夹,这是上次测试结果的存储位置。
4. **创建类别文件**:
- 在`model_data`文件夹下创建一个txt文件(如`my_classes.txt`),列出自定义数据集中所有类别的名称,每行一个类别。
5. **修改配置文件**:
- 根据自定义数据集的实际情况更新配置文件,包括批大小、学习率、类别数等参数。
- 注意`yolo.py`文件中的类别文件应指向`my_classes.txt`。
6. **运行训练**:
- 修改`get_map.py`中的`map_mode`参数,根据需求选择合适的模式。
- 运行训练脚本开始训练过程。
7. **评估与测试**:
- 训练完成后,可以使用`yolo.py`进行预测,但需要注意检查类别判定条件,确保只对自定义数据集的类别进行预测。
通过以上步骤,你可以成功地使用PyTorch和YOLO模型对自定义数据集进行训练。在实际操作中,还应注意数据增强、超参数调优等环节,以提高模型的泛化能力。同时,及时监控训练过程,如损失函数的变化和验证集的性能,以便适时调整模型。
yolo.py 这个文件是与训练完之后进行预测用的,与训练过程无关。于是当下载了代码和
预训练权重之后,由于预训练权重是在 coco 数据集上训练出来的,于是 yolo.py 里面的
所要去预测的类别的 txt 文件只能指向 coco_classes.txt。虽然 voc 数据集(20 个类)里
面的类在 coco 数据集(80 个类)里面都有,但是如果修改为 voc_classes.txt 就会报错。
载入预训练权重可以预测 voc 里面没有但是 coco 里有的类,比如 umbrella。(如果只想
预测 voc 里面的类,请在代码里面修改,加上类别判定条件即可。)
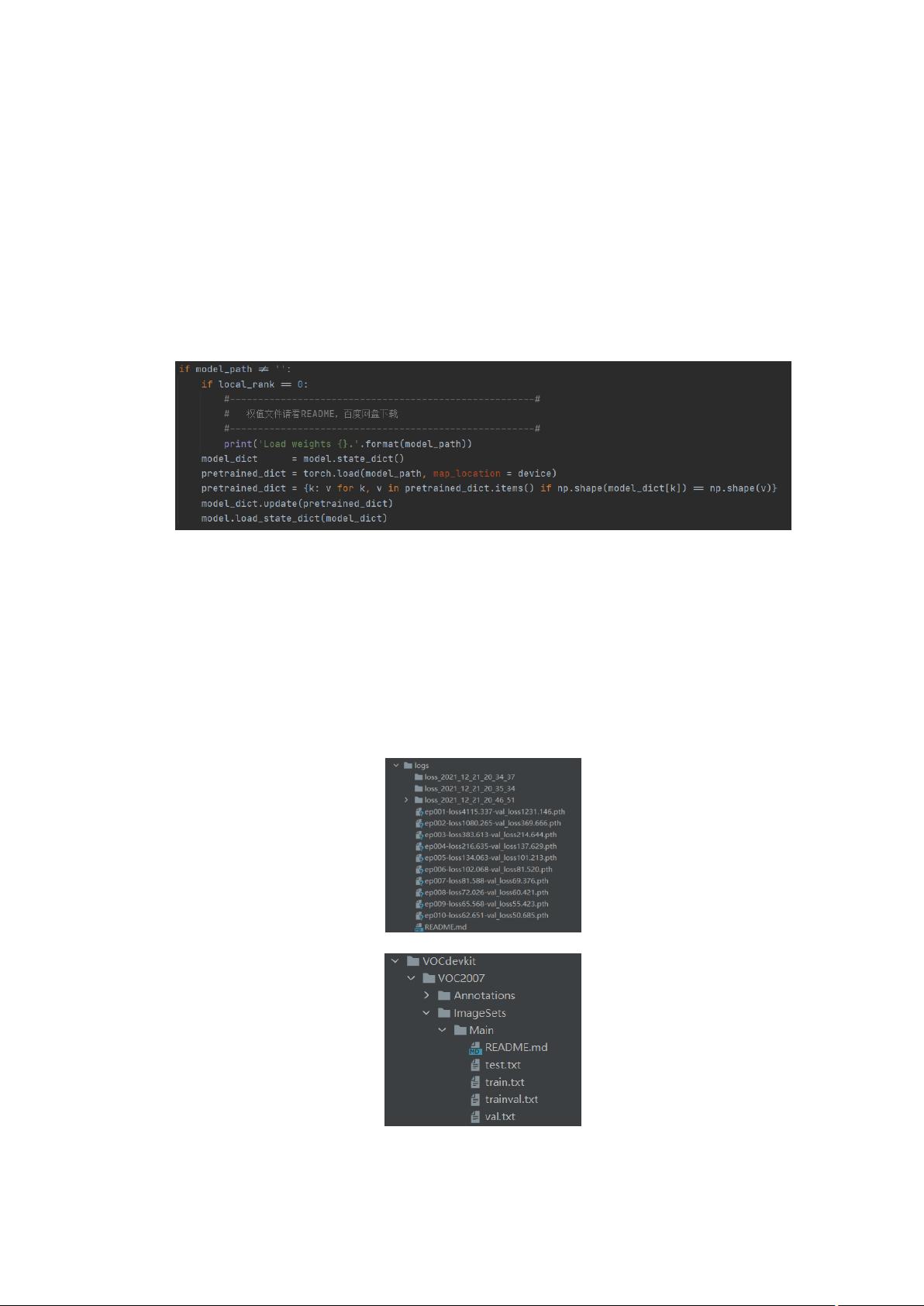
关于使用预训练权重,比如使用 coco 训练出来的 YOLO 权重,coco 有 80 各类,而自己
的数据集不是 80 各类,其实只有最后输出的三个特征图在通道数上有区别,其他任何
地方都没有区别,所以加载的时候可以通过下面的代码加载匹配的权重:
所以,如果采用迁移学习去训练的话,不管是自己的数据集还是 voc2007+2012 数据集,
首先下载代码与预训练权重(注:如果修改了网络结构的话就没办法用预训练权重
了),参照以下步骤:
(前提要求:标签必须是 VOC 格式的,即 XML 文件。图片必须是 jpg 格式的。Coco 数
据集是 json 格式的标签,可以用程序转成 voc 格式。其他格式的图片也能转为 jpg 格式)
1. 首先删除一些东西:
(1)logs 文件夹下所有权重和日志文件
(2)VOCdevkit/VOC2007/ImageSets/Main 文件夹下的四个 txt 文件
(3)2007_train.txt 和 2007_val.txt 文件
下载后可阅读完整内容,剩余6页未读,立即下载
2023-08-25 上传
2023-05-09 上传
2022-04-14 上传
842 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

狼You
- 粉丝: 27
- 资源: 324
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
