面向对象的垂直搜索:实例与技术探索
需积分: 3 90 浏览量
更新于2024-12-27
收藏 900KB PDF 举报
垂直搜索(Verticle Searching)是一种针对特定领域或应用领域的高级搜索引擎技术,它突破了传统文档级检索的局限,专注于处理网页上结构化的、关于现实世界实体的信息。本文档由微软Web Search and Mining Group提供的,聚焦于面向对象的搜索方法,旨在解决互联网上大量存在的关于学术文献、产品信息等特定领域对象的检索问题。
当前的主流搜索引擎主要进行文档级别的排名和检索,对于静态网页和在线数据库中包含的关于物体的结构化信息处理不够充分。垂直搜索旨在通过信息提取(Web Information Extraction)和整合(Information Integration)技术,将与特定领域相关的网页内容转化为可操作的对象,如学术论文中的作者、关键词、发表日期等,或者产品信息中的品牌、型号、价格等。
本文介绍了一种新的搜索范式,即对象级别垂直搜索,这种搜索系统能够在用户查询时,根据对象的相关性和流行度对搜索结果进行排序。例如,在学术搜索领域,Libra Academic Search(<http://libra.msra.cn>)可能优先展示与查询最相关且被引用次数较多的论文;而在Windows Live Product Search(<http://products.live.com>)中,用户可能会看到与他们需求匹配的热门和评价高的电子产品。
核心技术和实现包括以下几个方面:
1. **对象级信息提取**:这一技术涉及从网页中自动识别和抽取与特定对象相关的关键信息,如使用自然语言处理和机器学习算法来识别实体、关系和属性。
2. **信息整合**:收集到的碎片化信息需要进行整合,形成一致的对象模型,以便于后续处理和查询。这可能涉及到数据清洗、标准化和关联性分析。
3. **对象级别排名**:不同于传统的文档排序,对象级别排名是基于对对象的多维度评估,如相关性(如文本匹配度、用户评价)、权威性(如来源可信度)和时效性等因素。
4. **应用实例**:文中提及的两个具体工作系统——Libra Academic Search和Windows Live Product Search,展示了这些技术在实际场景中的应用和优化。
总结来说,垂直搜索通过对网页内容进行深度挖掘和专业领域的聚焦,提供了一个更精准、高效和用户友好的搜索体验,有助于提高信息检索的效率和质量。随着大数据和人工智能的发展,对象级别垂直搜索在未来有望成为搜索引擎发展的重要方向。
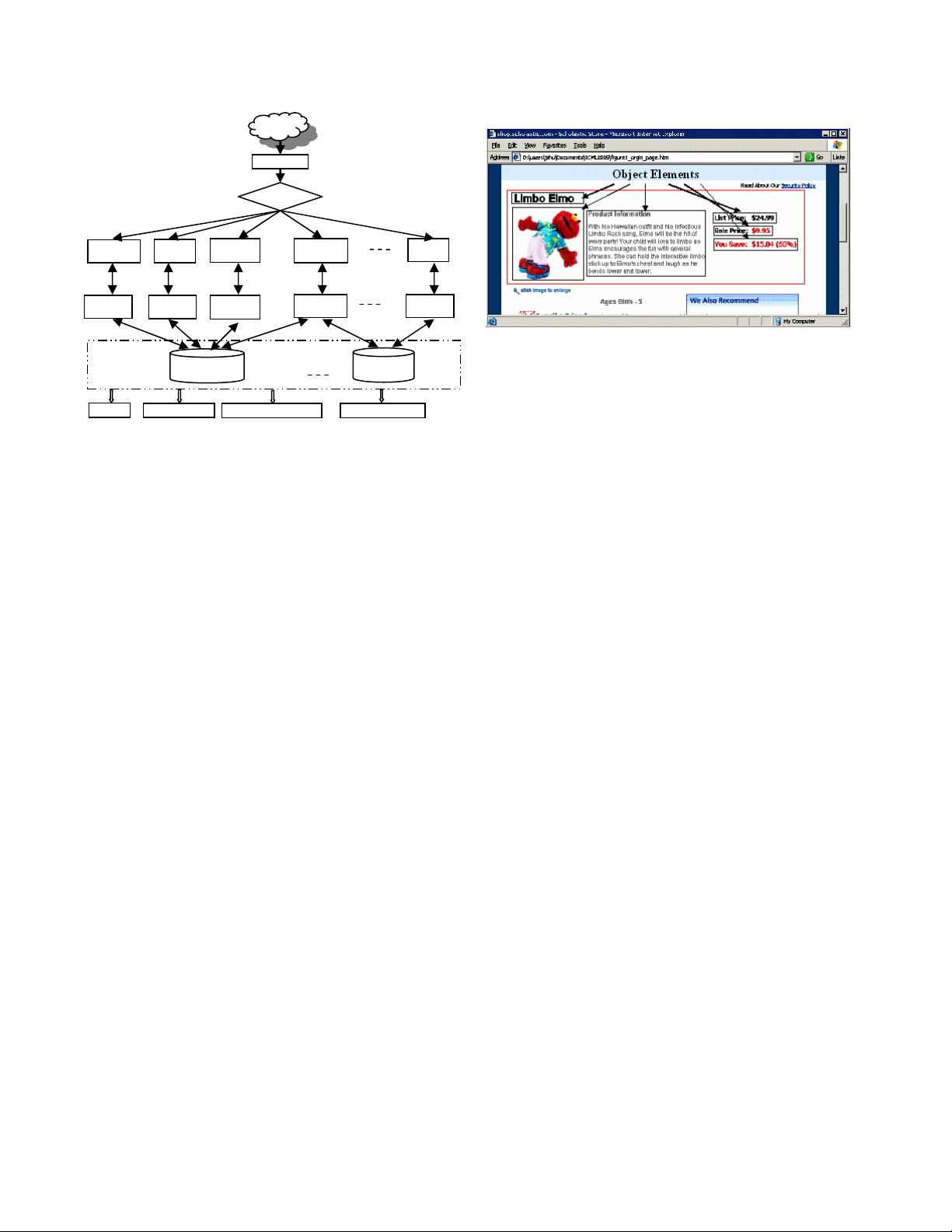
Figure 3. System Architecture
3.1 Crawler and Classifier
The tasks of the crawler and classifier are to automatically collect
all relevant webpages/documents that contain object information
for a specific vertical domain. The crawled webpages/documents
will be passed to the corresponding object extractor for extracting
the structured object information and building the object
warehouse.
3.1.1 Insight
If we use the nodes to denote the objects and edges to denote the
relationship links between the objects, we can see that the objects
information with a vertical domain forms an object relationship
graph. For example, in Libra academic search, we have three
different types of nodes to representing papers, authors, and
conferences/journals, and three different types of edges (i.e. links)
pointing to paper objects that represent three varying types of
relationships. They are cited-by, authored-by, and published-by.
The ultimate goal of the crawler is to effectively and efficiently
collect relevant webpages and to build a complete object
relationship graph with as many nodes and edges and as many
attribute values for each node as possible (assuming we have
perfect extractors and aggregators).
3.1.2 Our Approach
We build a “focused” crawler that uses the page classifier and the
existing partial object relationship graph to guide the crawling
process. Basically, in addition to the web graph which is used by
most page-level crawlers, we employ an object relationship graph
to guide our crawling algorithm.
Since the classifier is coupled with the crawler, it needs to be very
fast to ensure efficient crawling. Based on our experience in
building a classifier for Libra and Windows Live Product Search,
we found that we could always use some strong heuristics to
quickly prune most of irrelevant pages. For example, in our
product pages classifier, we can use the price identifiers (such as
dollar signs $) to efficiently prune most non-product pages. The
average time of our product classifier is around 0.1 millisecond,
and its precision is around 0.8, with recall around 0.9.
Figure 4. An Object Block with 6 Elements (contained in the
red rectangle) in a Webpage.
3.2 Object Extractor
Information (e.g. attributes) about a web object is usually
distributed in many web sources and within small segments of
webpages. The task of an object extractor is to extract metadata
about a given type of objects from every web page containing this
type of objects. For example, for each crawled product web page,
we extract name, image, price and description of each product. If
all of these product pages or just half of them are correctly
extracted, we will have a huge collection of metadata about real-
world products that could be used for further knowledge
discovery and query answering. Our statistical study on 51,000
randomly crawled webpages shows that about 12.6 percent are
product pages. That is, there are about 1 billion product pages
within a search index containing 9 billion crawled webpages.
However, how to extract product information from webpages
generated by many (maybe tens of thousands of) different
templates is non-trivial. One possible solution is that we first
distinguish webpages generated by different templates, and then
build an extractor for each template. We say that this type of
solution is template-dependent. However, accurately identifying
webpages for each template is not a trivial task because even
webpages from the same website may be generated by dozens of
templates. Even if we can distinguish webpages, template-
dependent methods are still impractical because learning and
maintenance of so many different extractors for different
templates will require substantial efforts.
3.2.1 Insight
By empirically studying webpages across websites about the same
type of objects across web sites, we find many template-
independent features.
Information about an object in a web page is generally
grouped together as an object block, as shown in Figure 4.
Using existing web page segmentation [7] and data record
extraction technologies [35], we can automatically detect
these object blocks, which we further segment into atomic
extraction entities called object elements. Each object
element provides partial information about a single attribute
of the web object.
web
Crawler
Classifier
Location
Extractor
Product
Extractor
Conference
Extractor
Author
Extractor
Paper
Extractor
Paper
Aggregator
Location
Aggregator
Product
Aggregator
Scientific web
Object Warehouse
Product Object
Warehouse
web Objects
PopRank
Object Relevance
Object Community Mining
Object Categorization
Conference
Aggregator
Author
Aggregator
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-02-09 上传
2021-06-26 上传
2021-06-15 上传
2021-02-05 上传
2020-10-30 上传
2019-09-26 上传

ke_linlin
- 粉丝: 3
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 短视频去水印解析HTML源码
- Notes Finder-crx插件
- qiskit-machine-learning:量子机器学习
- mysql_employee_tracker
- winform-toolkit-master.zip
- readable-stream-clone:多次克隆可读流
- jQuery右侧弹出侧边导航栏特效代码
- 长篇大论
- sfseize:Scala中的空间填充曲线
- easyhttpserver:简单轻巧的http服务器
- opcat:开放式港口捕手
- stm32f407vet6的HAL配置串口通信程序
- physics-example-d:一个入门项目,用于将以太物理引擎集成到MonoGame项目中
- pres-respimg-perf-cssconf
- django-spring-2021
- cholladay0816:我的个人资料
