Open欧拉上的Hadoop分布式集群搭建指南
需积分: 0 7 浏览量
更新于2024-06-17
收藏 3.75MB DOCX 举报
"本文主要介绍了如何在Open欧拉操作系统上搭建Hadoop分布式计算框架,包括Open欧拉和Hadoop的基本概念、集成原理以及基于Open欧拉的虚拟机集群的搭建步骤。"
Open欧拉与Hadoop的结合为大数据处理提供了一个高效、安全的平台。Open欧拉作为一款多场景适用的操作系统,能够支持服务器、云计算、边缘计算等多种计算环境,而Hadoop则是一个强大的分布式计算框架,两者结合能够充分发挥各自的优势。
在数据集成方面,Hadoop的分布式文件系统(HDFS)能够与Open欧拉操作系统无缝对接,使得在Open欧拉环境下可以对HDFS中的大量数据进行高效分析。同时,Open欧拉可以作为数据处理的底层支撑,利用其自身的稳定性为Hadoop提供可靠的数据存储基础。
功能集成上,Open欧拉可以与Hadoop的MapReduce和YARN组件协同工作。MapReduce负责数据的分布式计算,而YARN则作为资源管理系统,协调集群中的计算资源,确保任务的分布式执行。Open欧拉与Hadoop的这种结合使得任务调度和资源管理更为高效。
性能优化是另一个关键点。Open欧拉与Hadoop集成后,可以利用Hadoop的分布式计算能力,通过负载均衡和并行处理,显著提升大数据处理的速度和效率。这对于处理大规模数据分析任务至关重要。
在实际操作中,搭建基于Open欧拉的Hadoop集群涉及以下步骤:
1. 在服务器上安装Open欧拉操作系统,进行必要的系统配置,如网络设置、用户权限等。
2. 安装Java开发环境(JDK),因为Hadoop运行依赖Java。
3. 下载并安装Hadoop,将其解压到指定目录。
4. 配置Hadoop的环境变量,如HADOOP_HOME、JAVA_HOME等。
5. 修改Hadoop配置文件,如core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml,以适应Open欧拉环境和集群需求。
6. 初始化HDFS文件系统,进行格式化操作。
7. 启动Hadoop服务,包括NameNode、DataNode、ResourceManager、NodeManager等。
8. 克隆虚拟机,创建更多节点以扩展集群规模。
9. 使用SSH客户端(如Xshell)连接所有节点,进行集群管理。
通过以上步骤,一个基于Open欧拉的Hadoop虚拟机集群便搭建完成,可以开始进行大数据处理任务。这个集群可以应用于各种业务场景,如数据分析、机器学习、实时流处理等,为企业的大数据战略提供强大支撑。
6
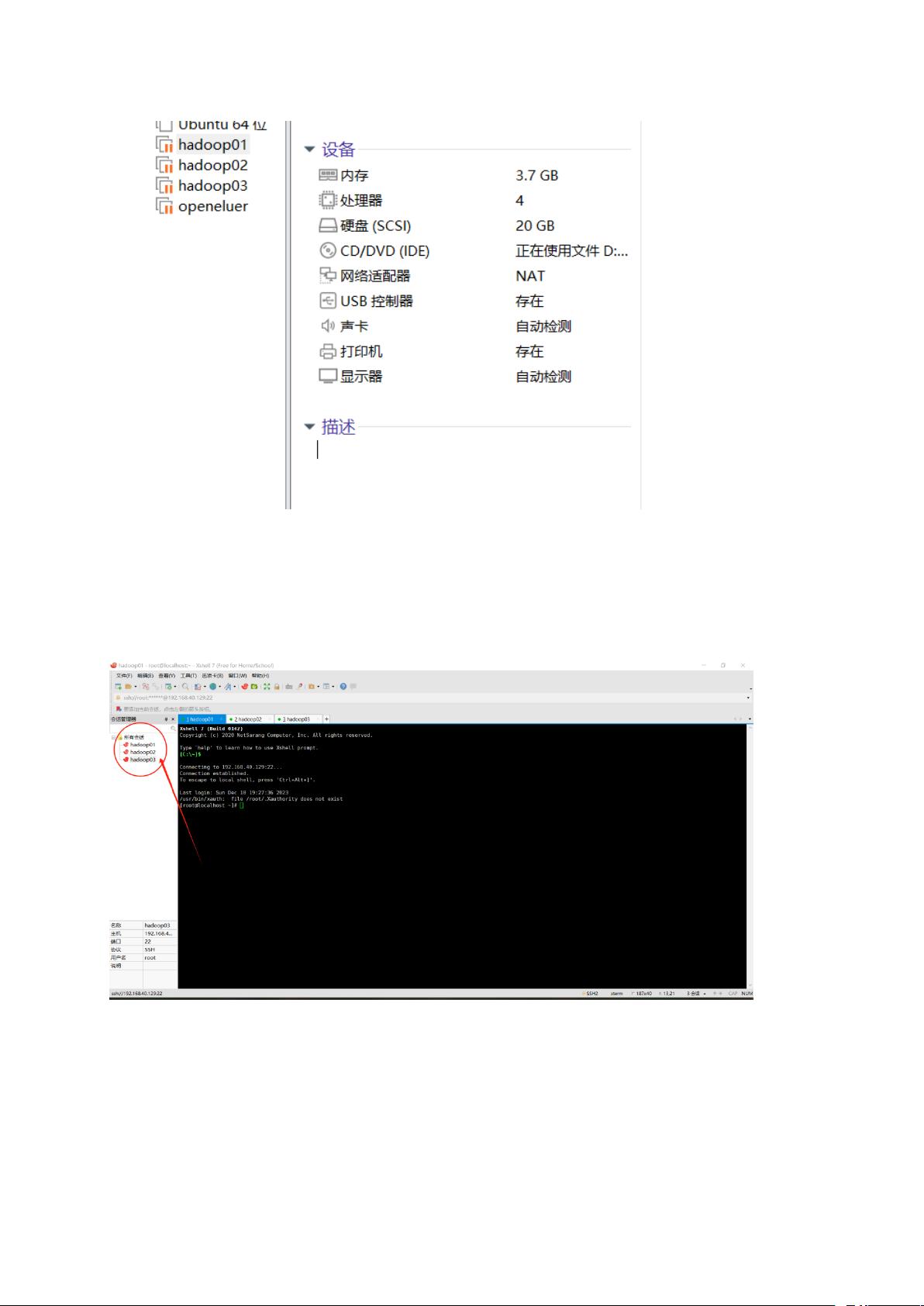
利用 xshell 实现主机与虚拟机便捷交互
利用 xshell 连接 hadoop01,hadoop02,hadoop03
以 open 欧拉为镜像源的虚拟机集群初步搭建
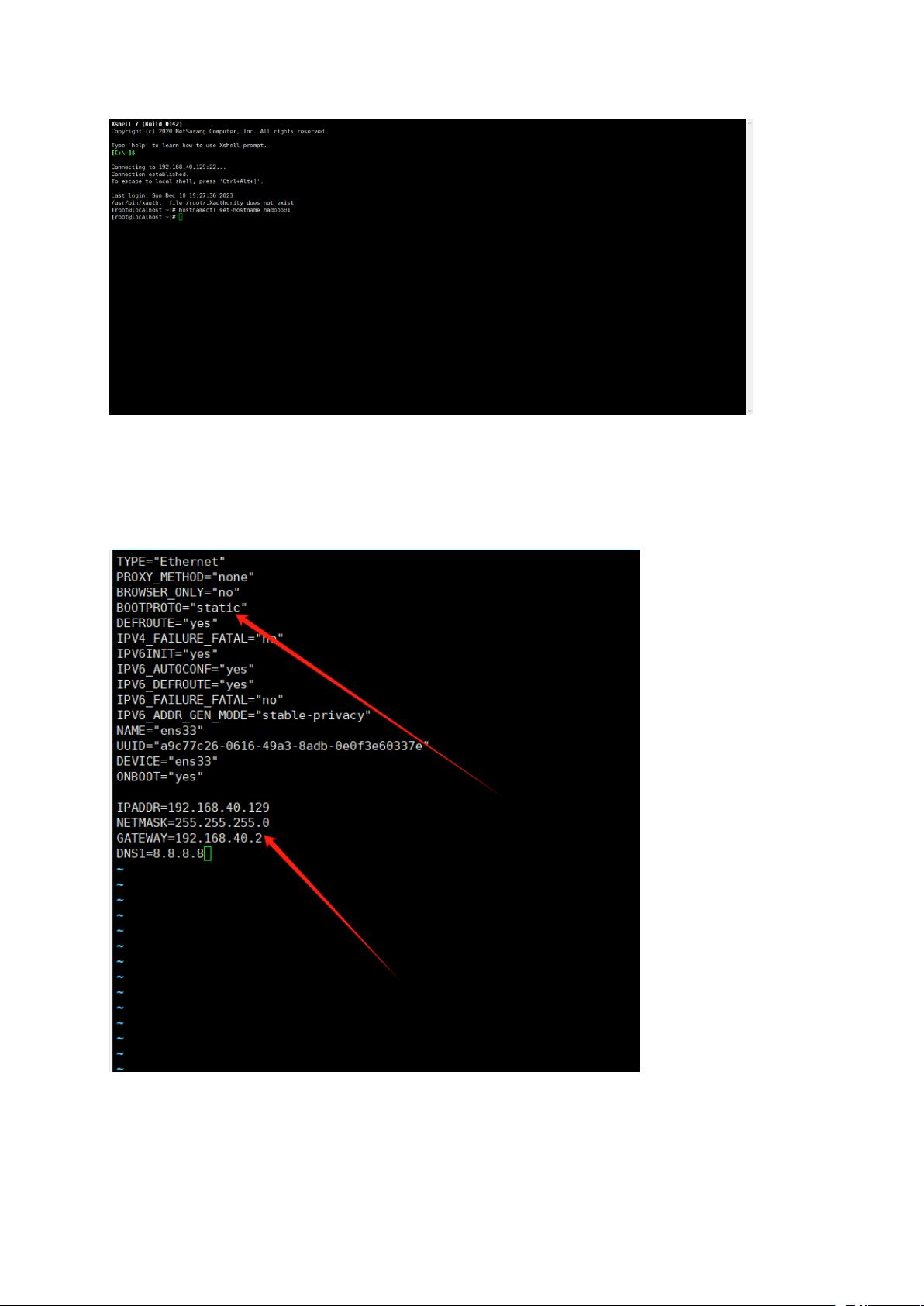
修改主机名
输入命令:hostnamectl set-hostname+主机名
剩余31页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2014-10-08 上传
2023-11-06 上传
2015-05-04 上传
2013-03-31 上传
2024-09-13 上传

緣黺
- 粉丝: 30
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







