TalkingData的Spark实践:从Hadoop到Spark的转型之路
25 浏览量
更新于2024-08-28
收藏 415KB PDF 举报
" TalkingData如何从使用Hadoop转向Spark的架构演进,以及在移动大数据平台建设中的实践经验。"
在大数据处理领域,Hadoop一直是重要的基石,但随着技术的不断发展,Spark以其高效、易用的特性逐渐崭露头角。这篇文章详细介绍了TalkingData在大数据平台建设过程中的转型,即从传统的Hadoop架构过渡到基于Spark的新架构。
Spark的核心优势在于它的内存计算模型,即弹性分布式数据集(RDD),这使得数据处理速度大幅提升,尤其在迭代计算和实时流处理中。与Hadoop MapReduce相比,Spark能够显著减少数据读写磁盘的次数,从而提高了整体性能。此外,Spark提供了丰富的组件,如Spark Streaming用于实时处理,MLlib支持机器学习算法,以及Spark SQL用于结构化数据处理,这些都极大地扩展了Spark的应用范围。
在TalkingData的实践中,他们发现Spark不仅在性能上超越了Hadoop,而且其生态系统更加全面,能够满足不断变化的业务需求。例如,Spark的Shark项目,尽管后来被Spark SQL取代,但它展示了Spark在处理SQL查询方面的潜力,这对于需要处理结构化数据的业务场景至关重要。
2014年,Spark在中国的影响力日益增强,SparkSummit China的召开和多个城市的Spark Meetup活动,表明了国内开发者和企业对Spark的强烈兴趣。TalkingData作为早期采用者,积极参与社区活动,分享其在Spark应用上的经验,这反映了Spark在实际业务中的成熟度和实用性。
在 TalkingData 的数据中心建设初期,面对海量的移动设备数据,他们需要一个强大的平台来处理、分析和挖掘这些数据。Spark的引入使得他们能够快速处理数据,进行复杂的分析任务,从而提取出有价值的洞察。通过Hadoop YARN作为资源管理系统,Spark能够在同一集群上与其他服务共存,实现了资源的有效利用和管理。
从Hadoop到Spark的转变,体现了大数据处理技术的进步和 TalkingData 对技术创新的追求。Spark的引入不仅提升了数据分析的效率,还为公司提供了更灵活、全面的大数据解决方案,以适应快速变化的移动互联网环境。这一实践对于其他正在考虑或正在进行大数据架构升级的企业具有重要的参考价值。
从从Hadoop到到Spark的架构实践的架构实践
本文则主要介绍TalkingData在大数据平台建设过程中,逐渐引入Spark,并且以Hadoop YARN和Spark为基础来构建移动大
数据平台的过程。
当下,Spark已经在国内得到了广泛的认可和支持:2014年,Spark Summit China在北京召开,场面火爆;同年,Spark
Meetup在北京、上海、深圳和杭州四个城市举办,其中仅北京就成功举办了5次,内容更涵盖Spark Core、Spark
Streaming、Spark MLlib、Spark SQL等众多领域。而作为较早关注和引入Spark的移动互联网大数据综合服务公
司,TalkingData也积极地参与到国内Spark社区的各种活动,并多次在Meetup中分享公司的Spark使用经验。本文则主要介绍
TalkingData在大数据平台建设过程中,逐渐引入Spark,并且以Hadoop YARN和Spark为基础来构建移动大数据平台的过
程。
初识Spark
作为一家在移动互联网大数据领域创业的公司,时刻关注大数据技术领域的发展和进步是公司技术团队必做的功课。而在整理
Strata 2013公开的讲义时,一篇主题为《An Introduction on the Berkeley Data Analytics Stack_BDAS_Featuring
Spark,Spark Streaming,and Shark》的教程引起了整个技术团队的关注和讨论,其中Spark基于内存的RDD模型、对机器学习
算法的支持、整个技术栈中实时处理和离线处理的统一模型以及Shark都让人眼前一亮。同时期我们关注的还有Impala,但对
比Spark,Impala可以理解为对Hive的升级,而Spark则尝试围绕RDD建立一个用于大数据处理的生态系统。对于一家数据量
高速增长,业务又是以大数据处理为核心并且在不断变化的创业公司而言,后者无疑更值得进一步关注和研究。
Spark初探
2013年中期,随着业务高速发展,越来越多的移动设备侧数据被各个不同的业务平台收集。那么这些数据除了提供不同业务
所需要的业务指标,是否还蕴藏着更多的价值?为了更好地挖掘数据潜在价值,我们决定建造自己的数据中心,将各业务平台
的数据汇集到一起,对覆盖设备的相关数据进行加工、分析和挖掘,从而探索数据的价值。初期数据中心主要功能设置如下所
示:
1. 跨市场聚合的安卓应用排名;
2. 基于用户兴趣的应用推荐。
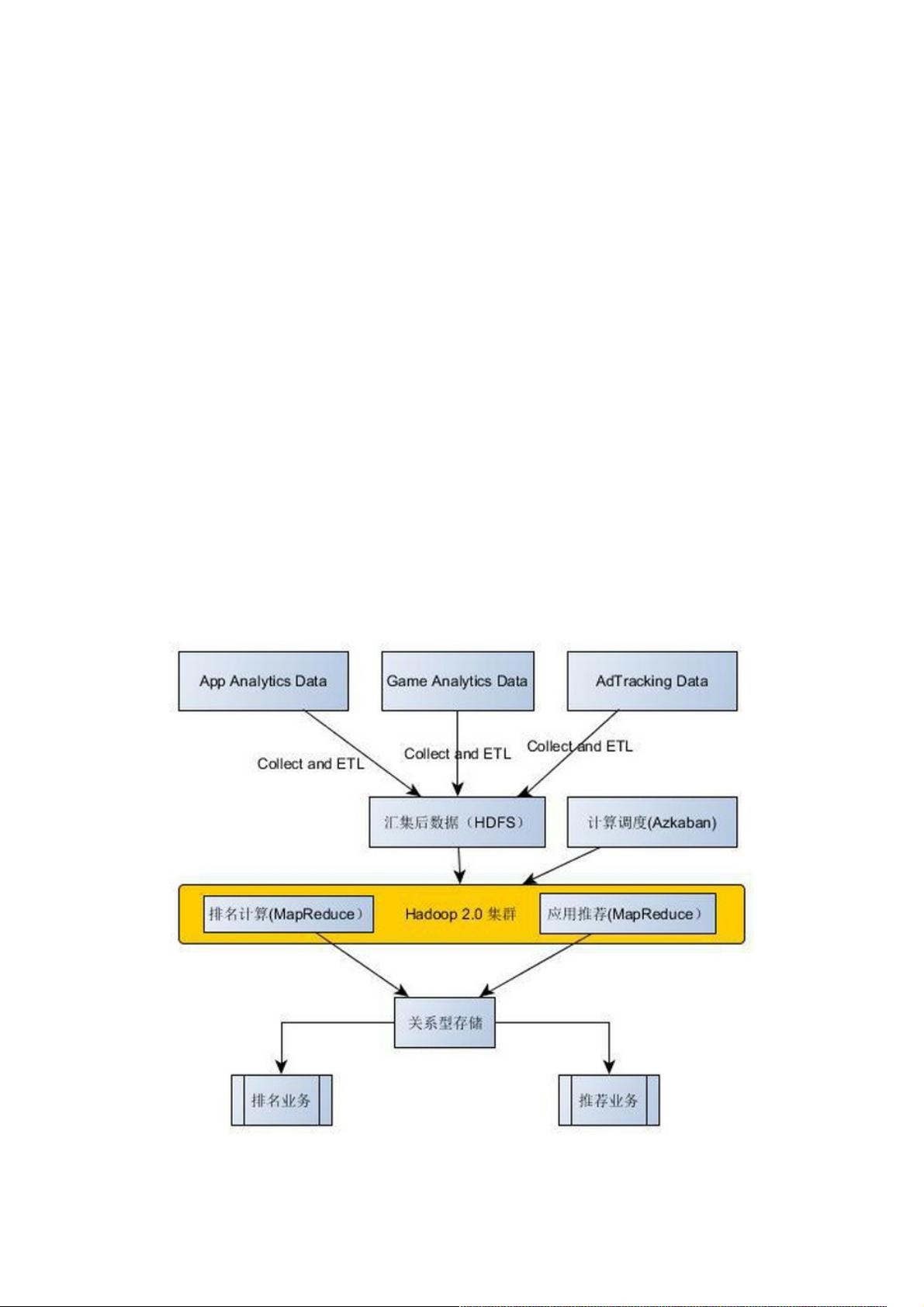
基于当时的技术掌握程度和功能需求,数据中心所采用的技术架构如图1。
图1 基于Hadoop 2.0的数据中心技术架构
整个系统构建基于Hadoop 2.0(Cloudera CDH4.3),采用了最原始的大数据计算架构。通过日志汇集程序,将不同业务平
台的日志汇集到数据中心,并通过ETL将数据进行格式化处理,储存到HDFS。其中,排名和推荐算法的实现都采用了
MapReduce,系统中只存在离线批量计算,并通过基于Azkaban的调度系统进行离线任务的调度。
下载后可阅读完整内容,剩余4页未读,立即下载
166 浏览量
2022-06-22 上传
2022-01-10 上传
2023-03-25 上传
2023-05-13 上传
2023-06-07 上传
2023-09-17 上传
2023-08-31 上传
2023-03-25 上传

只在当初微笑
- 粉丝: 275
- 资源: 866
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
