Python KMP算法详解:提升字符串匹配效率
PDF格式 | 702KB |
更新于2024-08-31
| 36 浏览量 | 举报
本文档深入探讨了Python描述数据结构中的一个重要概念——KMP算法。KMP算法,全称为Knuth-Morris-Pratt算法,是一种用于字符串匹配的高效方法,特别适用于在文本中查找特定模式。相比于简单的Brute-Force(BF)算法,KMP算法通过预处理模式串,减少了不必要的字符比较,从而显著提高了匹配效率。
首先,让我们回顾一下BF算法,它是最基础的匹配策略,通过逐个字符对比主串(S)和模式串(T),如果当前字符相等,就继续向后移动;如果不相等,则回溯主串指针,重新从模式串的头部开始匹配。这种方法虽然直观,但当模式串频繁出现回溯时,效率低下。
KMP算法的核心在于“部分匹配表”(也称作失配函数或跳转表)。在匹配过程中,当模式串发生不匹配时,不是简单地回溯,而是查看已匹配的字符序列,找到最长的公共前后缀长度,然后根据这个长度调整模式串的指针,跳过已匹配的部分,继续从模式串的下一个可能匹配位置进行搜索。这样,避免了不必要的回溯,大大提高了匹配速度。
以下是一个Python实现KMP算法的例子:
```python
def compute_prefix_table(pattern):
prefix_table = [0] * len(pattern)
j = -1
for i in range(1, len(pattern)):
while j != -1 and pattern[i] != pattern[j + 1]:
j = prefix_table[j]
if pattern[i] == pattern[j + 1]:
j += 1
prefix_table[i] = j
return prefix_table
def kmp_search(text, pattern):
prefix_table = compute_prefix_table(pattern)
j = 0
for i in range(len(text)):
while j != -1 and text[i] != pattern[j + 1]:
j = prefix_table[j]
if text[i] == pattern[j + 1]:
j += 1
if j == len(pattern) - 1:
return i - (j + 1) # 如果找到匹配,返回偏移量
return -1 # 如果未找到匹配,返回-1
# 示例
text = "ABACABABS"
pattern = "ABAB"
result = kmp_search(text, pattern)
```
总结来说,Python中的KMP算法是一个强大的工具,它利用预处理信息有效地管理字符串匹配过程,对于处理大量数据或需要高效搜索的应用场景尤其适用。通过学习和实践KMP算法,编程人员可以在Python编程中提高字符串处理的性能和效率。
浅谈浅谈Python描述数据结构之描述数据结构之KMP篇篇
主要介绍了Python描述数据结构之KMP篇,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学
习吧
前言前言
本篇章主要介绍串的KMP模式匹配算法及其改进,并用Python实现KMP算法。
1. BF算法算法
BF算法,即Bruce−ForceBruce-ForceBruce−Force算法,又称暴力匹配算法。其思想就是将主串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和T的
第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。
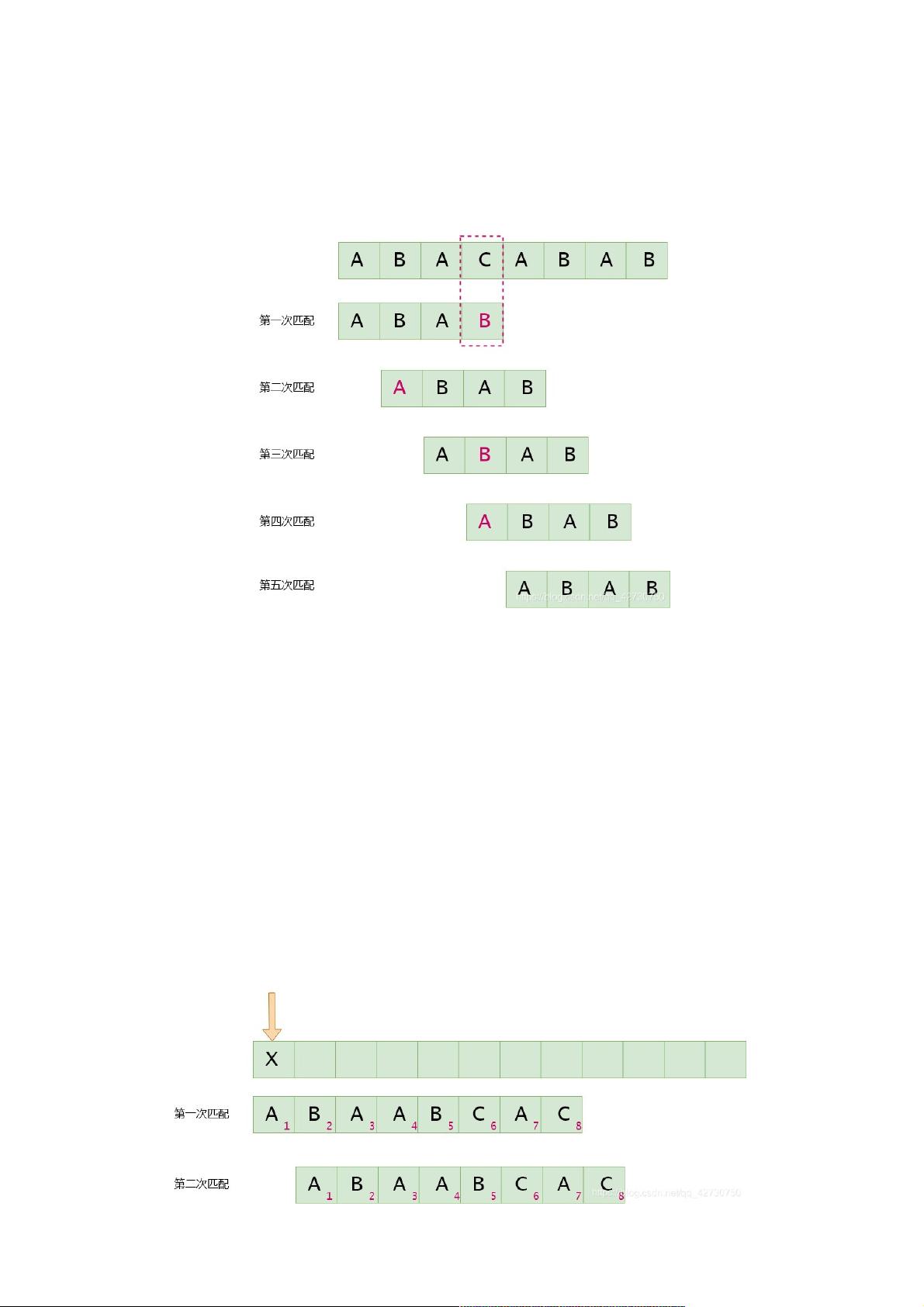
假设主串S=ABACABABS=ABACABABS=ABACABAB,模式串T=ABABT=ABABT=ABAB,每趟匹配失败后,主串S指针回溯,模式串指针回到头部,然后再次匹配,过程如下:
def BF(substrS, substrT):
if len(substrT) > len(substrS):
return -1
j = 0
t = 0
while j < len(substrS) and t < len(substrT):
if substrT[t] == substrS[j]:
j += 1
t += 1
else:
j = j - t + 1
t = 0
if t == len(substrT):
return j - t
else:
return -1
2. KMP算法算法
KMP算法,是由D.E.Knuth、J.H.Morris、V.R.PrattD.E.Knuth、J.H.Morris、V.R.PrattD.E.Knuth、J.H.Morris、V.R.Pratt同时发现的,又被称为克努特-莫里斯-普拉特算法。该算法的基本思
路就是在匹配失败后,无需回到主串和模式串最近一次开始比较的位置,而是在不改变主串已经匹配到的位置的前提下,根据已经匹配的部分字符,从模式串的某一位置开始继续进行串的模式
匹配。
就是这次匹配失败时,下次匹配时模式串应该从哪一位开始比较。
BF算法思路简单,便于理解,但是在执行时效率太低。在上述的匹配过程中,第一次匹配时已经匹配的"ABA""ABA""ABA",其前缀与后缀都是"A""A""A",这个时候我们就不需要执行第二次
匹配了,因为第一次就已经匹配过了,所以可以跳过第二次匹配,直接进行第三次匹配,即前缀位置移到后缀位置,主串指针无需回溯,并继续从该位开始比较。
前缀:是指除最后一个字符外,字符串的所有头部子串。
后缀:是指除第一个字符外,字符串的所有尾部子串。
部分匹配值(Partial(Partial(Partial Match,PM)Match,PM)Match,PM):字符串的前缀和后缀的最长相等前后缀长度。
例如,′a′'a'′a′的前缀和后缀都为空集,则最长公共前后缀长度为0;′ab′'ab'′ab′的前缀为{a}\{a\}{a},后缀为{b}\{b\}{b},则最长公共前后缀为空集,其长度长度为0;′aba′'aba'′aba′的前缀
为{a,ab}\{a,ab\}{a,ab},后缀为{a,ba}\{a,ba\}{a,ba},则最长公共前后缀为{a}\{a\}{a},其长度长度为1;′abab′'abab'′abab′的前缀为{a,ab,aba}\{a,ab,aba\}{a,ab,aba},后缀为{b,ab,bab}\{b,ab,bab\}
{b,ab,bab},则最长公共前后缀为{ab}\{ab\}{ab},其长度长度为2。
前缀一定包含第一个字符,后缀一定包含最后一个字符。
如果模式串1号位与主串当前位(箭头所指的位置)不匹配,将模式串1号位与主串的下一位进行比较。next[0]=-1,这边就是一个特殊位置了,即如果主串与模式串的第1位不相同,那么下次就直
接比较各第2位的字符。
下载后可阅读完整内容,剩余5页未读,立即下载
相关推荐







weixin_38506182
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++简单实现classloader及示例分析
- 快速掌握UICollectionView横向分页滑动封装技巧
- Symfony捆绑包CrawlerDetectBundle介绍:便于用户代理检测Bot和爬虫
- 阿里巴巴Android开发规范与建议深度解析
- MyEclipse 6 Java开发中文教程
- 开源Java数学表达式解析器MESP详解
- 非响应式图片展示模板及其源码与使用指南
- PNGoo:高保真PNG图像压缩新选择
- Android配置覆盖技巧及其源码解析
- Windows 7系统HP5200打印机驱动安装指南
- 电力负荷预测模型研究:Elman神经网络的应用
- VTK开发指南:深入技术、游戏与医学应用
- 免费获取5套Bootstrap后台模板下载资源
- Netgen Layouts: 无需编码构建复杂网页的高效方案
- JavaScript层叠柱状图统计实现与测试
- RocksmithToTab:将Rocksmith 2014歌曲高效导出至Guitar Pro
