大数据面试题资料:Hive内外部表区别及创建流程详解
200 浏览量
更新于2024-01-13
收藏 1.78MB DOC 举报
Hive是一个开源的数据仓库基础架构,用于将结构化数据映射到Hadoop上进行查询和分析。在Hive中,有内部表和外部表两种类型。
首先,我们来看一下Hive中内部表和外部表的区别。
内部表(Internal Table)是指在创建表时,Hive会将数据移动到指定的数据仓库路径下。换句话说,内部表的数据存储在Hive指定的路径下,与Hive内部表的元数据一起被删除。这意味着,如果删除了内部表,则数据也会被删除。内部表适用于那些数据不需要与外部共享,且需要严格控制数据的存放位置的情况。
外部表(External Table)是指创建表时,Hive只记录数据所在的路径,不对数据的位置做任何改变。也就是说,外部表的数据仍然存储在原来的位置,而Hive只是在元数据中记录了数据的位置。所以,删除外部表只会删除元数据,不会删除数据本身。外部表适用于那些数据需要与外部共享、或者数据存储在其他系统中的情况。
需要注意的是,Hive和传统数据库在表数据验证上存在一些差异。传统数据库通常采用"写时模式"(schema on write)进行数据验证,即在写入数据时检查数据是否符合表的结构。而Hive采用的是"读时模式"(schema on read),即在读取数据时才进行解析和验证数据的字段和结构。这使得Hive在加载数据时速度非常快,因为它不需要解析数据,只需复制或移动文件。而"写时模式"在提升查询性能方面具有优势,因为它可以预先解析数据并建立索引和压缩,但加载时间会增加。
接下来,我们来看一下Hive如何创建内部表。
Hive创建内部表的语法如下:
CREATE TABLE table_name(column1 data_type, column2 data_type, ...);
其中,table_name为表的名称,column1, column2等为表的列名和数据类型。
例如,创建一个名为test的内部表,列名为userid,数据类型为字符串:
CREATE TABLE test(userid string);
在创建表后,我们可以使用LOAD DATA语句将数据加载到内部表中:
LOAD DATA INPATH 'hdfs_path' INTO TABLE table_name;
其中,hdfs_path为数据所在的路径,table_name为要将数据加载进的表名。
综上所述,Hive内部表和外部表的区别在于数据存放的位置和删除的行为。内部表将数据移动到Hive指定的路径,并且删除表时会同时删除元数据和数据,而外部表只记录数据的路径,删除表时只会删除元数据。此外,Hive采用的是读时模式,提高了加载数据的速度,但查询性能可能会受到影响。创建内部表时,需要定义表的结构和数据类型,并通过LOAD DATA语句将数据加载到表中。
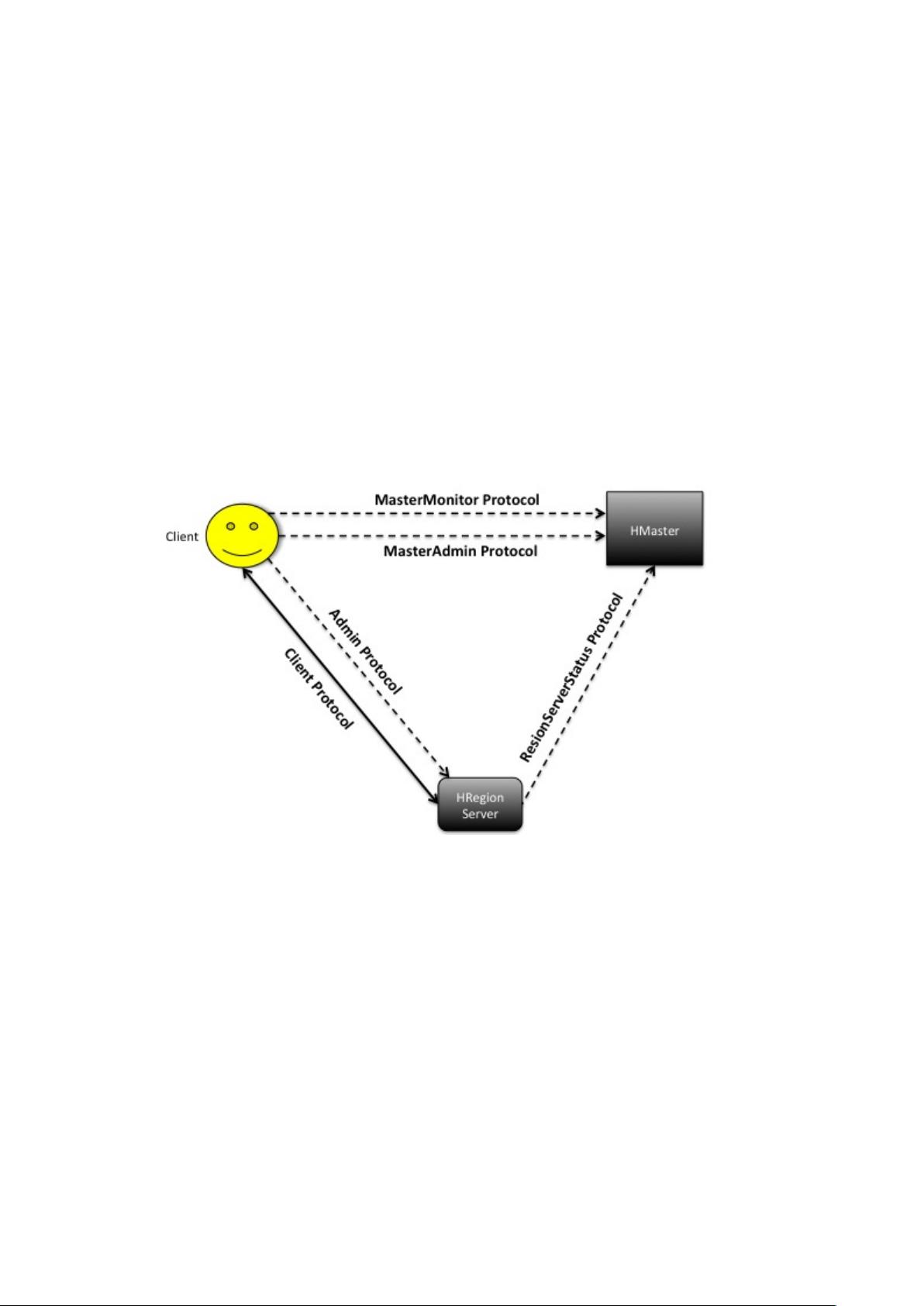
scan、bulkLoadHFile、执行
Coprocessor 等。
AdminProtocols,Client 与
RegionServer 之间的通信,
RegionServer 是 RpcServer
端,主要实现 Region、服务、
文件的管理。例如 storefile 信
息、Region 的操作、WAL 操
作、Server 的开关等。
(备注:以上提到的 Client 可
以是用户 Api、也可以是
RegionServer 或者 HMaster)
HBase-RPC 实现机制
分析
RpcServer 配置三个队列:
1)普通队列 callQueue,绝大
部分 Call 请求存在该队列中:
callQueue 上



剩余83页未读,继续阅读
2022-12-24 上传
2020-09-15 上传
2022-12-24 上传
2019-07-09 上传
2019-07-09 上传
2007-06-27 上传
2019-09-13 上传

zzzzl333
- 粉丝: 809
- 资源: 7万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- sls-nodejs-template:具有ES6语法的无服务器模板
- Santander Product Recommendation 桑坦德产品推荐-数据集
- Zigbee-CC2530实验03SYSCLOCK&POWERMODE实现睡眠定时器
- stocks-ticker:电子垂直股票代号
- grow-together:寻求向孩子介绍新技术,人文和文化的新颖方法
- 软件串口监视AccessPort
- Accuinsight-1.0.5-py2.py3-none-any.whl.zip
- GUI 中的拖动线:GUI 中的线可以拖动-matlab开发
- TextEncryption
- A3JacobDumas.appstudio
- Horiseon:地平线
- 串口通讯ET 200S 1SI模块应用范例.rar
- Nicky Jam Search-crx插件
- SymbolsVideo:SVG中的Symbols视频触发器
- C#桌面程序 获取机器码(CPU信息+硬盘信息+网卡信息)
- US Candy Production by Month 美国糖果月产量-数据集
