大规模数据处理与HDFS详解
需积分: 9 84 浏览量
更新于2024-07-22
收藏 574KB PDF 举报
"本文主要介绍了大数据处理方案,重点关注大规模数据存储和分析,特别是Lustre和HDFS两种分布式文件系统,以及MPI和MapReduce在大规模数据分析中的应用。同时,通过百度的应用实践,展示了实际场景中遇到的问题及对策。"
大数据处理涉及到对海量数据的存储、索引和分析。在大规模数据存储方面,Lustre和HDFS是两个重要的系统。Lustre以其高性能和可扩展性被广泛应用于科研和高性能计算领域,特点是硬件不易故障,适合于对随机访问性能要求高的场景,但规模通常小于1PB,并且在节点失效后,部分数据可能无法访问。
相比之下,Hadoop的HDFS设计前提是硬件容易故障,但系统具备强大的容错机制,即使节点失效也能持续提供服务,规模可扩展至EB级别。HDFS采用主从架构,由一台Namenode负责元数据管理,多台Datanodes存储实际数据,并通过Replication实现数据冗余,确保高可用性。其优势在于支持海量存储、全局命名空间、高可用性和扩展性,同时兼容MapReduce编程框架。然而,HDFS的随机读性能较弱,且存在Namenode单点故障的问题。在面对大量小文件时,Namenode可能会面临内存压力。
百度在实际应用中,面对超过20PB的数据存储和每日10TB的数据增量,遇到了Namenode的容量和性能瓶颈,以及数据安全问题。为此,百度采取了包括分布式NameNode、访问权限控制和故障硬盘自动发现与淘汰在内的策略,以应对这些挑战。
在大规模数据分析方面,Message Passing Interface (MPI) 是一种传统的并行计算模型,适用于数据相关性强、迭代次数多的计算任务,而MapReduce是Google提出的分布式计算框架,尤其适合处理和生成大规模数据集。Map阶段将数据拆分成键值对进行独立处理,Reduce阶段则将结果聚合,简化了处理复杂数据的过程。尽管MapReduce在大数据处理中表现出色,但它不适用于实时计算和低延迟需求,且对于数据相关性不强的任务效率较低。
总结来说,大数据处理的关键在于选择合适的存储和计算框架,如Lustre和HDFS用于数据存储,MPI和MapReduce用于数据分析。同时,随着数据量的增长,需要解决如Namenode瓶颈、数据安全和硬件故障等问题,以确保系统的稳定和高效运行。
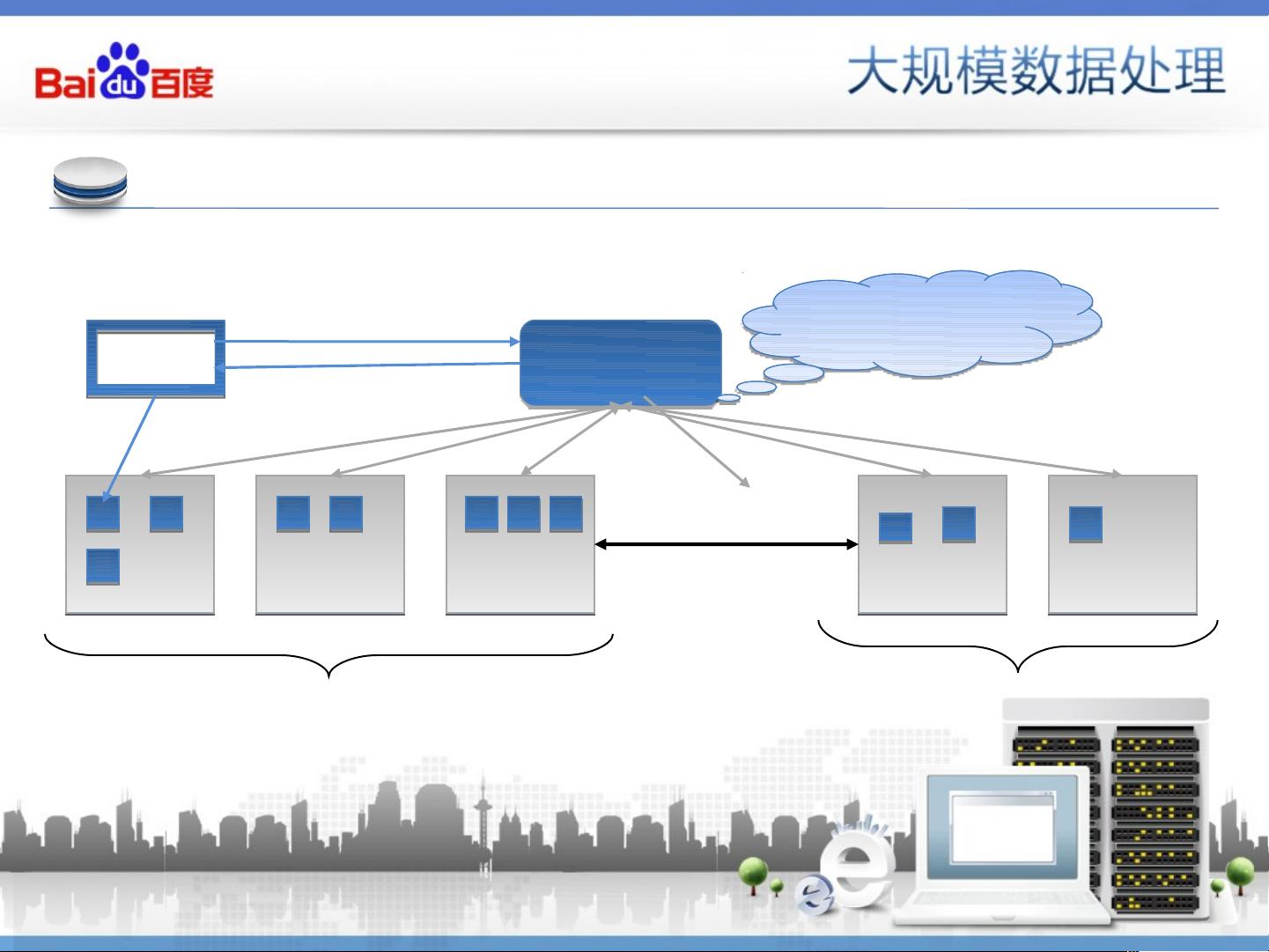
系统结构
主从架构 :1 台 Namenode ,多台 Datanodes
Namenode
Datanode
Replication
Metadata
(Name, replicas, …)
(/foo/data, 3, …)
f
Datanode
Datanode
Datanode Datanode
Rack 1 Rack 2
Client
Where is
f?
R1D1, R1D2,
R2D1
f
f
yahoo 最大的 Hadoop 集群包含节点 4000 台
;所有 Hadoop 集群节点总共一万台
剩余19页未读,继续阅读

lzd1007
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 简介
- ArcGIS_Engine_C#实例开发教程+源码(超值)
- 矩阵理论全套课件PPT (北航、北理、清华、北邮).rar
- project-1 2.0
- RobusTest-crx插件
- 1个
- ML_Projects
- TCP服务器完整源码(基于IOCP实现) v1.4-易语言
- Prolific USB-to-Serial Comm Port
- Delphi7-SQLMemTable 多线程修改内存表 例子.rar
- 二维码识别工具.zip
- Stashio [URL Saver]-crx插件
- rest_pistache
- TIC
- docusaurus-netlifycms:docusaurs和Netlify CMS的简单实现
- Trainual-crx插件
