Apache Drill教程:schema-free SQL引擎详解
需积分: 10 72 浏览量
更新于2024-07-15
收藏 1.37MB PDF 举报
Apache Drill教程
Apache Drill是一款重要的开源SQL查询引擎,与Hadoop生态系统紧密集成但不依赖其底层MapReduce框架。它被誉为Apache Sqoop的升级版本,灵感来源于Google的Dremel项目(BigQuery),旨在提供一个灵活、高性能的分析工具,适用于大数据环境。Drill的设计目标是实现“schema-on-read”,这意味着在查询时才动态解析数据结构,提供了更为简洁的SQL语法和实时分析能力。
本教程涵盖了Apache Drill的基础知识,包括但不限于:
1. **概念介绍**:Drill作为一个灵活的查询引擎,它的独特之处在于它不需要复杂的Hadoop MapReduce作业,而是采用轻量级架构。这使得Drill成为处理大规模数据集的理想选择,特别是对于实时查询和交互式分析。
2. **安装与配置**:教程会引导读者了解如何在系统上安装和配置Apache Drill,包括必要的软件和硬件准备,以及设置环境变量和配置文件。
3. **SQL操作**:通过实践,读者将学习如何使用Drill进行基础的SQL查询,包括对JSON数据的支持,这在大数据技术如HDFS(Hadoop分布式文件系统)和HBase(列式存储数据库)中尤为关键。
4. **大数据技术整合**:教程将展示如何利用Drill与Big Data平台协同工作,确保数据的高效查询和分析。
5. **应用场景**:最后,将探讨Drill在实际场景中的应用,如实时报告、数据仓库和ETL(提取、转换、加载)工作流中的角色,以及如何优化性能。
本教程主要面向希望在大数据分析领域发展的专业人士,提供了一套全面的学习路径,帮助他们深入理解Drill的工作原理,掌握其在实际项目中的使用技巧。为了顺利进行,读者需要具备一定的Java编程基础、JSON知识和Linux操作系统经验。所有内容和图形版权归属于TutorialsPoint(I)Pvt. Ltd.,用户应遵守相关版权和免责声明。
Apache Drill
15
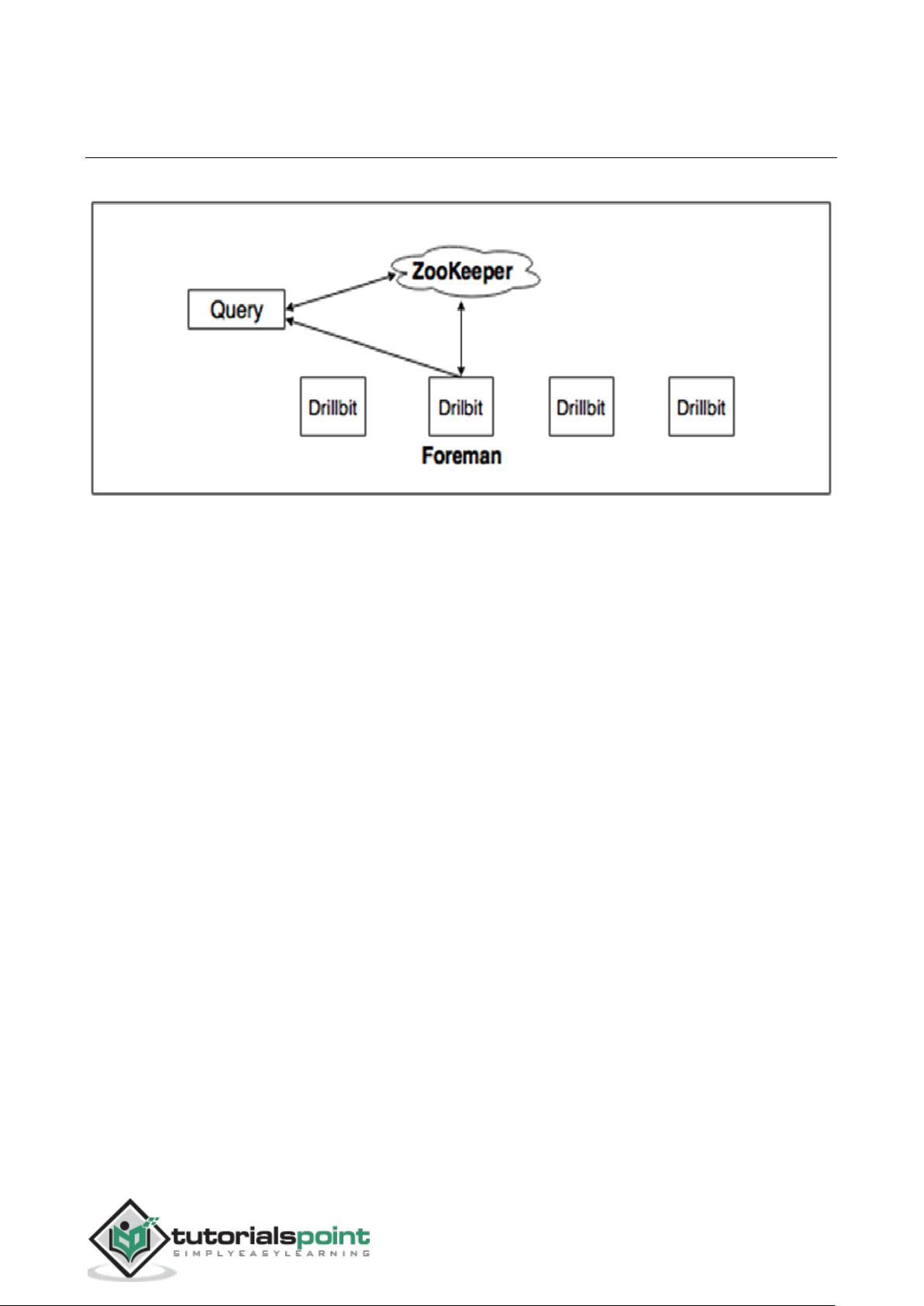
Query Execution Diagram
The following image shows a DrillBit query execution diagram:
The above diagram involves the following steps –
The Drill client issues a query. Any Drillbit in the cluster can accept queries from
clients.
A Drillbit then parses the query, optimizes it, and generates an optimized distributed
query plan for fast and efficient execution.
The Drillbit that accepts the initial query becomes the Foreman (driving Drillbit) for
the request. It gets a list of available Drillbit nodes in the cluster from ZooKeeper.
The foreman gets a list of available Drillbit nodes in the cluster from ZooKeeper and
schedules the execution of query fragments on individual nodes according to the
execution plan.
The individual nodes finish their execution and return data to the foreman.
The foreman finally returns the results back to the client.



剩余97页未读,继续阅读
2019-12-17 上传
2021-10-08 上传
2021-11-07 上传
2023-05-10 上传
2009-05-07 上传
2022-02-28 上传
2021-07-31 上传

PanPan_003
- 粉丝: 14
- 资源: 70
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
