深度学习RNN与LSTM算法解析及应用
"RNN+LSTM学习资料.pptx"
本文主要介绍的是深度学习中的两种重要模型——循环神经网络(Recurrent Neural Network, RNN)和长短时记忆网络(Long Short-Term Memory, LSTM),它们在自然语言处理任务中的应用和原理。这两种模型在处理序列数据时具有独特的优势,因为它们能够捕获上下文信息,而不仅仅是依赖于当前的输入。
RNN的基本思想是利用循环结构来处理序列数据,使得网络在每个时间步(t)不仅依赖于当前的输入(x_t),还依赖于之前的时间步的记忆状态(h_{t-1})。这种设计使得RNN适合处理如语言建模的任务,即在已知前n个词的情况下,预测下一个词。然而,标准RNN存在梯度消失或爆炸的问题,导致它难以捕捉长期依赖。
LSTM为解决RNN的问题而提出,通过引入门控机制(输入门、遗忘门和输出门)来更好地管理长期记忆。在LSTM中,记忆单元(c_t)允许信息在长时间内保留,同时通过门控机制决定何时清除或添加信息。这使得LSTM在处理如文本分类、机器翻译等任务时表现出色,尤其在需要考虑远距离依赖的场景下。
在训练RNN和LSTM时,通常使用反向传播通过时间(BackPropagation Through Time, BPTT)来计算损失函数对参数的梯度。由于序列的长度,BPTT会在时间轴上反向传播,更新参数以最小化损失,例如使用交叉熵损失函数进行词的预测。此外,LSTM在处理多模态任务时,如结合图像信息,可以在第一步提取图像特征,然后在后续的RNN步骤中仅使用文本信息,最后的输出用于预测特定的信号,如[endtoken]。
RNN和LSTM在AI领域的应用广泛,包括但不限于自然语言生成、情感分析、语音识别等。它们能够处理变长的输入序列,并且通过内部的记忆机制,能够有效地学习和利用序列中的上下文信息。然而,尽管LSTM在一定程度上缓解了长距离依赖的问题,但依然存在挑战,例如注意力机制(Attention Mechanism)的引入进一步改善了模型在处理长序列时的能力。
RNN和LSTM是深度学习中处理序列数据的重要工具,它们的设计允许模型在时间序列中捕获动态信息,特别适合于自然语言处理和相关领域。通过理解其工作原理和优化技巧,如BPTT和LSTM的门控机制,我们可以更好地应用于实际问题,提升模型性能。
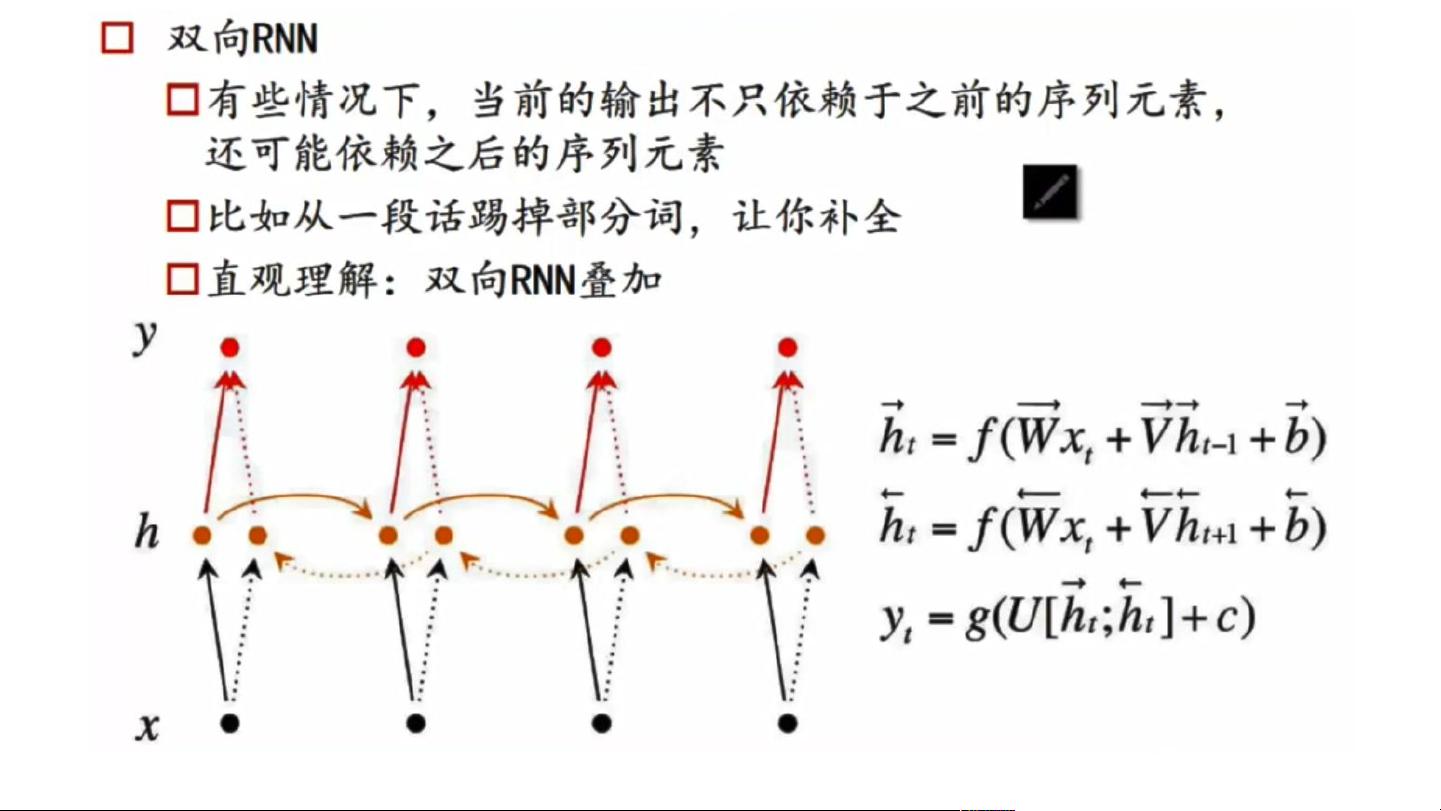
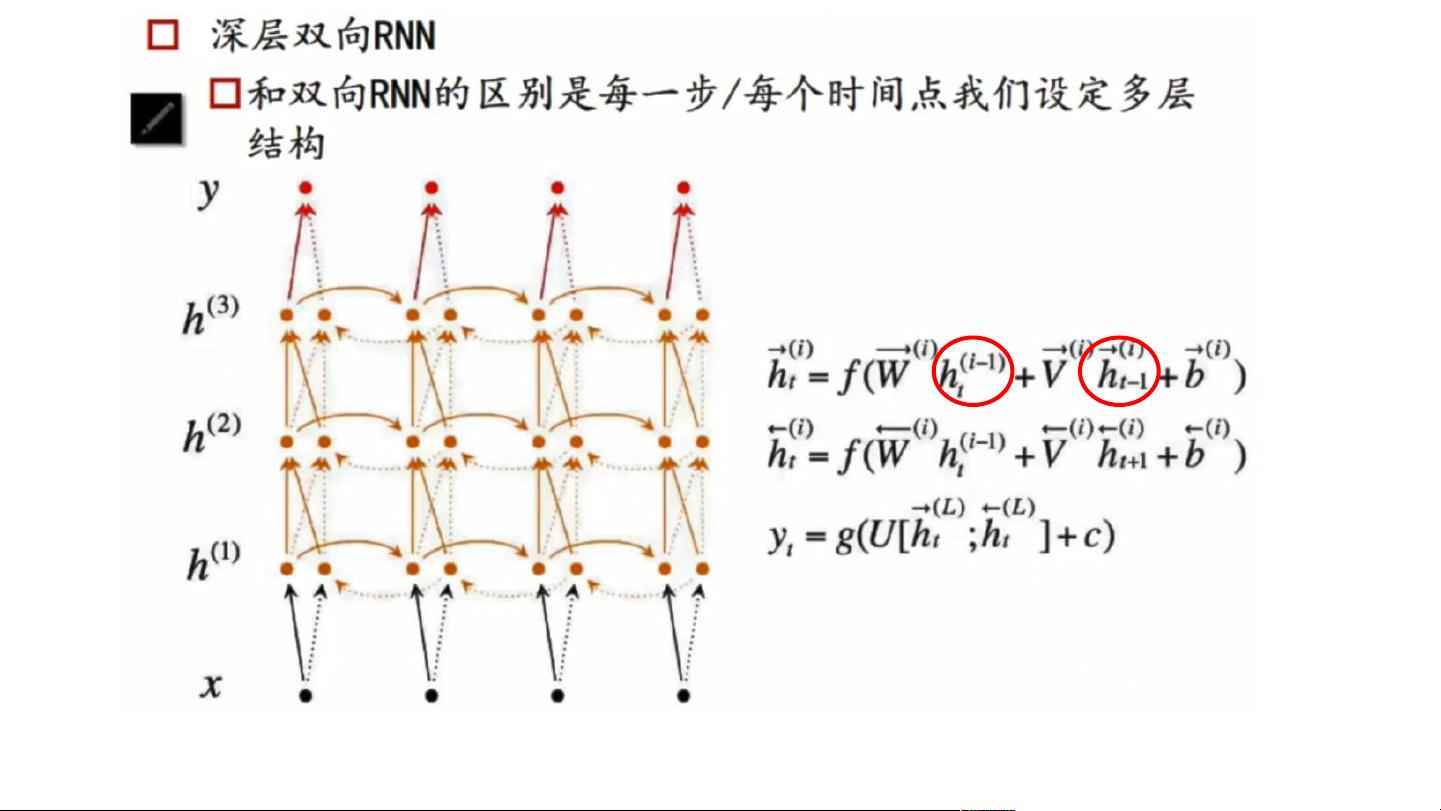
两个 memory 做拼接
不一样的 W 和 V 让它捕捉更多信
息
剩余31页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-04-09 上传
2021-10-05 上传
2021-10-17 上传
2023-04-23 上传
2024-04-24 上传

智享AI
- 粉丝: 150
- 资源: 30
 我的内容管理
展开
我的内容管理
展开







最新资源
- 随机电压发生器设计(仿真电路+含VB上位机+程序)-电路方案
- 测试git仓库
- psplinklauncher-开源
- express+mysql+vue,从零搭建一个商城管理系统6-数据校验和登录
- home
- ember-computed-injection:将 Ember 容器中的任何内容作为属性注入任何类。 (即有点像对其他一切的“需求”)
- eclipse CheckStyle
- kattus-real-estate
- scrumPokerTool
- SC PreProcessor-开源
- HideYoElfHideYoBytes:此C程序将检查ELF文件中是否在程序段之间插入了字节
- Android应用程序图标动画效果源代码
- react-atomshell-spotify:使用 Atom Shell、React 和 Babel 探索桌面应用程序
- 基于AT89S52单片机的步进电机驱动(原理图+程序)-电路方案
- swift-base58:快速实施base58
- CDNSearcher:Alfred工作流程更快地包含bootcdncdnjs文件
