Python爬虫深度解析:框架与库详解(Urllib, requests, Scrapy, Selenium)
需积分: 9 71 浏览量
更新于2024-07-18
收藏 27.97MB DOCX 举报
Python爬虫学习记录是一篇详细的指南,旨在帮助初学者掌握Python爬虫开发的关键技术和工具。本文涵盖的主要内容包括但不限于以下几个方面:
1. **基础库的理解**:
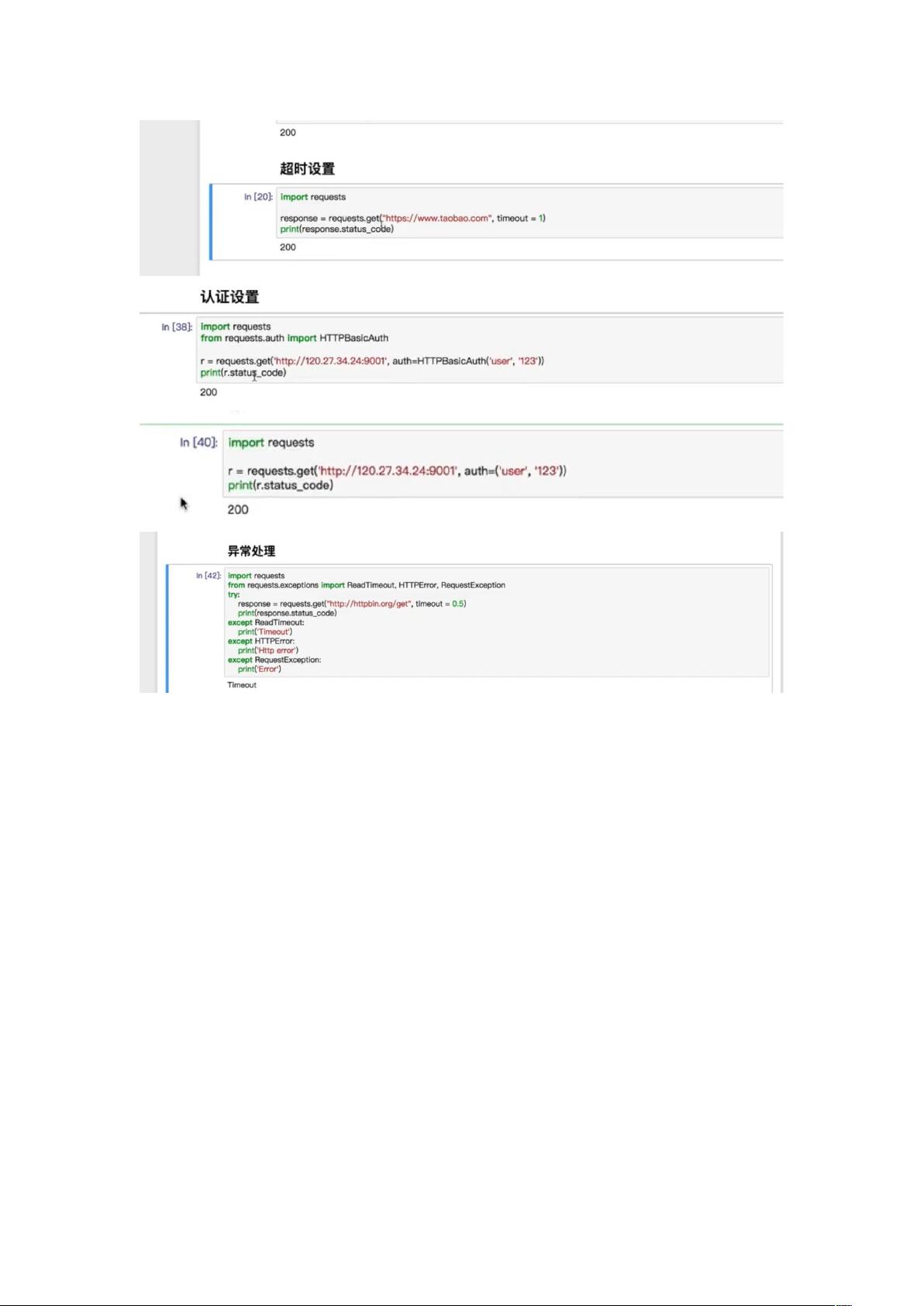
- `Urllib`:是Python的标准库之一,主要用于发送HTTP请求,特别是`request.get()`方法用于加载静态HTML内容,适用于初次接触爬虫时的基本网络请求。
2. **处理JavaScript渲染**:
- 当遇到动态网页时,需要识别并模拟Ajax请求。`Selenium`和`Webdriver`提供模拟浏览器行为的能力,如控制浏览器、解析动态加载的内容。
- `Splash` 是一个轻量级的HTTP渲染服务,它可以在服务器端预渲染页面,返回静态HTML,便于爬虫抓取。
3. **数据存储**:
学习如何保存抓取的数据,这通常涉及到文件操作、数据库存储或API接口集成。
4. **进阶库应用**:
- `Requests`:强大的HTTP库,用于发送各种HTTP请求,支持会话管理和Cookie管理。
- 正则表达式:在数据提取中扮演重要角色,用于解析HTML文档,提取特定模式的信息。
5. **BeautifulSoup`和`PyQuery`**:
- `BeautifulSoup` 是解析HTML和XML的强大库,通过标签选择器、标准选择器和CSS选择器进行DOM操作。
- `PyQuery` 类似jQuery,提供了简洁的API来处理HTML文档。
6. **Selenium深度解析**:
- 官方文档介绍,如何声明浏览器、导航、元素定位、多元素处理、交互操作,以及执行JavaScript代码和处理Frame结构。
- 异常处理和浏览器操作的高级功能,如前进后退、Cookies管理和选项卡管理。
7. **实战应用**:
- 通过结合`Requests`和正则表达式爬取猫眼电影数据,展示了进程池在爬虫中的实际应用。
8. **Scrapy框架**:
- 介绍如何安装和使用Scrapy,这是一个强大的分布式爬虫框架,适合处理大型、复杂的爬虫项目。
- 包括创建项目、测试站点以及流程设置,如spiders、pipelines、中间件等关键组件。
这篇Python爬虫学习记录是一份全面的教程,涵盖了从基础库到高级框架的实用技能,通过一系列实例让读者逐步掌握Python爬虫开发的核心技术。

剩余46页未读,继续阅读
2021-08-18 上传
2023-01-29 上传
2022-03-09 上传
2022-07-24 上传
2024-02-21 上传
2022-09-10 上传
2020-09-21 上传

cuit_cc
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- AgileZap
- TagUI:创建TagUI示例以提高生产率
- generator-sails-plugin-hook:Yoeman 生成器创建帆钩,将其自身插入帆结构中
- 毕业设计&课设--趁早(quickearly)早餐外卖微信小程序--方便面的毕业设计.zip
- matlab-(含教程)基于sift特征提取的图像配准和拼接算法matlab仿真
- Excel模板00固定资产明细账.zip
- Hotel-Management-System:Django中的酒店管理系统
- dotfiles:我的dotfiles
- pscc2015:Capstone 2015 - 来自 KUB 与 PSTCC 的合作
- tlvc-api
- 毕业设计&课设--车辆管理系统本科毕业设计,php+mysql+python.zip
- matlab-(含教程)基于传感器融合(UWB+IMU+超声波)的卡尔曼滤波多点定位算法matlab仿真
- Excel模板收据打印模板.zip
- swipe-listener:零依赖性,最小化手势手势的Web侦听器
- chittiBirthday:学习NodeJS和Google云
- github-issue-agent:使用带有令牌的 Github 问题基础结构的 Node.js 项目
