强化学习与适应性控制:CS229课程笔记
需积分: 12 7 浏览量
更新于2024-07-19
收藏 681KB PDF 举报
"这篇资源是关于CS229课程的强化学习与控制部分的精华笔记,由吴恩达(Andrew Ng)原创,并由CycleUser翻译。笔记主要探讨了在缺乏明确监督的情况下,如何通过奖励函数进行学习和决策,特别是在连续决策和控制问题中的应用。强化学习的一个关键概念是马尔可夫决策过程(Markov Decision Processes,MDP),它是解决此类问题的基础框架。"
在强化学习中,与监督学习不同,我们不再拥有预先定义的正确答案,而是通过一个奖励函数来指导学习过程。例如,在训练一个四足机器人行走时,因为没有具体告诉机器应该如何行动,所以我们不能提供直接的监督。相反,我们设定一个奖励函数,当机器人的行为表现出进步时给予正向奖励,退步或失败时给予负向奖励,这样,学习算法就能逐步找到获得最大奖励的最佳行动策略。
马尔可夫决策过程(MDP)是强化学习的基础模型,它由五个主要元素构成:
1. **状态集(State Space, S)**: 这是所有可能系统状态的集合,比如机器人在不同位置和姿势的状态。
2. **动作集(Action Space, A)**: 代表学习代理可以执行的所有可能操作。
3. **状态转移概率(Transition Probabilities, {Psa})**: 定义了从状态s执行动作a后转移到新状态s'的概率。
4. **折扣因子(Discount Factor, γ)**: 用来平衡即时奖励和长期奖励的重要性,通常取值在0到1之间,0表示只考虑当前奖励,1表示考虑无限未来奖励。
5. **奖励函数(Reward Function, R)**: 为每个状态转移(s, a, s')提供一个奖励值,指导学习过程。
MDP的目的是找到一个策略(Policy),即在给定状态下选择动作的规则,以最大化未来的累积奖励,也就是著名的贝尔曼期望最优方程(Bellman Optimality Equation)。策略可以是确定性的(deterministic)或随机的(stochastic),并且可以通过动态规划、蒙特卡洛方法或Temporal Difference Learning等技术进行优化。
强化学习已经在多个领域展现出强大的应用潜力,如无人机自主飞行、机器人运动控制、网络选择、市场营销、工厂自动化以及网页索引等。随着深度学习的发展,结合深度Q网络(Deep Q-Networks, DQN)等技术,强化学习在解决复杂环境中的决策问题上取得了显著进展,如Atari游戏的自动游玩和AlphaGo在围棋上的胜利。通过不断探索和改进强化学习算法,我们可以期待在未来看到更多智能系统在实际问题中展现出更高级别的自主学习和决策能力。

1
实际上这里我们用 π 这个记号来表示,严格来说不太正确,因为 π 并不
是一个随机变量,不过在文献里面这样表示很多,已经成了某种事实上的标
准了。
给定一个固定的策略函数(policy) π,则对应的值函数 V
π
满足贝尔曼等式(Bellman equations):
This says that the expected sum of discounted rewards V
π
(s) for
starting in s consists of two terms: First, the immediate reward R(s)
that we get rightaway simply for starting in state s, and second, the
expected sum of future discounted rewards. Examining the second
term in more detail, we see that the summation term above can be
rewritten E
s
ʹ
∼P
sπ(s)
[V
π
(s
ʹ
)]. This is the expected sum of discounted
rewards for starting in state s
ʹ
, where s
ʹ
is distributed according
P
sπ(s)
, which is the distribution over where we will end up after
taking the first action π(s) in the MDP from state s. Thus, the
second term above gives the expected sum of discounted rewards
obtained after the first step in the MDP.
这也就意味着,从状态 s 开始的这个部分奖励(discounted
rewards)的期望总和(expected sum) V
π
(s) 由两部分组成:
首先是在状态 s 时候当时立即获得的奖励函数值 R(s),也就
是上面式子的第一项;另一个就是第二项,即后续的部分奖励
函数值(discounted rewards)的期望总和(expected sum)。
对第二项进行更深入的探索,就能发现这个求和项
(summation term)可以写成 E
s
ʹ
∼P
sπ(s)
[V
π
(s
ʹ
)] 的形式。这种形
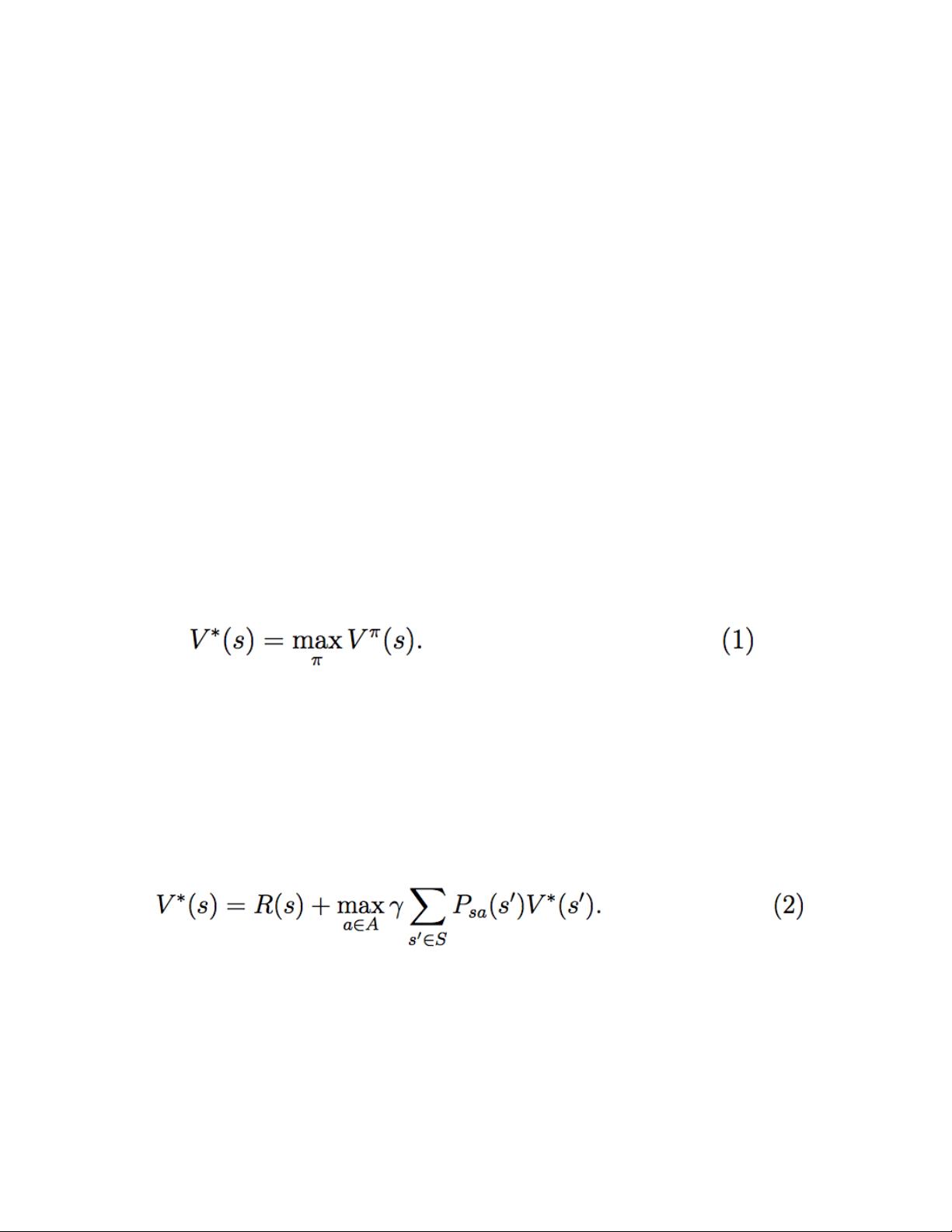
剩余25页未读,继续阅读
2016-03-28 上传
2017-11-21 上传
2017-12-06 上传
2023-10-01 上传
2023-07-04 上传
2023-06-05 上传
2023-07-30 上传
2023-05-13 上传
2023-07-27 上传

qihuai8860
- 粉丝: 2
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
