联邦学习:隐私与鲁棒性的挑战与对策
需积分: 49 92 浏览量
更新于2024-07-15
2
收藏 2.15MB PDF 举报
"联邦学习中的隐私和鲁棒性:攻击与防御"
随着信息技术的快速发展,数据隐私和安全性成为了人们关注的焦点。联邦学习(Federated Learning, FL)作为一种分布式机器学习方法,旨在解决数据孤岛问题,允许在不共享原始数据的情况下进行模型训练。然而,联邦学习并非完全无懈可击,其协议设计存在被内外部攻击者利用的风险,从而威胁到数据隐私和系统的鲁棒性。
一、联邦学习基础
联邦学习的核心理念是将数据保留在本地设备上,通过协作学习的方式构建全局模型。这种方法既能保护用户数据的隐私,又能利用分布式数据集的优势提高模型性能。然而,由于通信过程和模型交换的存在,FL系统面临着一系列的安全挑战。
二、威胁模型
威胁模型是理解联邦学习安全问题的基础。这些模型通常分为诚实但好奇(Curious but Honest)、恶意(Malicious)和半诚实(Semi-Honest)等类型,它们描述了攻击者可能的行为模式和能力。例如,诚实但好奇的参与者可能会尝试从共享信息中推断出敏感信息,而恶意参与者则可能篡改或操纵数据以破坏学习过程。
三、针对鲁棒性的攻击与防御
1. 污染攻击(Poisoning Attacks):攻击者可能通过注入恶意样本来影响模型的训练过程,导致模型偏离正确方向。防御策略包括数据验证、异常检测以及使用鲁棒优化算法。
2. 蠕虫洞攻击(Wormhole Attacks):攻击者可以控制多个参与节点,形成内部协同攻击,影响模型收敛。防御策略涉及节点验证和信誉系统,以减少恶意节点的影响。
四、针对隐私的攻击与防御
1. 推理攻击(Inference Attacks):攻击者通过观察模型参数或输出来推测用户的敏感信息。防御策略包括差分隐私技术,如添加噪声到梯度更新,以及同态加密,以保护通信过程中的信息安全。
2. 侧信道攻击(Side-Channel Attacks):攻击者利用系统资源使用情况等信息来揭示用户数据。应对措施包括使用安全硬件模块和优化的通信协议来减少信息泄露。
五、未来挑战与发展方向
尽管已有许多研究致力于提高联邦学习的隐私和鲁棒性,但仍有大量工作待完成。这包括设计更高效的安全协议、开发适应不同威胁模型的防御机制,以及实现跨设备和跨平台的联邦学习框架。此外,如何在保障隐私的同时保持模型性能,以及如何在大规模分布式系统中实施安全策略,都是未来的研究重点。
联邦学习中的隐私和鲁棒性问题需要多角度的考虑和创新解决方案。只有这样,才能确保这一新兴技术在实际应用中既有效又安全。
4
TABLE 2: A summary of attacks against server-based FL.
Attack Type
Attack Target Attacker Role FL Scenario Attack Complexity
Model Training Data Participant Server H2B H2C Attack Iteration Auxiliary Knowledge Required
One Round Multiple Rounds
Data Poisoning YES NO YES NO YES YES YES YES YES
Model Poisoning YES NO YES NO YES NO YES YES YES
Infer Class Representatives NO YES YES YES YES NO NO YES YES
Infer Membership NO YES YES YES YES NO NO YES YES
Infer Properties NO YES YES YES YES NO NO YES YES
Infer Training Inputs and Labels NO YES NO YES YES NO YES YES NO
2.3 Training Phase v.s. Inference Phase
Training Phase. Attacks conducted during the training
phase attempt to learn, influence, or corrupt the FL model it-
self [51]. During the training phase, the attacker can run data
poisoning attacks to compromise the integrity of the training
dataset [26], [28], [52], [53], [54], or model poisoning attacks
to compromise the integrity of the learning process [27], [55].
The attacker can also launch a range of inference attacks
on an individual participant’s update or on the aggregated
update from all participants.
Inference Phase. Attacks conducted during the inference
phase are called evasion/exploratory attacks [56]. They
generally do not alter the targeted model, but instead, either
trick it to produce wrong predictions (targeted/untargeted)
or collect evidence about the model characteristics. The
effectiveness of such attacks is largely determined by the
information that is available to the adversary about the
model. Inference phase attacks can be classified into white-
box attacks (i.e. with full access to the FL model) and black-
box attacks (i.e. only able to query the FL model). In FL, the
global model maintained by the server suffers from the same
evasion attacks as in the conventional ML setting when the
target model is deployed as a service. Moreover, the model
broadcast step in FL makes the global model a white-box to
any malicious participant. Thus, FL requires extra efforts to
defend against white-box evasion attacks.
3 POISONING ATTACKS
Depending on the attacker’s objective, poisoning attacks can
be classified into two categories: a) untargeted poisoning
attacks [55], [57], [58], [59], [60] and b) targeted poisoning
attacks [26], [27], [61], [62], [63], [64], [65], [66].
Untargeted poisoning attacks aim to compromise the
integrity of the target model, which may eventually result
in a denial-of-service attack. In targeted poisoning attacks,
the learnt model outputs the target label specified by the
adversary for particular testing examples, e.g., predicting
spams as non-spams, and predicting attacker-desired labels
for testing examples with a particular Trojan trigger (back-
door/trojan attacks). However, the testing error for other
testing examples is unaffected. Generally, targeted attacks
is more difficult to conduct than untargeted attacks as the
attacker has a specific goal to achieve. Poisoning attacks
during the training phase can be performed on the data or
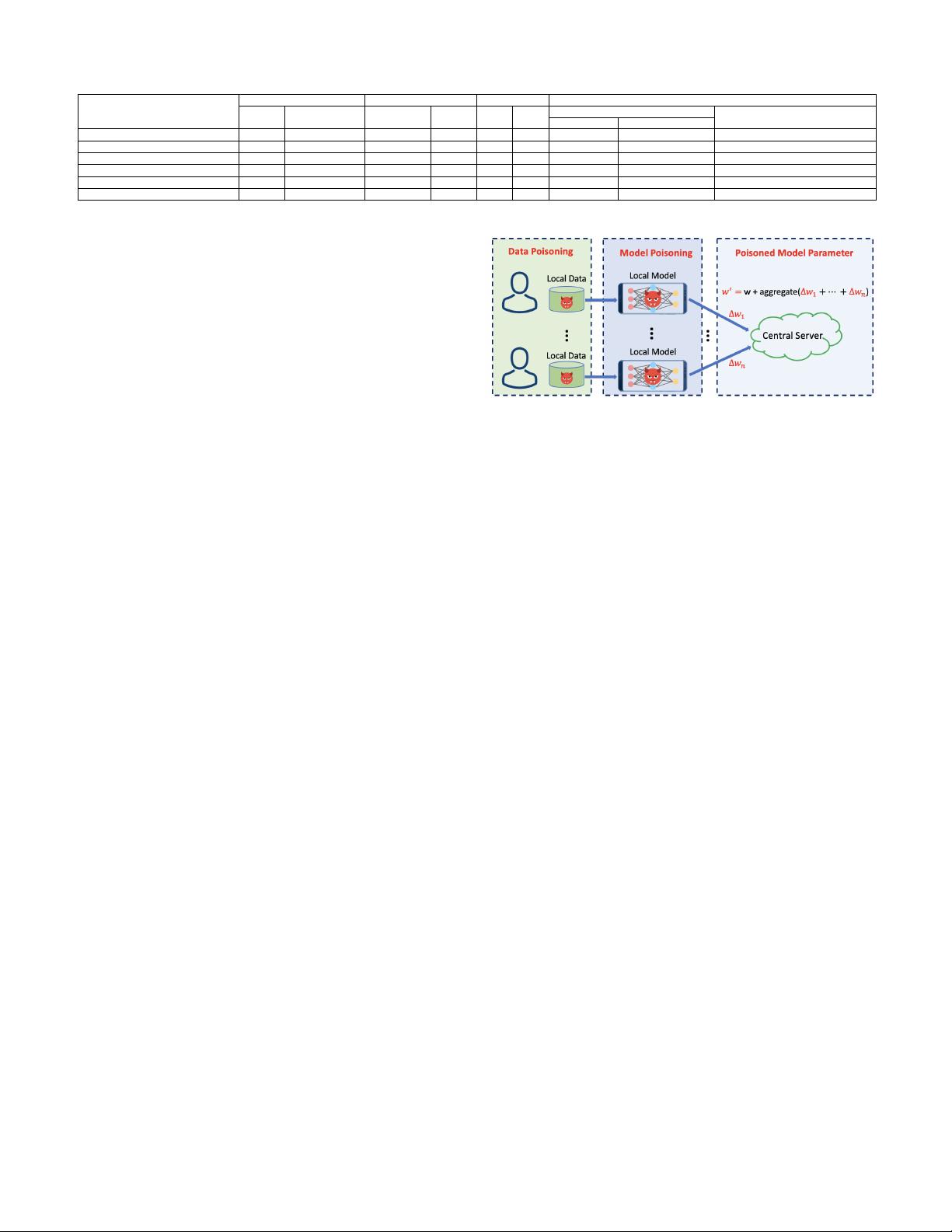
on the model. Fig. 2 shows that the poisoned updates can
be sourced from two poisoning attacks: (1) data poisoning
attack during local data collection; and (2) model poisoning
attack during local model training process. At a high level,
both poisoning attacks attempt to modify the behavior of
the target model in some undesirable way.
Fig. 2: Data v.s. model poisoning attacks in FL.
3.1 Data Poisoning
Data poisoning attacks largely fall in two categories: 1)
clean-label [44], [65], [67], [68], [69], [70] and 2) dirty-
label [63], [64]. Clean-label attacks assume that the adver-
sary cannot change the label of any training data as there
is a process by which data are certified as belonging to
the correct class and the poisoning of data samples has to
be imperceptible. In contrast, in dirty-label poisoning, the
adversary can introduce a number of data samples it wishes
to be misclassified by the model with the desired target label
into the training data.
One common example of dirty-label poisoning attack
is the label-flipping attack [28], [58]. The labels of honest
training examples of one class are flipped to another class
while the features of the data are kept unchanged. For
example, the malicious participants in the system can poison
their dataset by flipping all 1s into 7s. A successful attack
produces a model that is unable to correctly classify 1s
and incorrectly predicts them to be 7s. Another weak but
realistic attack scenario is backdoor poisoning [24], [25],
[64]. Here, an adversary can modify individual features or
small regions of the original training dataset to implant a
backdoor trigger into the model. The model will behave
normally on clean data, yet will constantly predict a target
class whenever the trigger (e.g., a stamp on an image)
appears. In this way, the attacks are harder to be detected.
For backdoor attacks in FL, a global trigger pattern can be
decomposed into separate local patterns and embed them
into the training set of different adversarial participants
respectively [25].
Data poisoning attacks can be carried out by any FL par-
ticipant. Due to the distributed nature of FL, data poisoning
attacks are generally less effective than model poisoning
attacks [26], [27], [28], [29]. The impact on the FL model
depends on the extent to which the backdoor participants
engage in the attacks, and the amount of training data being
poisoned. A recent work shows that poisoning edge-case
(low probability) training samples are more effective [24].
剩余15页未读,继续阅读
2020-03-25 上传
2020-02-22 上传
2022-02-09 上传
2024-05-28 上传
2024-01-08 上传
2020-08-08 上传
2022-06-09 上传
2021-09-24 上传

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
