Google Landmarks Dataset v2: 大规模实例识别与检索基准
需积分: 0 94 浏览量
更新于2024-07-15
收藏 9.5MB PDF 举报
"Google Landmarks Dataset v2 是一个大规模实例级识别和检索基准测试数据集,由Google Research发布,用于图像检索技术的评估和进步。该数据集包含超过5百万张图像,涵盖20万多种不同的实例标签,是目前同类数据集中最大的一个。测试集有11.8万张带有精确标注的图像,适用于检索和识别任务。数据集的构建耗费了超过800小时的人工注解工作。GLDv2特别关注现实世界应用中的挑战性问题,如极度倾斜的类别分布和复杂的视觉变化。"
谷歌地标数据集v2(Google Landmarks Dataset v2,简称GLDv2)是一个专门为实例级识别和图像检索提供基准测试的大规模数据集。随着图像检索和实例识别技术的快速发展,需要具有挑战性的数据集来准确评估其性能,并提出新的实际应用难题。GLDv2的出现就是为了满足这一需求。
该数据集的特点包括:
1. 大规模:GLDv2拥有超过5百万张图像,远超之前的任何同类数据集,这为深度学习模型提供了充足的训练和验证数据。
2. 细粒度分类:数据集包含20万多种独特的实例标签,意味着每个类别可能只包含少量图像,这对于处理长尾分布的问题尤其具有挑战性。
3. 实际应用导向:GLDv2的设计考虑到了真实世界中的复杂情况,如地标在不同季节、天气、视角下的变化,以及光照、遮挡等因素对识别的影响。
4. 测试集质量高:11.8万张带有精确注解的测试图像,为评价检索和识别算法的准确性提供了可靠依据。
5. 重度人工注解:数据集的构建过程中,人工注解工作耗时巨大,确保了标注的质量和准确性。
GLDv2的出现,对于推动图像检索和实例识别技术的进步具有重要意义。它不仅能够帮助研究人员开发更高效、更具鲁棒性的算法,还能促进计算机视觉领域在处理不平衡数据分布和复杂视觉环境问题上的研究。通过在GLDv2上进行训练和测试,研究人员可以设计出更加适应现实世界场景的模型,提升模型在实际应用中的表现。同时,该数据集也为学术界和工业界的协作提供了共享资源,推动了整个领域的共同发展。
reduced training set of
1.6
M images and
81
k landmarks (see
Sec. 5.1). While the index and training set do not share
images, their label space is highly overlapping, with
92
k
common classes. The query set is randomly split into 1/3
validation and 2/3 testing data. The validation data was
used for the “Public” leaderboard in the Kaggle competition,
which allowed participants to submit solutions and view their
scores in real-time. The test set was used for the “Private”
leaderboard, which was used for the final ranking and was
only revealed at the end of the competition.
3.3. Challenges
Besides its scale, the Google Landmarks Dataset v2
presents practically relevant challenges, as motivated above.
Class distribution.
The class distribution is extremely long-
tailed, as illustrated in Fig. 1.
57
% of classes have at most
10
images and
38
% of classes have at most
5
images. The
dataset therefore contains a wide variety of landmarks, from
world-famous ones to lesser-known, local ones.
Intra-class variation.
As is typical for an image dataset col-
lected from the web, the Google Landmarks Dataset v2 has
large intra-class variability, including views from different
vantage points and of different details of the landmarks, as
well as both indoor and outdoor views for buildings.
Out-of-domain query images.
To simulate a realistic query
stream, the query set consists of only
1.1
% images of land-
marks and
98.9
% out-of-domain images, for which no result
is expected. This puts a strong emphasis on the importance
of robustness in a practical instance recognition system.
3.4. Metrics
The Google Landmarks Dataset v2 uses well-established
metrics, which we now introduce. Reference implementa-
tions are available on the dataset website.
Recognition
is evaluated using micro Average Precision
(
µ
AP) [
40
] with one prediction per query. This is also known
as Global Average Precision (GAP). It is calculated by sort-
ing all predictions in descending order of their confidence
and computing:
µAP =
1
M
N
X
i=1
P(i)rel(i), (1)
where
N
is the total number of predictions across all queries;
M
is the total number of queries with at least one landmark
from the training set visible in it (note that most queries do
not depict landmarks);
P(i)
is the precision at rank
i
; and
rel(i)
is a binary indicator function denoting the correctness
of prediction
i
. Note that this metric penalizes a system
that predicts a landmark for an out-of-domain query image;
overall, it measures both ranking performance as well as the
ability to set a common threshold across different queries.
Retrieval
is evaluated using mean Average Precision@100
(mAP@100), which is a variant of the standard mAP metric
0
100
200
300
400
0
500
1,000
1,500
Germany
USA
UK
France
Spain
Italy
Czech R.
Netherl.
Japan
Poland
Russia
Ukraine
India
Austria
Canada
Sweden
Switzerl.
China
Israel
Brazil
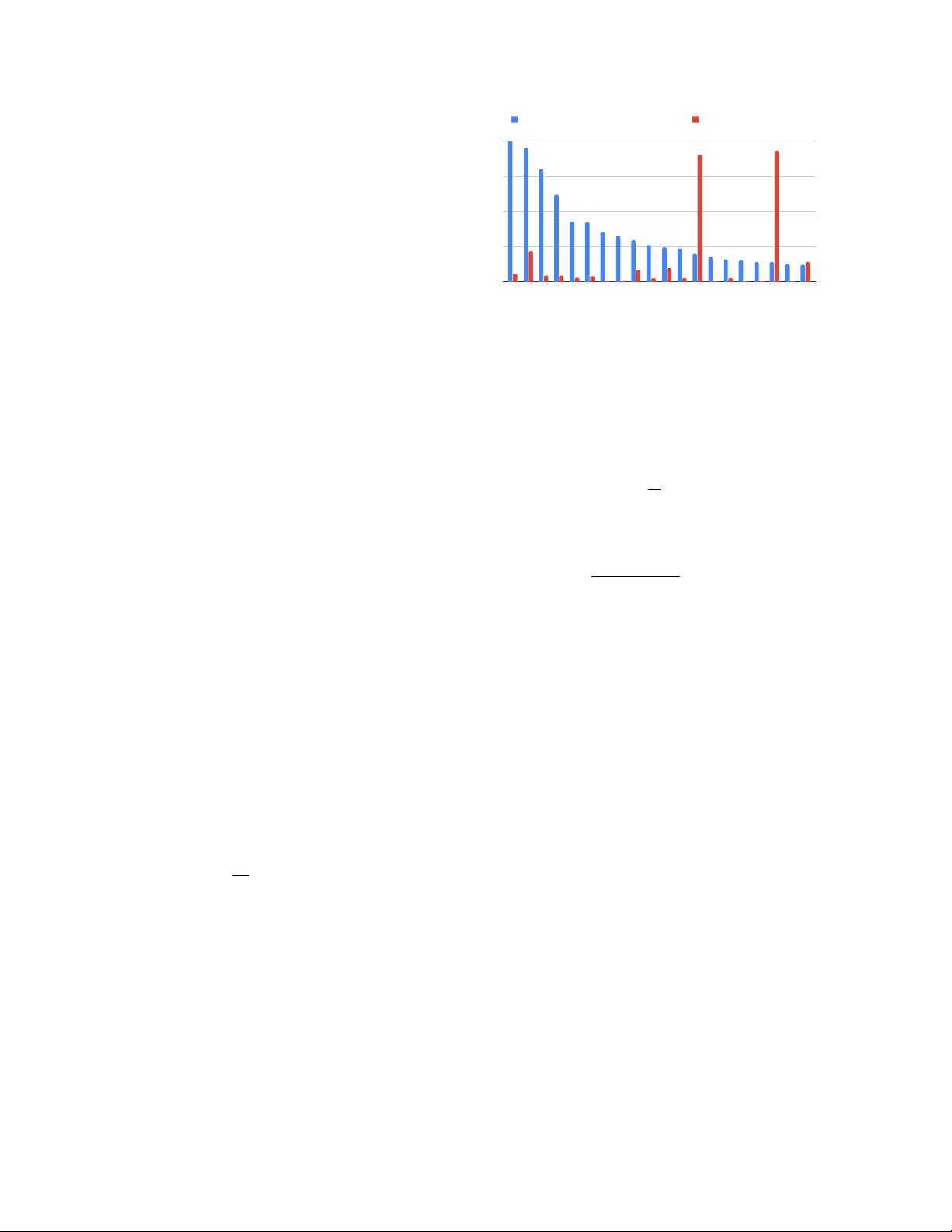
Number of images (thousands) Population (millions)
Figure 3: Histogram of the number of images from the top-20 countries
(blue) compared to their populations (red).
that only considers the top-100 ranked images. We chose this
limitation since exhaustive retrieval of every matching image
is not necessary in most applications, like image search. The
metric is computed as follows:
mAP@100 =
1
Q
Q
X
q=1
AP@100(q), (2)
where
AP@100(q) =
1
min(m
q
, 100)
min(n
q
,100)
X
k=1
P
q
(k)rel
q
(k)
(3)
where
Q
is the number of query images that depict landmarks
from the index set;
m
q
is the number of index images con-
taining a landmark in common with the query image
q
(note
that this is only for queries which depict landmarks from the
index set, so
m
q
6= 0
);
n
q
is the number of predictions made
by the system for query
q
;
P
q
(k)
is the precision at rank
k
for the
q
-th query; and
rel
q
(k)
is a binary indicator function
denoting the relevance of prediction
k
for the
q
-th query.
Some query images will have no associated index images to
retrieve; these queries are ignored in scoring, meaning this
metric does not penalize the system if it retrieves landmark
images for out-of-domain queries.
3.5. Data Distribution
The Google Landmarks Dataset v2 is a truly world-
spanning dataset, containing landmarks from 246 of the 249
countries in the ISO 3166-1 country code list. Fig. 3 shows
the number of images in the top-20 countries and Fig. 4
shows the number of images by continent. We can see that
even though the dataset is world-spanning, it is by no means
a representative sample of the world, because the number of
images per country depends heavily on the activity of the
local Wikimedia Commons community.
Fig. 5 shows the distribution of the dataset images by
landmark category, as obtained from the Google Knowl-
edge Graph. By far the most frequent category is churches,
4
剩余17页未读,继续阅读
2021-05-09 上传
2021-03-19 上传
2019-04-14 上传
2021-05-23 上传
2021-06-20 上传
2021-02-10 上传
2021-03-14 上传
2024-05-11 上传

kaichu2
- 粉丝: 853
- 资源: 71
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
