预训练基础模型综述:从BERT到ChatGPT
需积分: 0 189 浏览量
更新于2024-06-23
收藏 5.54MB PDF 举报
"这篇综述文章全面探讨了预训练基础模型(Pretrained Foundation Models, PFMs)的发展历程,从BERT到ChatGPT的演变。作者包括来自不同大学和研究机构的专家,如密歇根州立大学、北京航空航天大学、利哈伊大学等。文章强调了预训练在大型模型应用中的关键作用,以及它如何作为迁移学习范式在计算机视觉等领域取得显著效果。"
正文:
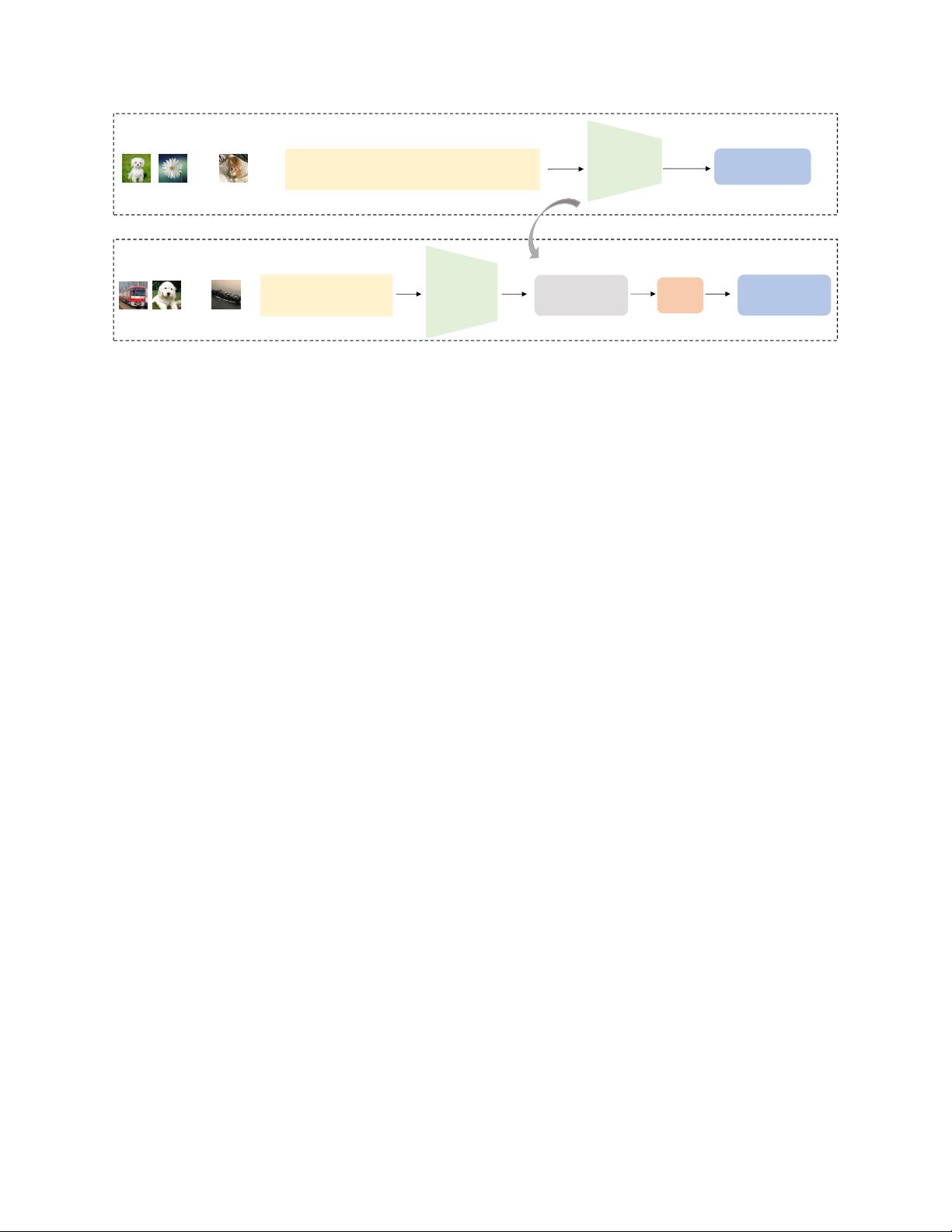
预训练基础模型(PFMs)在近年来的自然语言处理(NLP)领域中扮演了核心角色,它们为各种下游任务提供了多模态数据的基础。这些模型,如BERT、GPT-3、MAE、DALLE-E和ChatGPT,都是通过在大规模数据上进行预训练,为广泛的下游应用提供合理的参数初始化。这一预训练理念在大型模型的应用中起着至关重要的作用。
BERT(Bidirectional Encoder Representations from Transformers)是预训练模型的里程碑,它引入了双向Transformer架构,彻底改变了语言模型的训练方式。BERT通过预训练任务,如掩码语言模型(Masked Language Modeling, MLM)和下一句预测(Next Sentence Prediction, NSP),学习语言的内在结构和上下文关系。这些预训练的模型参数随后可以微调,以适应特定的下游任务,如问答系统、文本分类或情感分析。
GPT(Generative Pre-trained Transformer)系列,尤其是GPT-3,进一步扩展了预训练模型的规模和能力。与BERT不同,GPT模型采用自回归方式训练,通过预测序列中的下一个词来学习语言模式。GPT-3凭借其庞大的参数量(超过1750亿),展示了强大的零样本学习和少样本学习能力,能在没有特定领域数据的情况下完成多种任务。
MAE(Masked Autoencoder)是预训练领域的又一创新,它专注于图像数据,采用了部分像素掩码策略,使得模型仅需恢复被遮挡的部分,从而降低计算成本并提高效率。这种方法在视觉任务上的表现令人印象深刻。
DALLE-E和ChatGPT则将预训练模型的概念扩展到了生成式模型领域。DALLE-E结合了语言和视觉信息,能够根据文本指令生成图像。ChatGPT则是OpenAI的最新成果,一个经过大规模对话数据预训练的模型,能够进行流畅的人机对话,展示了预训练模型在交互式应用中的潜力。
预训练作为一种迁移学习方法,已经在计算机视觉中得到广泛应用,如冻结部分网络层进行特征提取,然后微调剩余部分以适应目标任务。这种技术在减少训练时间、提高模型性能方面展现出巨大优势。预训练模型的成功也启发了其他领域的研究,例如跨模态学习,其中模型在不同数据类型之间建立联系,促进更综合的理解。
这篇综述深入剖析了从BERT到ChatGPT的预训练模型发展历程,揭示了预训练在构建强大、通用的AI系统中的核心地位。随着计算资源的增加和算法的不断优化,预训练模型将继续推动人工智能技术向前发展,为未来的智能应用提供更高效、更灵活的解决方案。

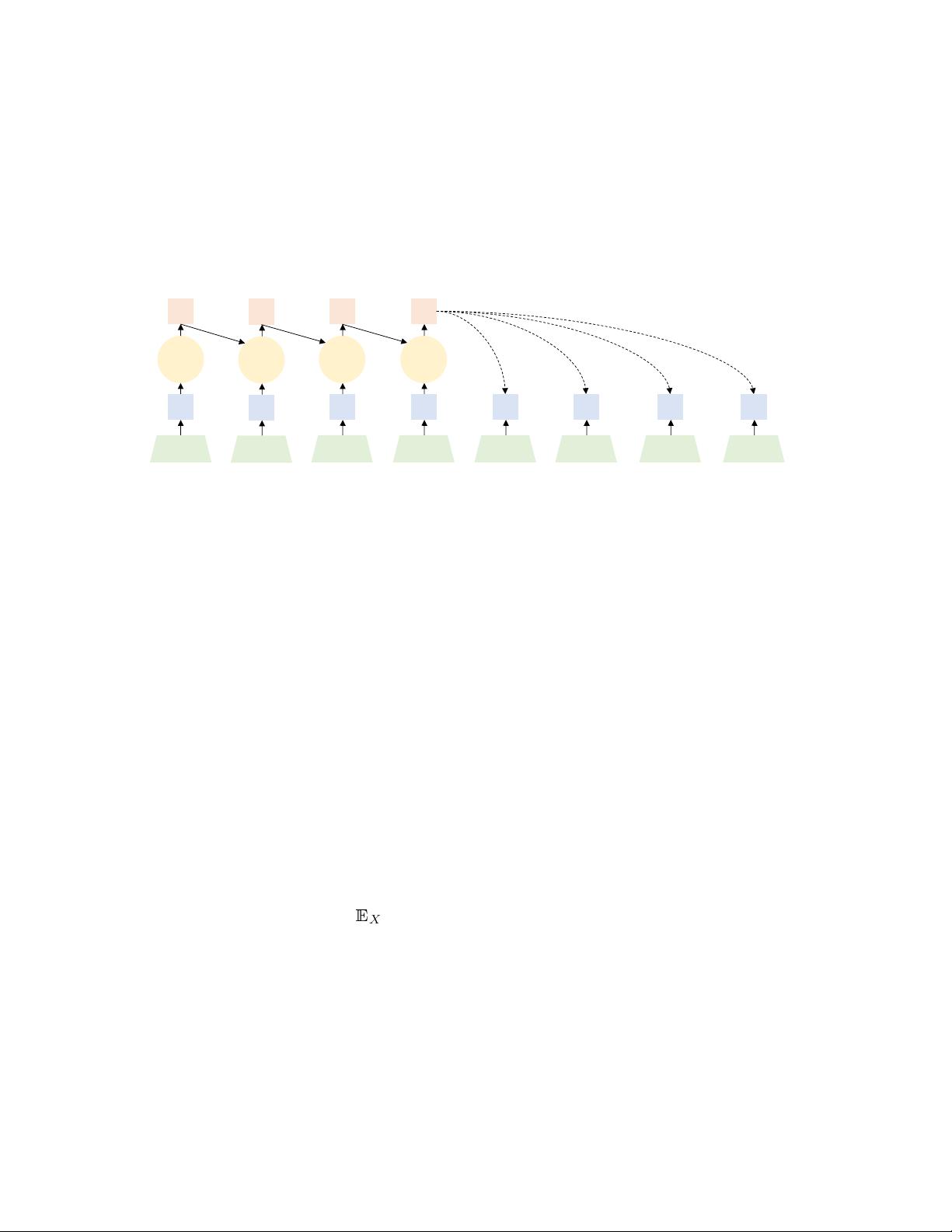
Boosting Examples: ChatGPT and Bard As shown in Fig. 5, ChatGPT is fine-tuned based on the PFM
GPT-3.5 using RLHF. ChatGPT uses a different data collection setup compared to InstructGPT. First, a large
dataset with prompts and the desired output behaviors is collected. The dataset is used to fine-tune GPT-3.5
with supervised learning. Second, given the fine-tuned model and a prompt, the model will generate several
model outputs. A labeler gives the desired score and ranks the output to compose a comparison dataset,
which is used to train the reward model. Finally, the fine-tuned model (ChatGPT) is optimized against the
reward model using the Proximal Policy Optimization (PPO)[64] RL algorithm.
Another experimental conversational PFM, the Bard
2
, is developed by Google. Bard is based on the
LM for Dialogue Applications (LaMDA). LaMDA [65] is built upon the Transformer, which is pretrained
on 1.56T words of dialog data and web text. Safety and factual grounding are two main challenges for
conversational AI, LaMDA applies the approaches that fine-tuning with high-quality annotated data and
external knowledge sources to improve model performance.
3.5 Instruction-Aligning Methods
Instruction-aligning methods aim to let the LM follow human intents and generate meaningful outputs. The
general approach is fine-tuning the pretrained LM with high-quality corpus in a supervised manner. To
further improve the usefulness and harmlessness of LMs, some works introduce RL into the fine-tuning pro-
cedure so that LMs could revise their responses according to human or AI feedback. Both supervised and RL
approaches can leverage chain-of-thought [24] style reasoning to improve the human-judged performance
and transparency of AI decision-making.
Supervised Fine-Tuning (SFT) SFT is a well-established technique to unlock knowledge and apply it
to specific real-world, even unseen tasks. The template for SFT is composed of input-output pairs and an
instruction [111]. For example, given the instruction “Translate this sentence to Spanish:” and an input
“The new office building was built in less than three months.”, we want the LM to generate the target “El
nuevo edificio de oficinas se construyó en tres meses.”. The template is commonly humanmade including
unnatural instructions [112] and natural instructions [113, 114], or bootstrap based on a seed corpus [115].
Ethical and social risks of harm from LMs are significant concerns in SFT [116]. LaMDA, the largest LM to
date, thus relies on crowdworker annotated data for providing a safety assessment of any generated LaMDA
response in three conversation categories: natural, sensitive, and adversarial. The list of rules serves further
safety fine-tuning and evaluation purposes.
Reinforcement Learning from Feedback RL has been applied to enhance various models in NLP tasks
such as machine translation [117], summarization [18], dialogue generation [118], image captioning [119],
question generation [120], text-games [121], and more [122, 123, 124]. RL is a helpful method for opti-
mizing non-differentiable objectives in language generation tasks by treating them as sequential decision-
making problems. However, there is a risk of overfitting to metrics that use neural networks, leading to
nonsensical samples that score well on the metrics [125]. RL is also used to align LMs with human prefer-
ences [126, 127, 128].
InstructGPT proposes to fine-tune large models with PPO against a trained reward model to align LMs
with human preference [19], which is the same method applied by ChatGPT named RLHF. Specifically,
the reward model is trained with comparison data of human labelers’ manual rankings of outputs. For each
of them, the reward model or machine labeler calculates a reward, which is used to update the LM using
2
https://blog.google/technology/ai/bard-google-ai-search-updates/
16


剩余96页未读,继续阅读
421 浏览量
281 浏览量
2025-01-08 上传
2025-01-08 上传

quanlibin1984
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- trading-using-options-sentiment-indicators
- CIS基础知识
- torch_cluster-1.5.6-cp37-cp37m-linux_x86_64whl.zip
- NOTHING ON THE INTERNET-crx插件
- 解决sqlserver 2012 中ID 自动增长 1000的问题.zip
- 在游戏中解谜游戏
- 导航栏左右滑动焦点高亮菜单
- Omicron35:正在进行中的Panda3D游戏
- Audio-Classification:针对“重新思考音频分类的CNN模型”的Pytorch代码
- be-the-hero-app:在OmniStack 11.0周开发的前端项目
- awvs12_40234.zip
- torch_sparse-0.6.4-cp37-cp37m-win_amd64whl.zip
- 团队建设讲座PPT
- 导航菜单下拉滑动油漆刷墙
- wkhtmltopdf.zip
- ShapeShit:软件开发
