Gbase中的并行计算:概念、方法与硬件环境
需积分: 1 150 浏览量
更新于2024-09-17
收藏 868KB PDF 举报
"并行计算相关资料,主要应用于国产数据库Gbase"
并行计算是一种高效处理大规模计算问题的方法,通过同时使用多个计算资源,如多处理机或分布式计算机网络,来提升计算速度和效率。这一技术的核心在于将计算任务分解为可独立执行的部分,以便在不同的处理器上并行处理,从而缩短整体计算时间。
并行计算有两种基本类型:时间上的并行(流水线技术)和空间上的并行。时间上的并行通过在不同阶段处理数据,使得不同步骤可以重叠进行,提高效率;而空间上的并行则涉及多个处理器同时处理不同的数据段,实现计算任务的并发执行。
并行化方法主要包括域分解和任务分解。在域分解中,数据被分割到各个处理器,每个处理器负责一部分计算;例如,找出数组中的最大值。任务分解则是将整个任务拆分成若干子任务,分配给不同处理器执行,如在图形用户界面中,事件处理器的分配就是一个例子。
并行计算硬件环境的构建是实现并行计算的关键。Flynn分类是根据指令和数据流的特性来区分计算机系统的,包括MIMD(多指令流多数据流)和SIMD(单指令流多数据流)。MIMD系统允许每个处理器独立执行不同的指令和处理不同的数据,常见于大多数并行计算机。而SIMD系统则适合数据密集型运算,如多媒体处理,因为它能同时处理多个相同指令的操作数。
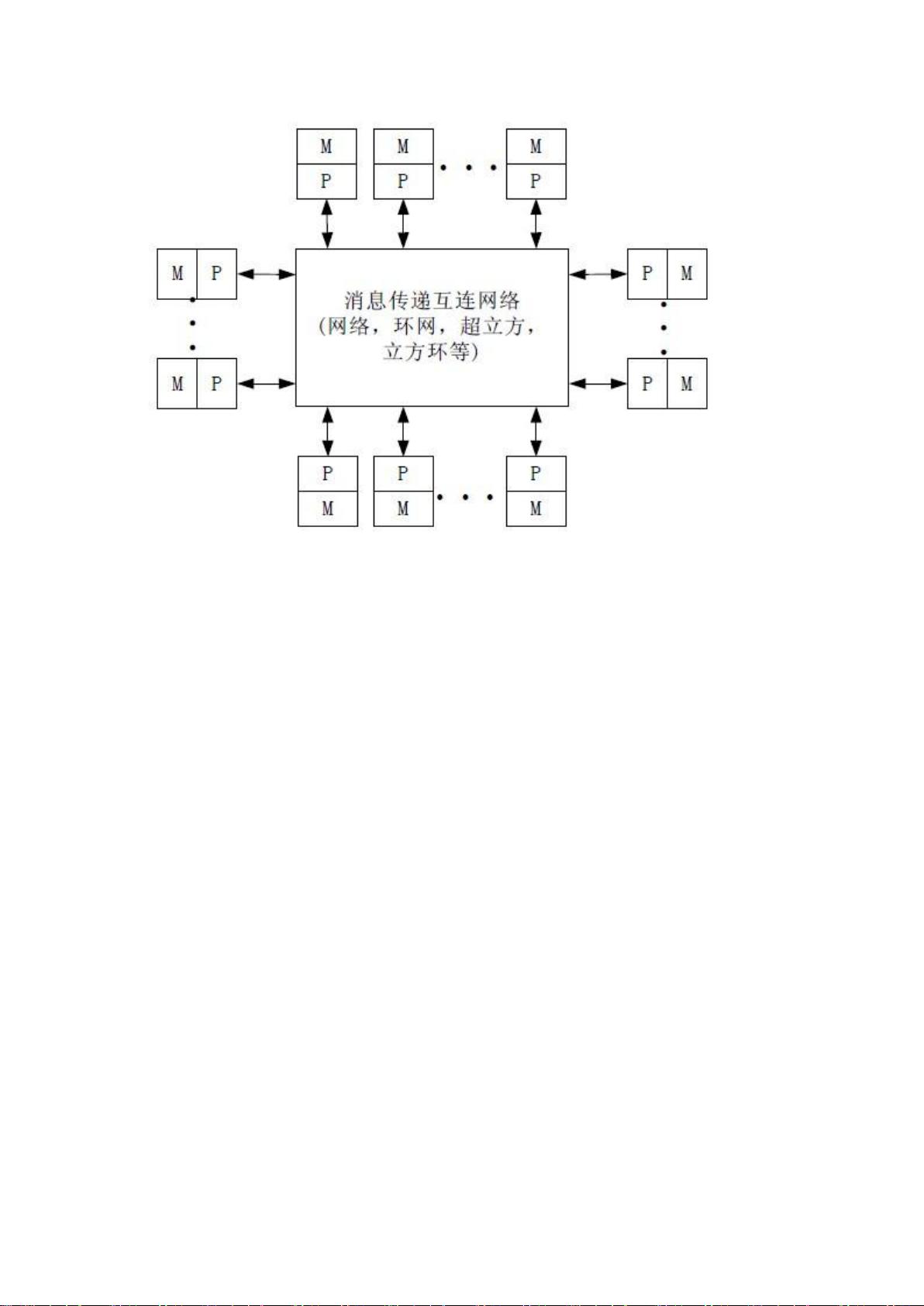
在并行计算机系统结构中,除了处理器的类型,还有其他关键组件,如通信网络,用于处理器间的通信和数据交换。例如,共享内存系统中处理器通过共享内存进行通信,而消息传递接口(MPI)则常用于分布式内存系统,处理器间通过消息传递进行协调。
对于国产数据库Gbase而言,利用并行计算技术可以显著提高其处理大数据查询和复杂计算任务的能力。通过并行执行查询计划,Gbase能够更快地响应用户请求,提供更高效的数据库服务。这涉及到数据库的并行查询优化,包括并行扫描、并行排序、并行聚合等操作,以实现数据库性能的最大化。
理解并行计算的基本概念、方法和硬件环境对于有效地利用国产数据库Gbase进行高性能计算至关重要。通过合理地并行化计算任务,可以充分利用计算资源,提高计算效率,满足大数据时代对计算能力的高要求。
2. 多核处理器
多核出现,原因有:
功耗过大,芯片温度过高
缓存过大,占据>70%芯片面积
隐式指令集并行,处理器指令执行流水化,加上不断提高的时钟速度,使得新一代
的处理器芯片总能以更快的速度执行程序,而同时又保持顺序执行的假象。
多核时代
多核计算环境:
–多个复杂度适中,相对低功耗的处理核心并行工作
–CPU 时钟频率基本不变
–计算机硬件不会更快,但会更“宽”
–操作系统、应用程序设计
三、内存系统,性能评测
1. 内存系统对性能的影响
对于很多应用而言,瓶颈在于内存系统,而不是 CPU
内存系统的性能包括两个方面:延迟和带宽
–延迟:处理器向内存发起访问直至获取数据所需要的时间
–带宽:内存系统向处理器传输数据的速率
2. 性能评测
1). 基本性能指标
剩余12页未读,继续阅读
2010-09-20 上传
2009-11-20 上传
2009-11-13 上传
2021-09-29 上传
2007-10-21 上传
2010-10-29 上传

tianlei521
- 粉丝: 1
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- Dota Map Downloader-开源
- lapis-console:用于Lapis的交互式控制台
- HTML属性标签大全注释
- multidraw:使用手机进行多点触控输入设备的多用户绘图应用程序
- matlab开发-JavaScript 项目-ant-motion.zip
- flask-githubapp:Flask扩展,本着probot(https:
- wget-1.16.tar.gz
- 创业计划书-高效太阳能逆变器设计
- Python库 | flatland-model-diagram-editor-0.2.0.tar.gz
- cloud_storage:一个用于与Google Cloud Storage通信的Lua库
- 录制-易语言.zip
- npm-stats:使用npm API进行实验
- LightStopWatch:非常轻巧且简单的秒表。-开源
- mongodb4.4.6安装包
- 创业计划书-杨梅汁项目可行性
- STemwin/emWin 5.26 工具集
