大规模知识图谱的嵌入学习与优化
需积分: 9 82 浏览量
更新于2024-07-21
2
收藏 4.23MB PDF 举报
"清华大学刘知远在CCF ADL第65期的《知识图谱前沿》讲座中探讨了大规模知识图谱的表征学习,深入解析了如何利用表示学习来处理和理解大规模知识图谱。报告内容涵盖了一维向量表示、分布式表示、神经网络结构以及层次性学习等关键概念。"
在知识图谱领域,表征学习(Representation Learning)已经成为一种重要的方法,它结合了表示、目标和优化三个方面,正如Yoshua Bengio在2013年AAAI教程中所阐述的深度学习表示。表征学习的核心在于从原始数据中学习到更具有语义意义的表示,以提升模型的性能和泛化能力。
在传统的1-热编码(1-hot Representation)中,每个实体或词汇被表示为一个稀疏的高维向量,这种表示方式在处理大量数据时效率低下且无法捕捉词汇之间的关系。例如,"太阳"和"星星"在1-热编码下是完全分离的,它们之间的相似度为零。而表征学习引入了分布式表示(Distributed Representation)或嵌入(Embeddings),通过将实体表示为稠密、实值且低维度的向量,使得相似的实体在向量空间中更接近,从而能更好地捕获语义信息。
表示学习的基础部分受到人脑学习的启发。人脑的高效处理能力源于其低信号速度与高计算速度、高处理容量与低能耗的平衡。在现实世界与认知世界的对应中,表征学习试图模拟这种从离散到连续、从具体到抽象的层次转换。
报告还强调了层次性网络结构(Hierarchical Network Structure)在表征学习中的重要性,这与现实世界中的层次结构相呼应。层次结构允许模型在不同抽象级别上理解和处理信息,提高了模型的表达能力和处理复杂知识的能力。例如,在知识图谱中,可以有从实体到属性,再到更高级别概念的层次结构,这样的结构有助于模型更有效地学习和推理。
刘知远的报告深入浅出地介绍了大规模知识图谱的表征学习,包括从基础的一维向量表示到复杂的分布式表示和层次网络结构,为理解和应用知识图谱提供了新的视角和方法。这些理论和技术对于构建和优化大规模知识图谱系统,如搜索引擎、问答系统和智能助手等,都具有重要的实践意义。
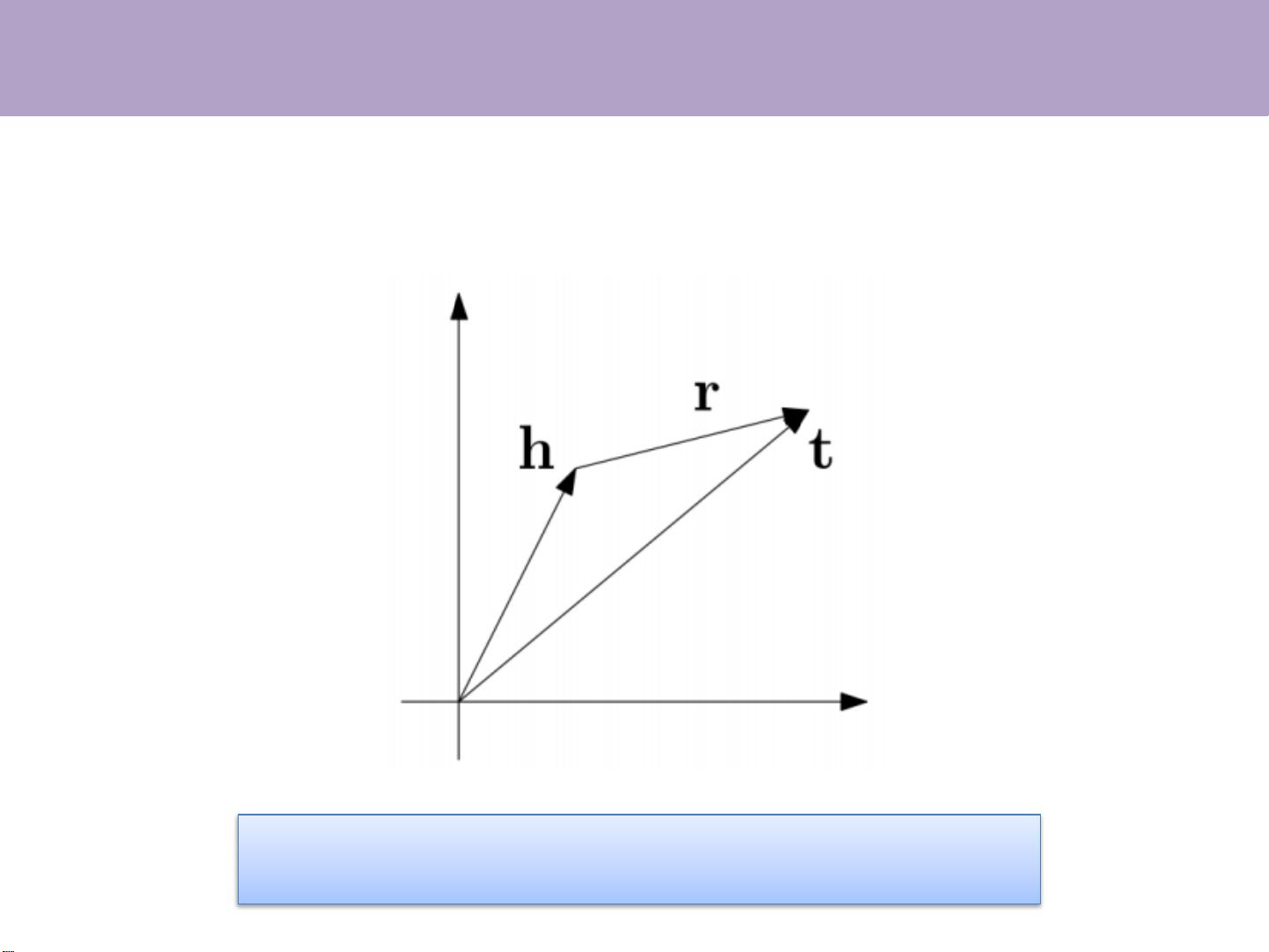
TransE
For each triple (head, relation, tail), relation as a
translation from head to tail
13
Learning objective: h + r = t


剩余78页未读,继续阅读
2022-08-04 上传
2019-08-10 上传

周建丁
- 粉丝: 1217
- 资源: 150
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
