CUDA C编程指南:Version 3.2更新说明
下载需积分: 9 | PDF格式 | 3.21MB |
更新于2024-07-25
| 98 浏览量 | 举报
"CUDA_C_Programming_Guide,NVIDIA CUDA™ 编程指南,版本3.2,更新了包括16位浮点纹理、纹理与表面内存一致性、流同步等功能"
CUDA C编程指南是NVIDIA发布的一份详细文档,旨在帮助开发者理解和利用CUDA架构进行并行计算。该指南的第3.2版主要关注CUDA C编程语言的各个方面,并在3.1.1版本的基础上进行了多项改进和增强。
1. **简化cuParamSetv()代码示例**:
在新版本中,由于`CUdeviceptr`现在与`void*`具有相同的大小和对齐方式,因此不再需要通过内部的`void*`变量来设置内核参数。这简化了使用`cuParamSetv()`函数的代码,使程序更易读和维护。
2. **16位浮点纹理(Section 3.2.4.1.4)**:
添加了关于16位浮点纹理的新章节,说明如何处理和使用这种轻量级数据类型进行纹理采样,以提高存储效率和计算性能。
3. **纹理与表面内存一致性(Section 3.2.4.4)**:
更新了这部分内容,详细阐述了纹理内存和表面内存的读写一致性问题,这对于理解和优化GPU访问全局内存的行为至关重要。
4. **表面内存访问(Section 3.2.4.2)**:
对表面内存的访问得到了更多细节的补充,帮助开发者更好地理解和利用表面内存进行高效的数据交换。
5. **流同步(Section 3.2.6.5)**:
引入了新的流同步函数`cudaStreamSynchronize()`,这使得多任务管理更加灵活,可以精确控制不同计算任务间的依赖关系。
6. **处理使用NVIDIA SLI AFR模式的设备的API调用**:
在3.2.7.2、3.3.10.2和4.3节中提到了处理使用NVIDIA Scalable Link Interface (SLI)的交替帧渲染(AFR)模式下设备的新API,这扩展了CUDA在多GPU系统中的应用。
7. **调用堆栈(Sections 3.2.9 and 3.3.12)**:
新增了关于调用堆栈的章节,帮助开发者理解和调试CUDA程序的执行流程,尤其是在涉及递归或复杂函数调用时。
8. **内存分配函数cuMemAllocPitch()的签名变更**:
第3.3.4节的第二个代码示例中,将pitch变量的类型从`unsigned int`改为`size_t`,以匹配`cuMemAllocPitch()`函数的更新签名,确保内存分配的正确性。
9. **内存分配函数cuMemAllocPitch()的最后代码示例**:
同样在3.3.4节,将最后一个代码示例中`bytes`变量的类型从`unsigned`改为`size_t`,以保持与函数接口的一致性。
这些更新和改进旨在提升CUDA编程的效率和灵活性,同时帮助开发者充分利用GPU的并行计算能力,实现高性能计算的应用。通过深入学习和应用这些知识点,开发者可以构建出更高效、更优化的CUDA程序。

Chapter 1. Introduction
4 CUDA C Programming Guide Version 3.2
solve many complex computational problems in a more efficient way than on a
CPU.
CUDA comes with a software environment that allows developers to use C as a
high-level programming language. As illustrated by Figure 1-3, other languages or
application programming interfaces are supported, such as CUDA FORTRAN,
OpenCL, and DirectCompute.
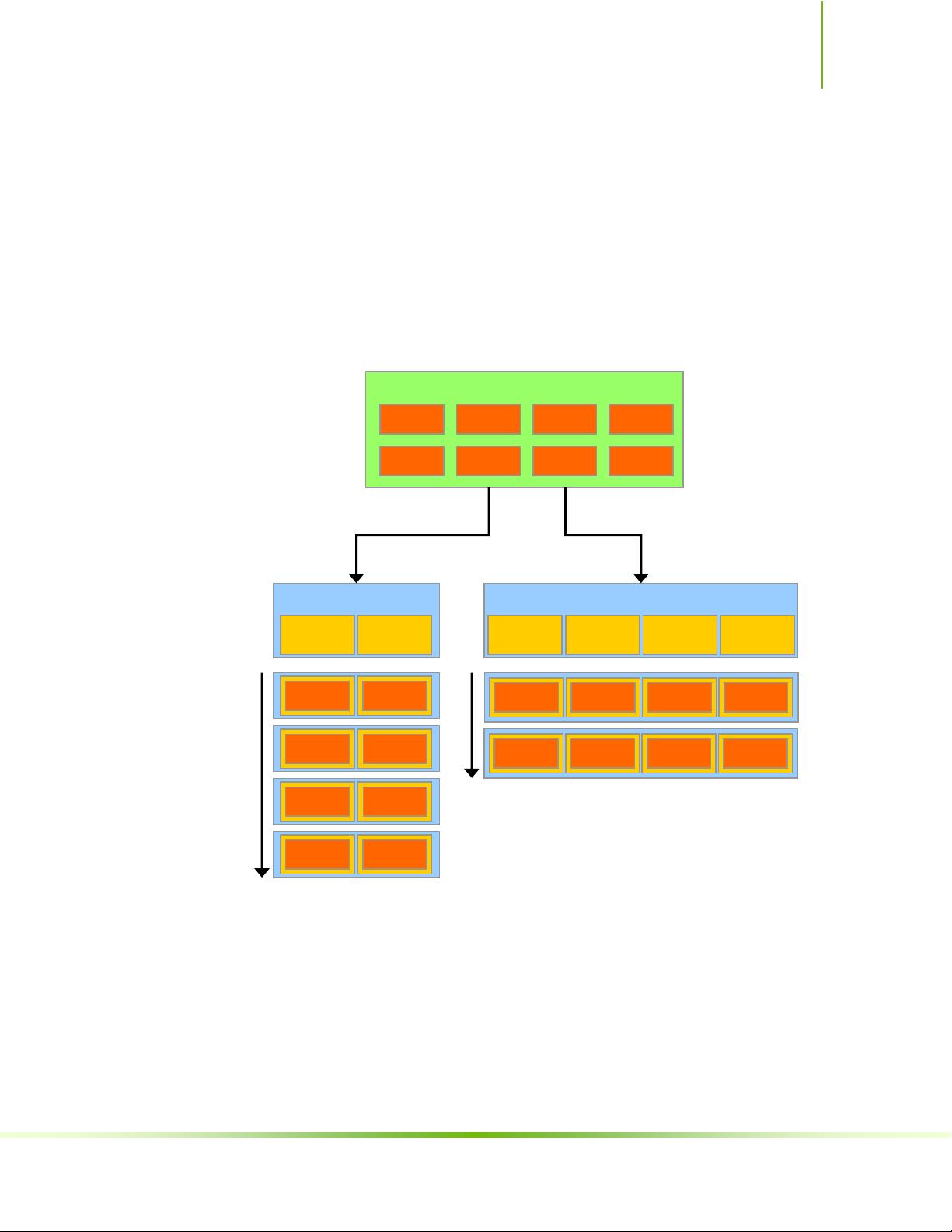
Figure 1-3. CUDA is Designed to Support Various Languages
or Application Programming Interfaces
1.3 A Scalable Programming Model
The advent of multicore CPUs and manycore GPUs means that mainstream
processor chips are now parallel systems. Furthermore, their parallelism continues
to scale with Moore‟s law. The challenge is to develop application software that
transparently scales its parallelism to leverage the increasing number of processor
cores, much as 3D graphics applications transparently scale their parallelism to
manycore GPUs with widely varying numbers of cores.
The CUDA parallel programming model is designed to overcome this challenge
while maintaining a low learning curve for programmers familiar with standard
programming languages such as C.
At its core are three key abstractions – a hierarchy of thread groups, shared
memories, and barrier synchronization – that are simply exposed to the programmer
as a minimal set of language extensions.
These abstractions provide fine-grained data parallelism and thread parallelism,
nested within coarse-grained data parallelism and task parallelism. They guide the
programmer to partition the problem into coarse sub-problems that can be solved
independently in parallel by blocks of threads, and each sub-problem into finer
pieces that can be solved cooperatively in parallel by all threads within the block.
This decomposition preserves language expressivity by allowing threads to


剩余182页未读,继续阅读
相关推荐



cudaer
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 盖茨比入门项目教程:搭建静态网站的新体验
- 全面技术领域源码整合:一站式学习与开发工具包
- C++图形编程系列教程:图像处理与显示
- 使用百度地图实现Android定时定位功能
- Node.js基础教程:实现音乐播放与上传功能
- 掌握Swift动画库:TMgradientLayer实现渐变色动画
- 解决无法进入安全模式的简易方法
- XR空间应用程序列表追踪器:追踪增强与虚拟现实应用
- Ember Inflector库:实现单词变形与Rails兼容性
- EasyUI Java实现CRUD操作与数据库交互教程
- Ruby gem_home:高效管理RubyGems环境的工具
- MyBatis数据库表自动生成工具使用示例
- K2VR Installer GUI:独特的虚拟现实安装程序设计
- 深蓝色商务UI设计项目资源全集成技术源码包
- 掌握嵌入式开发必备:深入研究readline-5.2
- lib.reviews: 打造免费开源的内容审核平台
