揭秘搜索引擎工作原理与技术系统详解
需积分: 0 20 浏览量
更新于2024-06-30
收藏 3.71MB PDF 举报
《搜索引擎原理、技术与系统》是由李晓明、闫宏飞和王继民三位作者共同编著的一本科学出版社出版的专业书籍,于2004年发行。本书主要聚焦于互联网搜索引擎的核心领域,系统地讲解了搜索引擎的工作原理、实现技术和系统构建方案。全书分为上、中、下三篇,共计13章,内容涵盖了搜索引擎的基础概述、小型简单搜索引擎的实现细节、大规模分布式搜索引擎系统的设计要点以及关键技术,直至深入探讨主题和个性化Web信息服务,如中文网页的自动分类技术及其实际应用。
在搜索引擎的介绍部分,作者从基本工作原理入手,让读者理解搜索引擎如何抓取网页、索引信息并根据用户的查询提供相关的搜索结果。随着互联网信息量的爆炸性增长,搜索引擎成为了人们获取信息的重要途径,包括直接输入网址、浏览门户网站的分类目录和使用搜索引擎进行关键词搜索。
本书的特点在于理论与实践相结合,既有深入的理论分析,如搜索引擎算法、信息检索模型等,又有丰富的实验数据和实例,使得学习者既能理解理论知识,又能掌握实际操作技能。因此,它不仅适合计算机科学与技术、信息管理与信息系统、电子商务等专业的研究生和高年级本科生作为教材使用,也为网络技术研究人员、Web站点管理者、数字图书馆工作人员以及Web挖掘领域的开发者提供了宝贵的参考资料。
对于那些希望提升搜索引擎优化策略、设计高效搜索引擎系统或利用Web挖掘技术的人来说,这本书无疑是一份不可多得的指南。《搜索引擎原理、技术与系统》是一本既全面又实用的书籍,对于理解和应用现代搜索引擎技术具有重要的指导意义。
第一章 引论
略的方面。
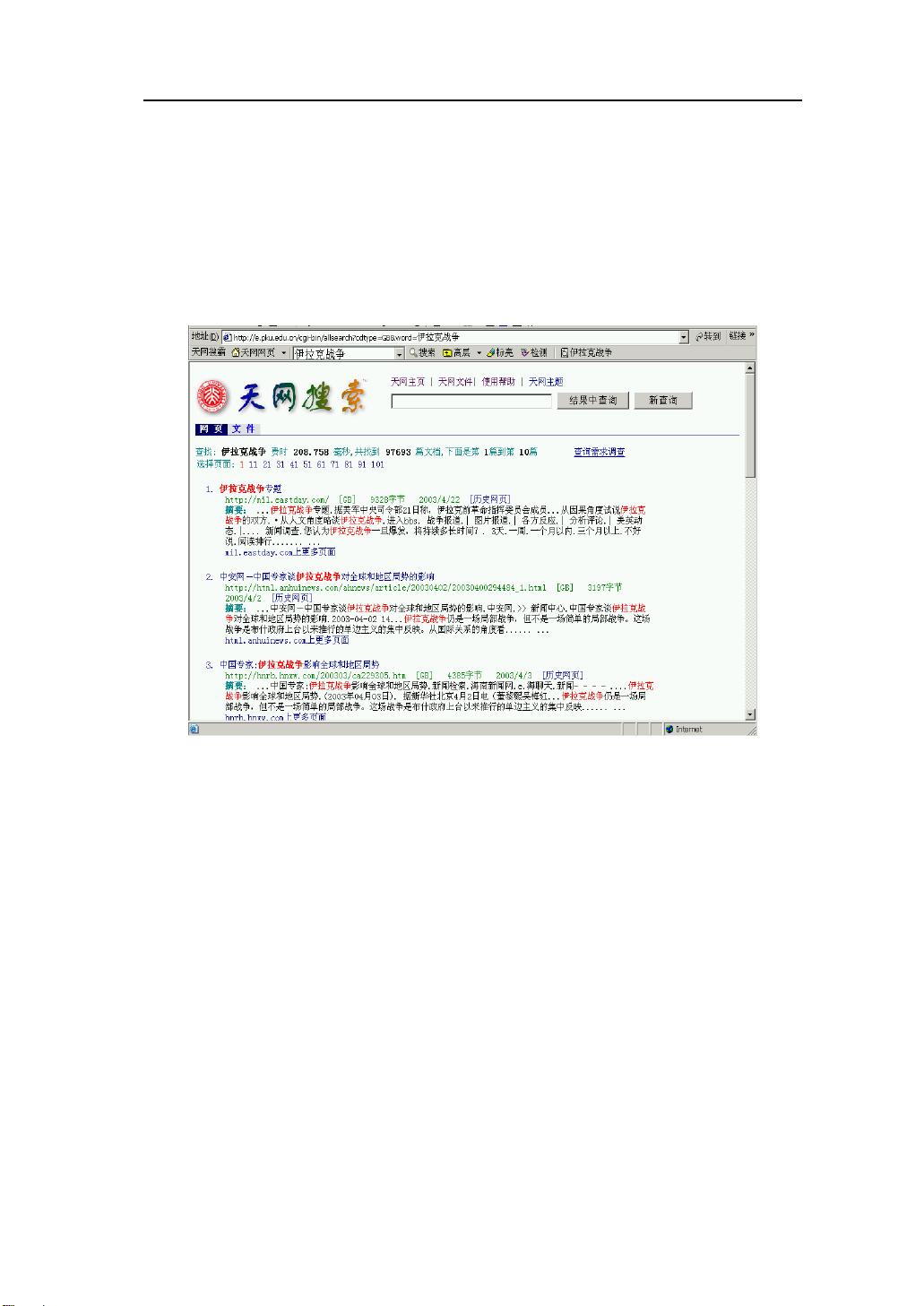
作为对搜索引擎工作原理的基本了解,这里有两个问题需要首先澄清。第一,
当用户提交查询的时候,搜索引擎并不是即刻在 Web 上“搜索”一通,发现那些
相关的网页,形成列表呈现给用户;而是事先已“搜集”了一批网页,以某种方
式存放在系统中,此时的搜索只是在系统内部进行而已。第二,当用户感到返回
图 1-1 2003 年 8 月 20 日在天网上检索“伊拉克战争”的结果
结果列表中的某一项很可能是他需要的,从而点击 URL,获得网页全文的时候,
他此时访问的则是网页的原始出处。于是,从理论上讲搜索引擎并不保证用户在
返回结果列表上看到的标题和摘要内容与他点击 URL 所看到的内容一致(上面
那个“伊拉克战争”的例子就是如此!),甚至不保证那个网页还存在。这也是搜
索引擎和传统信息检索系统的一个重要区别。这种区别源于前述 Web 信息的基本
特征。为了弥补这个差别,现代搜索引擎都保存网页搜集过程中得到的网页全文,
并在返回结果列表中提供“网页快照”或“历史网页”链接,保证让用户能看到
和摘要信息一致的内容。
第二节 搜索引擎的发展历史
早在 Web 出现之前,互联网上就已经存在许多旨在让人们共享的信息资源
• 3 •



剩余278页未读,继续阅读
2023-12-14 上传
2023-03-09 上传
2024-02-25 上传
2023-04-24 上传
2023-10-10 上传
2023-12-17 上传
2023-02-21 上传
2024-10-23 上传
2023-06-10 上传

忧伤的石一
- 粉丝: 31
- 资源: 332
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
