"深入剖析Kafka高可用性实现原理与架构"
Kafka高可用性实现原理
Kafka是一个设计为高可用性的分布式消息系统,相对于传统的消息系统有着许多不同之处。首先,Kafka被设计为一个分布式系统,易于向外扩展,可以支持大规模的数据传输和处理;其次,它同时为发布和订阅提供高吞吐量,能够满足高并发的消息传输需求;此外,Kafka支持多订阅者,当失败时能自动平衡消费者,保障了系统的稳定性和可靠性;最重要的是,Kafka能够将消息持久化到磁盘,因此可用于批量消费和实时应用程序,保证了消息传输的可靠性和持久性。因此,Kafka凭借着自身的优势,越来越受到互联网企业的青睐,唯品会也采用Kafka作为其内部核心消息引擎之一。
在商业级消息中间件中,消息可靠性是至关重要的。如何确保消息的精确传输?如何确保消息的准确存储?如何确保消息的正确消费?这些都是需要考虑的问题。因此,我们需要对Kafka的高可用性实现原理有着清晰的认识和了解。
首先,需要从Kafka的架构入手,了解Kafka的基本原理。Kafka的体系架构包括若干Producer、若干Broker和若干Consumer组成。Producer负责生产消息,可以是服务器日志、业务数据、页面前端产生的page view等等;Broker代表Kafka集群中的一个节点,负责存储和管理消息;Consumer负责消费消息,进行数据的处理和分析。Kafka支持水平扩展,可以在不需中断服务的情况下动态添加或删除节点,保障了系统的稳定性和伸缩性。
其次,Kafka的存储机制、复制原理、同步原理、可靠性和持久性保证是保障Kafka高可用性的重要组成部分。Kafka采用分区和副本的方式来实现消息的存储和复制。每个主题都被分成一个或多个分区,每个分区都可以有多个副本。副本可以分布在不同的Broker上,确保了当一个Broker出现故障时消息仍然能够被正常消费。Kafka采用Leader-Follower模式,其中一个分区的一个副本被选举为Leader,其他副本被称为Follower。Leader负责处理所有的读写请求,Follower只负责从Leader同步数据。这样可以确保了Kafka在节点故障时的高可用性和数据一致性。
此外,Kafka还有可靠性和持久性保证机制,保障了消息的安全传输和存储。Kafka会将消息先写入到磁盘再返回成功给Producer,确保消息的持久性;同时,Kafka支持同步和异步两种模式的消息传输,可以根据实际需求来选择合适的方式,保障了消息的可靠性。
最后,通过对Kafka高可用性的benchmark测试,可以进一步增强对Kafka高可用性的认知。可以通过模拟不同场景下的故障和负载来验证Kafka在不同情况下的可用性和性能,为系统的优化和改进提供参考和依据。
总而言之,Kafka的高可用性是通过其分布式架构、存储机制、复制原理、同步机制、可靠性和持久性保证等多个方面的设计和实现来保障的。只有在保障了消息的安全传输、存储和消费的过程中,Kafka才能真正成为一个高可用、高可靠的商业级消息中间件,得到用户和企业的信赖和青睐。
!&'&'&()*+,-.*.,/.*010'%
在 Kafka 文件存储中,同一个 topic 下有多个不同的 partition,每个 partiton 为一个目录,
partition 的名称规则为:topic 名称+有序序号,第一个序号从 0 开始计,最大的序号为
partition 数量减 1,partition 是实际物理上的概念,而 topic 是逻辑上的概念。
上面提到 partition 还可以细分为 segment,这个 segment 又是什么?如果就以 partition 为
最小存储单位,我们可以想象当 Kafka producer 不断发送消息,必然会引起 partition 文件
的无限扩张,这样对于消息文件的维护以及已经被消费的消息的清理带来严重的影响,所
以这里以 segment 为单位又将 partition 细分。每个 partition(目录)相当于一个巨型文件被
平均分配到多个大小相等的 segment(段)数据文件中(每个 segment 文件中消息数量不一
定相等)这种特性也方便 old segment 的删除,即方便已被消费的消息的清理,提高磁盘
的利用率。每个 partition 只需要支持顺序读写就行,segment 的文件生命周期由服务端配
置参数(log.segment.bytes,log.roll.{ms,hours}等若干参数)决定。
segment 文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示为 segment 索引
文件和数据文件。这两个文件的命令规则为:partition 全局的第一个 segment 从 0 开始,
后续每个 segment 文件名为上一个 segment 文件最后一条消息的 offset 值,数值大小为
64 位,20 位数字字符长度,没有数字用 0 填充,如下:
********************&
********************
**************.2*).*&
**************.2*).*
**************(%+)%*&
**************(%+)%*
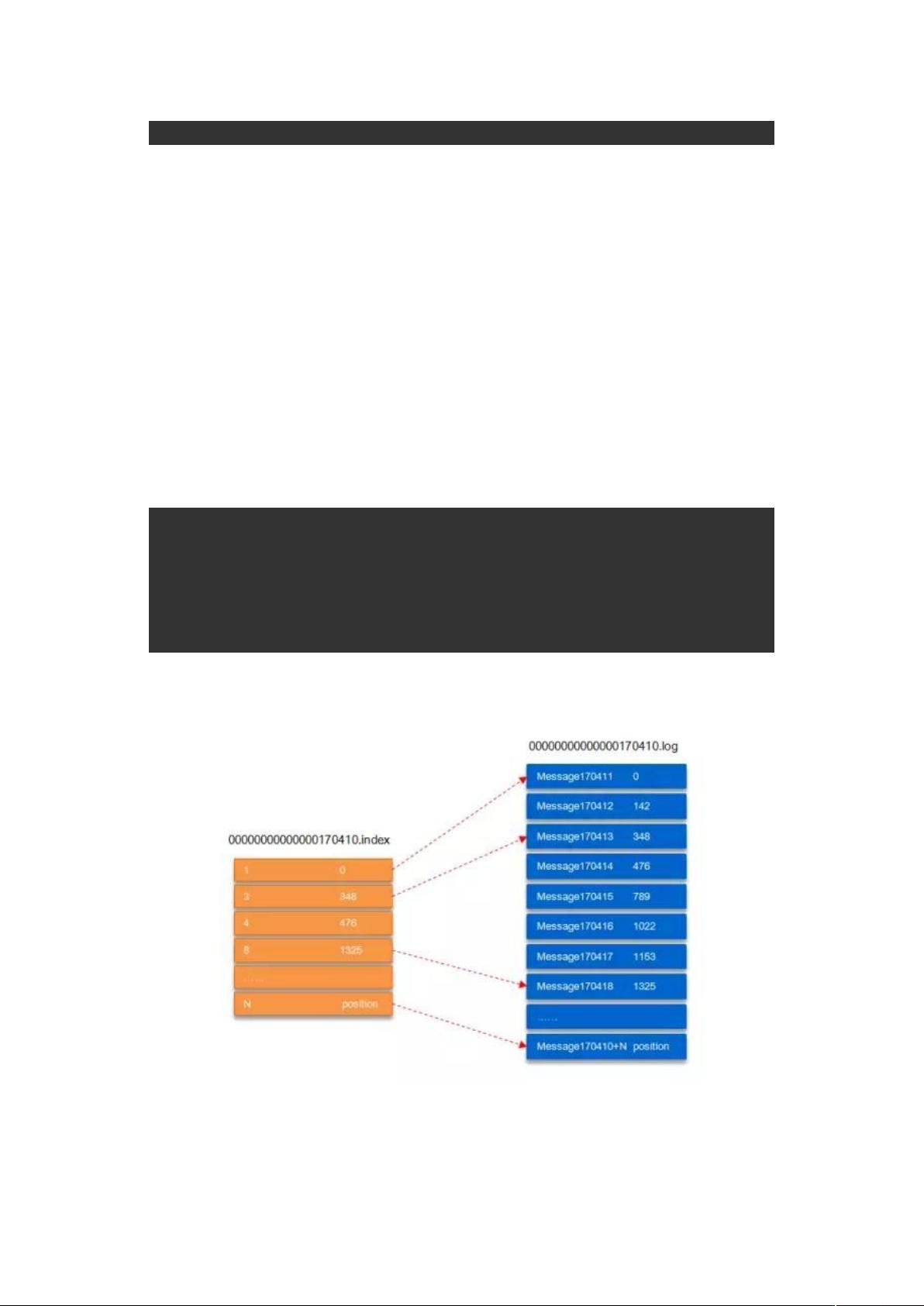
以上面的 segment 文件为例,展示出 segment:00000000000000170410 的“.index”文件
和“.log”文件的对应的关系,如下图:
如上图,“.index”索引文件存储大量的元数据,“.log”数据文件存储大量的消息,索引文件
中的元数据指向对应数据文件中 message 的物理偏移地址。其中以“.index”索引文件中的
元数据[3, 348]为例,在“.log”数据文件表示第 3 个消息,即在全局 partition 中表示
170410+3=170413 个消息,该消息的物理偏移地址为 348。
剩余18页未读,继续阅读
2018-06-25 上传
2021-01-20 上传
2023-07-15 上传
2022-08-04 上传
2021-01-27 上传
2022-08-04 上传
2019-08-19 上传

伯约重生
- 粉丝: 9
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
