HBase详解:基于Google BigTable的分布式列存储系统
193 浏览量
更新于2024-08-31
收藏 491KB PDF 举报
HBase是Apache Hadoop生态系统中的重要组成部分,它是一个建立在Hadoop Distributed File System (HDFS)之上的分布式列存储系统,受到了Google BigTable模型的启发。作为典型的键值对系统,HBase的设计理念是支持大规模、非结构化的数据存储,特别适合于海量数据处理,尤其是那些具有以下特点的数据:
1. **规模**:HBase表可以容纳数十亿行和上百万列,支持大数据量的处理。
2. **无模式**:每个数据行都有一个有序的主键(RowKey)和可动态增减的列(Column),灵活性高,允许不同行有不同的列结构。
3. **面向列**:采用列族(ColumnFamily)的概念,提供了独立的存储和权限管理,便于针对列进行查询和操作。
4. **稀疏性**:HBase节省存储空间,对于不存在或为null的列不占用存储,非常适合数据密集度较低的场景。
5. **多版本**:每个单元格的数据可以存储多个版本,版本号默认为时间戳,用户也可以自定义,支持历史数据跟踪。
6. **数据类型单一**:HBase的数据统一为字符串,简化了数据类型处理。
在HBase的逻辑视图中,RowKey是核心元素,作为行的唯一标识,其设计直接影响查询性能。ColumnFamily是组织数据的容器,包含一组相关的列。Column是ColumnFamily下的具体元素,可以动态增加。每个单元(Value或Cell)包含RowKey、Column Family、Column Name、Version Number以及实际的值(Value)。
在物理存储方面,HBase采用了以下策略:
- 行按照RowKey的字典顺序进行排序,并分布在多个Region中,这些Region根据数据增长自动分割以保持性能。
- 每个ColumnFamily的数据存储在一个独立的HDFS文件中,避免了冗余。
- 对于每个值,HBase维护了多级索引,包括行内和跨Region的索引,以支持高效的查询和遍历。
HBase提供了一种强大的工具,用于在大型分布式环境中高效处理和管理结构化和半结构化数据,是大数据处理和实时分析场景的理想选择。理解并掌握HBase的关键概念和技术对于从事大数据领域的开发者和运维人员来说至关重要。
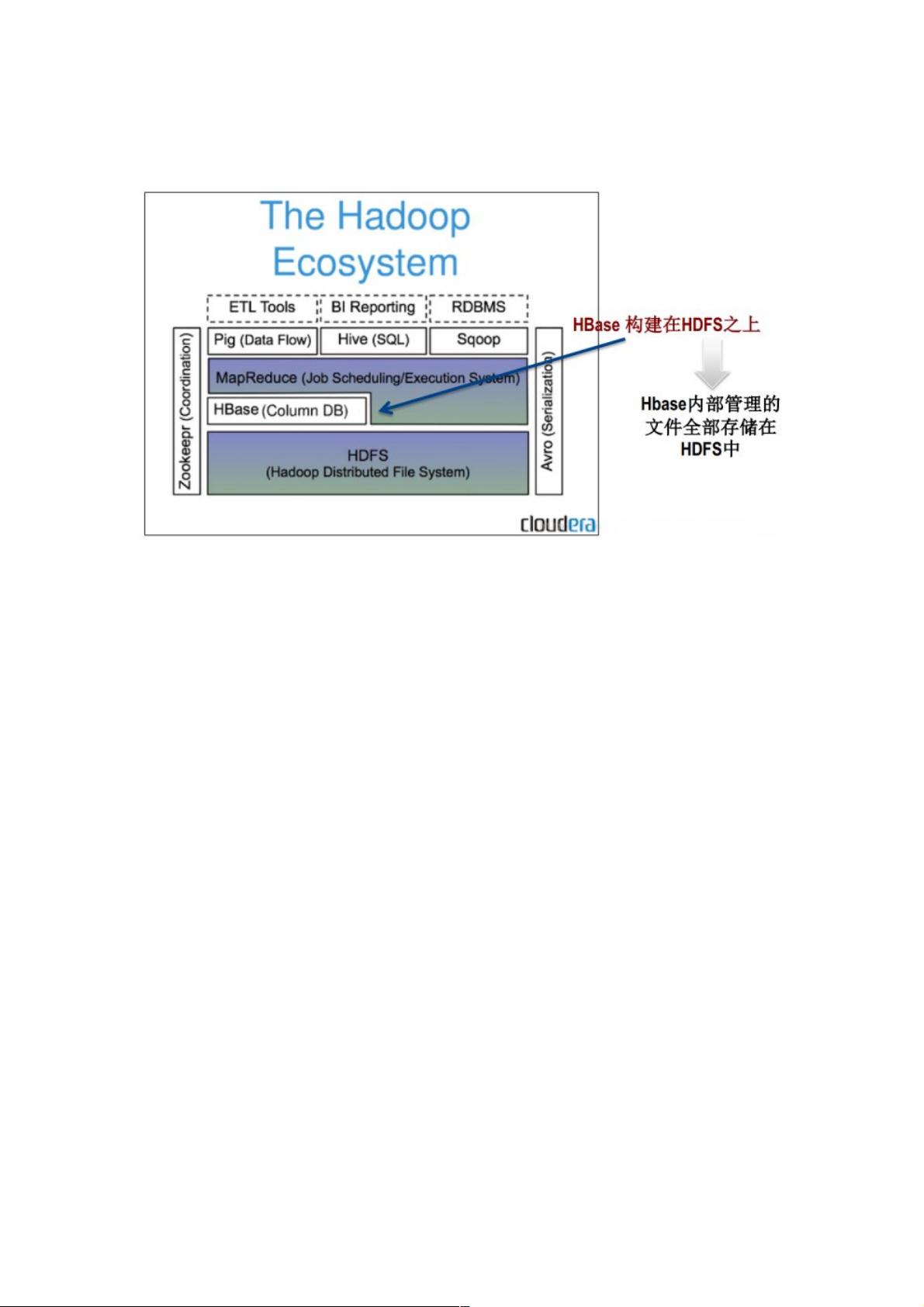
hbase 简介简介
HBase是基于GoogleBigTable模型开发的,典型的key/value系统;下面通过本文给大家介绍hbase的相关知
识,感兴趣的朋友一起看看吧
概述概述
HBase是一个构建在HDFS上的分布式列存储系统;
HBase是基于GoogleBigTable模型开发的,典型的key/value系统;
HBase是ApacheHadoop生态系统中的重要一员,主要用于海量结构化数据存储;
从逻辑上讲,HBase将数据按照表、行和列进行存储。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
Hbase表的特点表的特点
大:一个表可以有数十亿行,上百万列;
无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
面向列:面向列(族)的存储和权限控制,列(族)独立检索;
稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
数据类型单一:Hbase中的数据都是字符串,没有类型。
·Hbase数据模型数据模型
Hbase逻辑视图
下载后可阅读完整内容,剩余5页未读,立即下载
2022-10-29 上传
2012-03-07 上传
2024-11-10 上传
2014-03-28 上传
2022-11-02 上传

weixin_38628310
- 粉丝: 4
- 资源: 950
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
