分布式数据库恢复机制与故障模型
需积分: 9 197 浏览量
更新于2024-07-31
收藏 607KB PPT 举报
"分布式数据库 第七章 分布式恢复 东北大学"
在分布式数据库系统中,分布式恢复是确保系统在面对故障时能够保持原子性和持久性的关键机制。本章主要探讨了分布式数据库中关于恢复的基本概念、集中式数据库的恢复方法以及分布式事务的恢复策略。
首先,分布式数据库系统的可靠性(Reliability)和可用性(Availability)是两个核心概念。可靠性衡量的是系统按照预期行为工作的概率,包括系统在特定时间内不出故障的可能性,对于不可修复或需持续运行的系统尤其重要。而可用性则关注系统在规定时间内满足服务的能力,即系统正常运行的概率。两者之间存在一定的权衡关系:提高可靠性可能降低可用性,反之亦然。
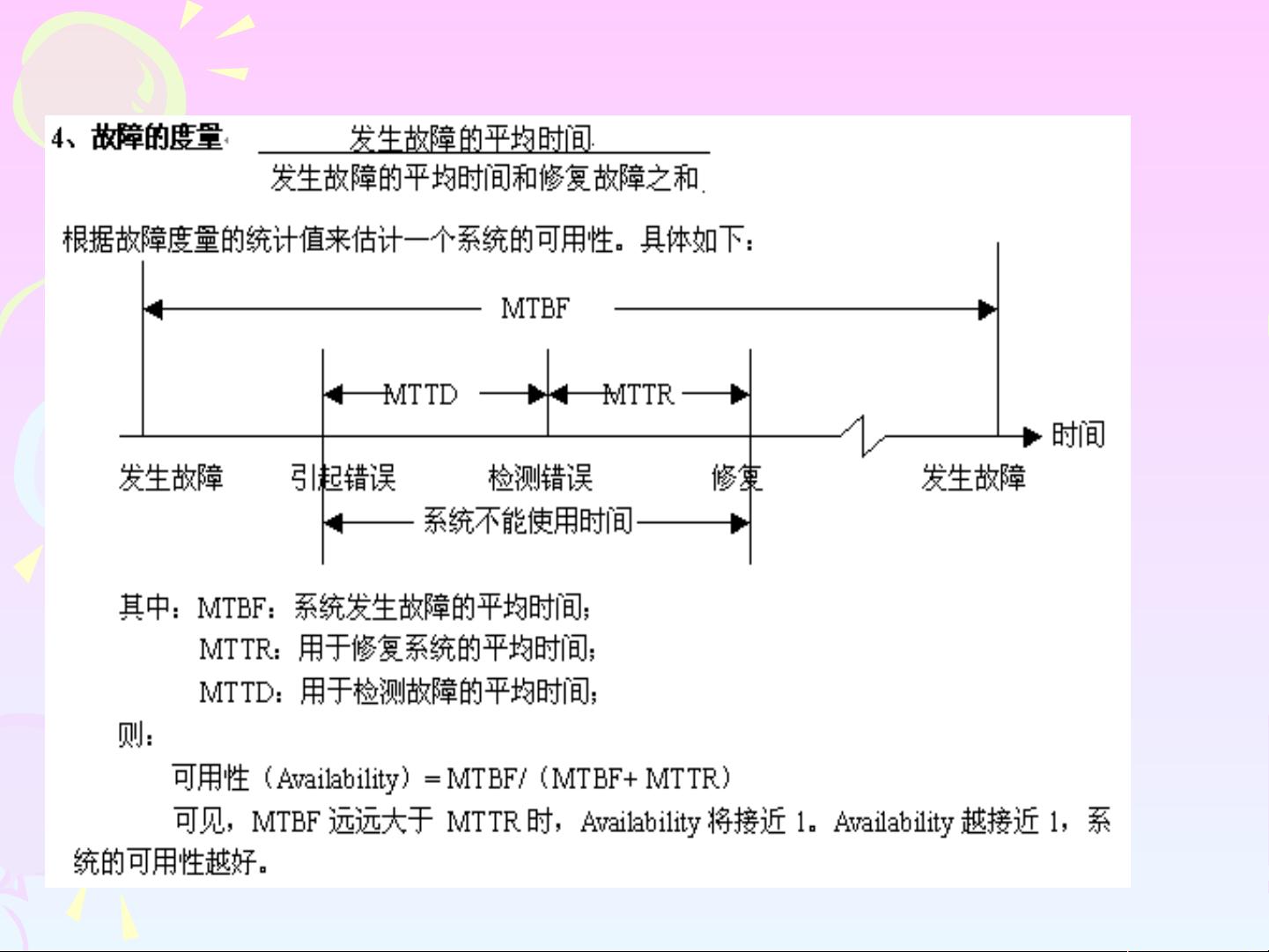
接着,本章介绍了故障模型,区分了Fault(故障)、Error(错误)和Failure(失效)三类故障形式。Fault通常指硬件或软件的缺陷,Error是由于Fault导致的系统行为异常,而Failure是系统功能丧失或性能下降的实际表现。恢复机制旨在应对这些故障,将系统状态回滚至故障发生前的正确状态,防止数据丢失和系统损坏。
集中式数据库的故障恢复方法主要涉及事务的提交协议和恢复协议。在分布式数据库中,由于事务可能跨越多个节点,恢复过程变得更加复杂。分布式事务的恢复需要考虑两阶段提交(2PC)等协议,这些协议保证了即使在网络分区或节点故障情况下也能保持事务的一致性。
此外,数据冗余和系统容错能力是影响数据库可靠性和可用性的关键因素。通过数据复制和分布式存储,可以提高系统的容错能力,但同时也可能增加系统复杂性和潜在的一致性问题。因此,设计有效的恢复策略是平衡这些矛盾的关键。
在分布式数据库中,当系统检测到故障风险时,可能需要决定是立即停止系统以确保可靠性,还是允许系统继续运行以维持可用性。后者可能导致短暂的数据不一致性,但可以通过后续的恢复过程来纠正。
分布式恢复是分布式数据库设计中的重要组成部分,它涉及到复杂的协议和策略,以确保系统在面对各种故障时仍能提供可靠且可用的服务。通过对故障模型的理解和恢复机制的设计,可以构建出更健壮、适应性强的分布式数据库系统。


2013-01-16 上传
2011-12-26 上传
2023-03-11 上传
2019-05-25 上传
2023-05-18 上传
2021-09-07 上传
2021-12-20 上传
2015-10-24 上传
2023-05-18 上传

creat2008
- 粉丝: 0
- 资源: 24
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
