深度监督哈希:加速图像检索的CNN方法
版权申诉
PDF格式 | 1.87MB |
更新于2024-06-23
| 9 浏览量 | 举报
"基于深度监督哈希的快速图像检索是一个重要的研究领域,随着互联网的爆炸式增长,海量图像的管理和检索成为一项挑战。传统的图像检索依赖于特征空间中距离的计算,但当数据库包含数以亿计的图像时,这种线性搜索方法效率低下,消耗大量时间和内存。为此,深度监督哈希(DSH)作为一种深度学习方法应运而生。
DSH的核心理念是利用卷积神经网络(CNN)的强大表征能力,通过训练过程生成二进制编码,即哈希码。它不再单独使用单张图片进行训练,而是引入图像对或三元组,同时结合它们之间的相似度标签,促使相似的图像输出靠近,非相似的远离,从而构造出一个能够有效反映图像语义结构的哈希空间。这种方法的目标是提高检索速度,尤其是在大规模数据集上。
近年来,近似最近邻搜索(如LSH)因其高效性而备受关注。LSH通过使用一组随机投影的哈希函数,将数据分散到不同的桶中,相似的数据更有可能落入同一桶,实现了高效的初步筛选。然而,无监督的哈希方法,如谱哈希(SH)和迭代量化哈希(ITQ),虽然能够学习到某种程度上的相似性,但难以处理复杂语义,因为它们缺乏类别或标签信息的指导。
为克服这一局限,监督学习方法如离散图哈希(DGH)和监督离散哈希(SDH)被提出,它们利用标注数据增强对复杂语义的理解。这些方法通过类别标签等信息指导哈希函数的学习,提高了检索精度。然而,这些方法仍然不能完全捕捉现实中数据的复杂变化,这促使研究人员转向基于CNN的哈希方法,如DSH,以提升对复杂语义变化的适应性和检索性能。
总结来说,基于深度监督哈希的图像检索技术是一种结合了深度学习和哈希编码的有效策略,它不仅解决了大规模图像数据库的检索问题,还兼顾了效率和精度。通过CNN的深度学习能力,它能够生成紧凑且富有表现力的二进制码,适应不断变化的数据环境,成为现代图像检索领域的关键研究方向。"
图
3-2
正则化器示意图
3.2 损失函数
Dtscrirmnallve
Binary Coda Learning
心
X
设
Q
为
RGB
图像空间,作者的方法旨在学习从
Q
到
k
位二维码的映射:
F:Q— {+1, 1?
,这
样类似的图像(在视觉相似性或语义相似性方面)就被编码为相似的二值码,反之亦然。为 此达到目的,
损失函数被设计为将相似图像的网络输出拉到一起,并将相异图像的输出推到很远, 以便学习的汉明空
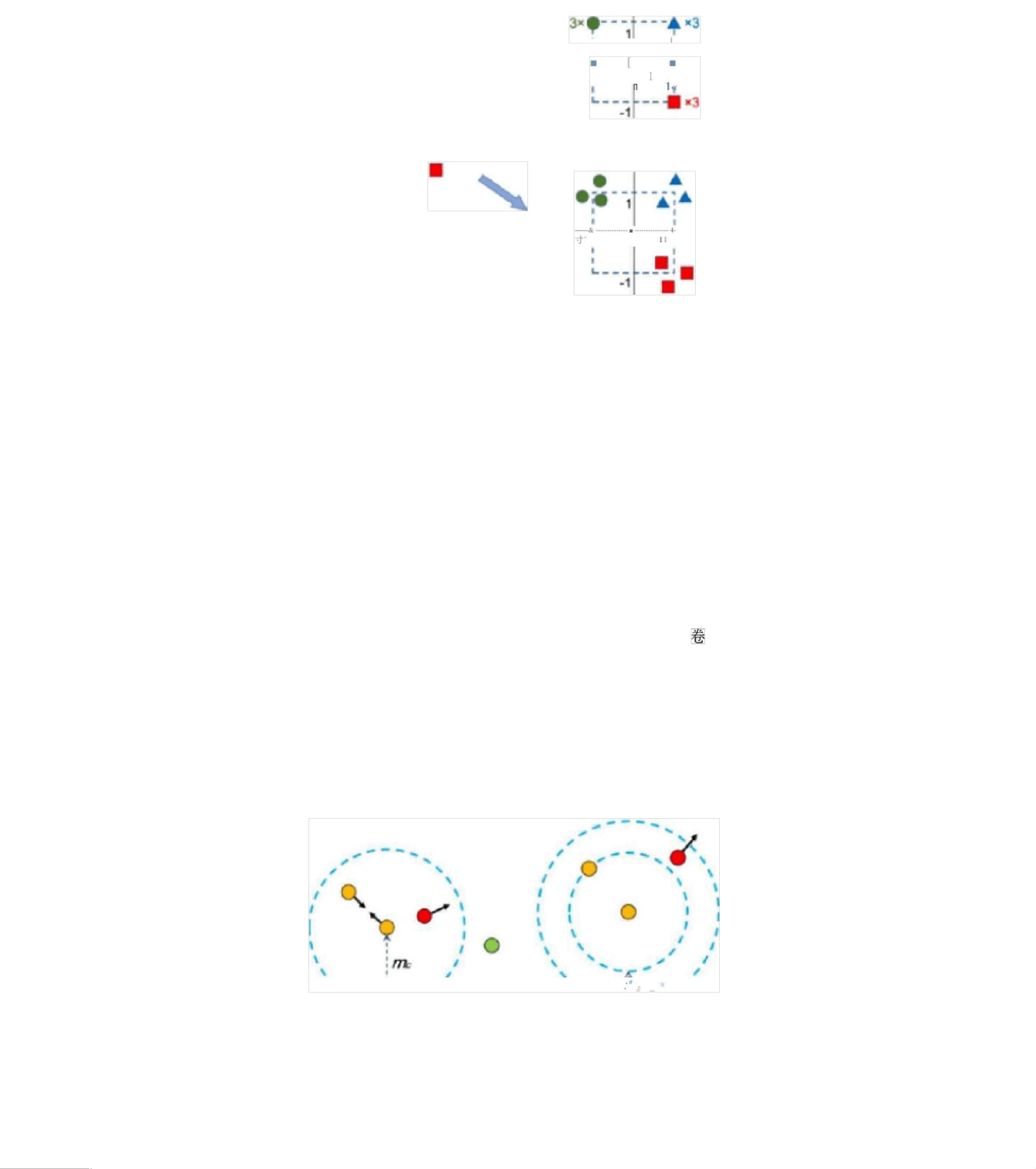
的图示方法:
(
a)
对比损失,在这种情况下,鼓励相似的样本黄色圆
Discrimi native
Learni ngi
尽可能靠近,而不同样本之
Relaxabon
间可以很好地近似图像的语义结构。女口图
3-3
所示,作者采用的两种损失函数
间(中心黄色圆圈与红色圆圈和绿色圆圈)的距离应大于
me (b)
三元组排序损失,其中相似样 本黄
色圆圈之间的距离被强 制小于空白样本(中心黄色圆圈与红色圆圈和绿色圆圈)之间的距离
m
3.2.1
对比损失
对比损失的设计为尽可能拉近相似图像的二值码,同时将相异图像的二值码推得很远,直到距离超 过预
剩余15页未读,继续阅读
相关推荐



hhappy0123456789
- 粉丝: 76
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机组成原理期末试题及答案(2011参考)
- 均值漂移算法深入解析及实践应用
- 掌握npm与yarn在React和pg库中的使用
- C++开发学生信息管理系统实现多功能查询
- 深入解析SIMATIC NET OPC服务器与PLC的S7连接技术
- 离心式水泵原理与Matlab仿真教程
- 实现JS星级评论打分与滑动提示效果
- VB.NET图书馆管理系统源码及程序发布
- C#实现程序A监控与自动启动机制
- 构建简易Android拨号功能的应用开发教程
- HTML技术在在线杂志中的应用
- 网页开发中的实用树形菜单插件应用
- 高压水清洗技术在储罐维修中的关键应用
- 流量计校正方法及操作指南
- WinCE系统下SD卡磁盘性能测试工具及代码解析
- ASP.NET学生管理系统的源码与数据库教程
