Kafka消费者重启与数据重置策略解析
需积分: 0 116 浏览量
更新于2024-08-04
收藏 120KB DOCX 举报
"Kafka常见问题解答"
在Kafka中,Replica的分配策略是一个关键的环节,它确保了数据的高可用性和容错性。在描述中提到的算法是简单的模运算分配法,即对所有的Broker和待分配的Partition进行排序,第i个Partition会分配到第(i mod n)+1个Broker上,其中n为Broker的总数。这种分配方式有助于均匀地分布Partitions,防止数据过于集中于某些Broker,从而提高系统的整体性能和稳定性。
然而,消费者在Kafka中的行为也是我们需要关注的重点。当消费者属于同一个消费组时,它们会共享一个消费进度,即offset。一旦数据被消费,offset会被更新并存储在ZooKeeper中,即使数据在Log文件中仍然存在,也不能再次被同一个消费组消费。这是Kafka的幂等性设计,确保消息不会被重复消费。
要消费已被消费过的数据,可以采取以下策略:
1. 使用不同的消费组:创建一个新的消费组,这样消费者就不会受到先前消费记录的影响,可以从头开始消费数据。
2. 配置`auto.commit.enable`和`auto.offset.reset`:关闭自动提交offset(将`auto.commit.enable`设为`false`),然后设置`auto.offset.reset`为`largest`或`smallest`,来决定从日志的最早或最近位置开始消费。
3. 使用`SimpleConsumer`:通过编程方式更精确地控制消费的起点。`kafka.api.OffsetRequest.EarliestTime()`允许从日志开始位置读取,而`kafka.api.OffsetRequest.LatestTime()`则只读取最新的日志数据。首先,确定要读取的topic和partition,然后找到对应的Broker Leader,向其发送Offset请求,以获取或设置所需的offset。
Kafka的这些特性使得用户可以根据业务需求灵活调整消费策略。例如,对于实时流处理,通常希望从最新的数据开始消费;而对于离线批处理或历史数据分析,可能需要回溯到较早的数据点。理解并掌握这些机制对于有效地利用Kafka至关重要。同时,合理地管理Consumer Group和offset,可以避免数据丢失或重复,保证数据处理的正确性。
kafka 常见问题
1、如果想消费已经被消费过的数据
consumer 是底层采用的是一个阻塞队列,只要一有 producer 生产数据,那 consumer 就会将
数据消费。当然这里会产生一个很严重的问题,如果你重启一消费者程序,那你连一条数据
都抓不到,但是 log 文件中明明可以看到所有数据都好好的存在。换句话说,一旦你消费过
这些数据,那你就无法再次用同一个 groupid 消费同一组数据了。
原 因 : 消 费 者 消 费 了 数 据 并 不 从 队 列 中 移 除 , 只 是 记 录 了 offset 偏 移 量 。 同 一 个
consumergroup 的所有 consumer 合起来消费一个 topic,并且他们每次消费的时候都会保存
一个 offset 参数在 zookeeper 的 root 上。如果此时某个 consumer 挂了或者新增一个 consumer
进程,将会触发 kafka 的负载均衡,暂时性的重启所有 consumer,重新分配哪个 consumer
去消费哪个 partition,然后再继续通过保存在 zookeeper 上的 offset 参数继续读取数据。注
意:offset 保存的是 consumer 组消费的消息偏移。
要消费同一组数据,你可以
1) 采用不同的 group。
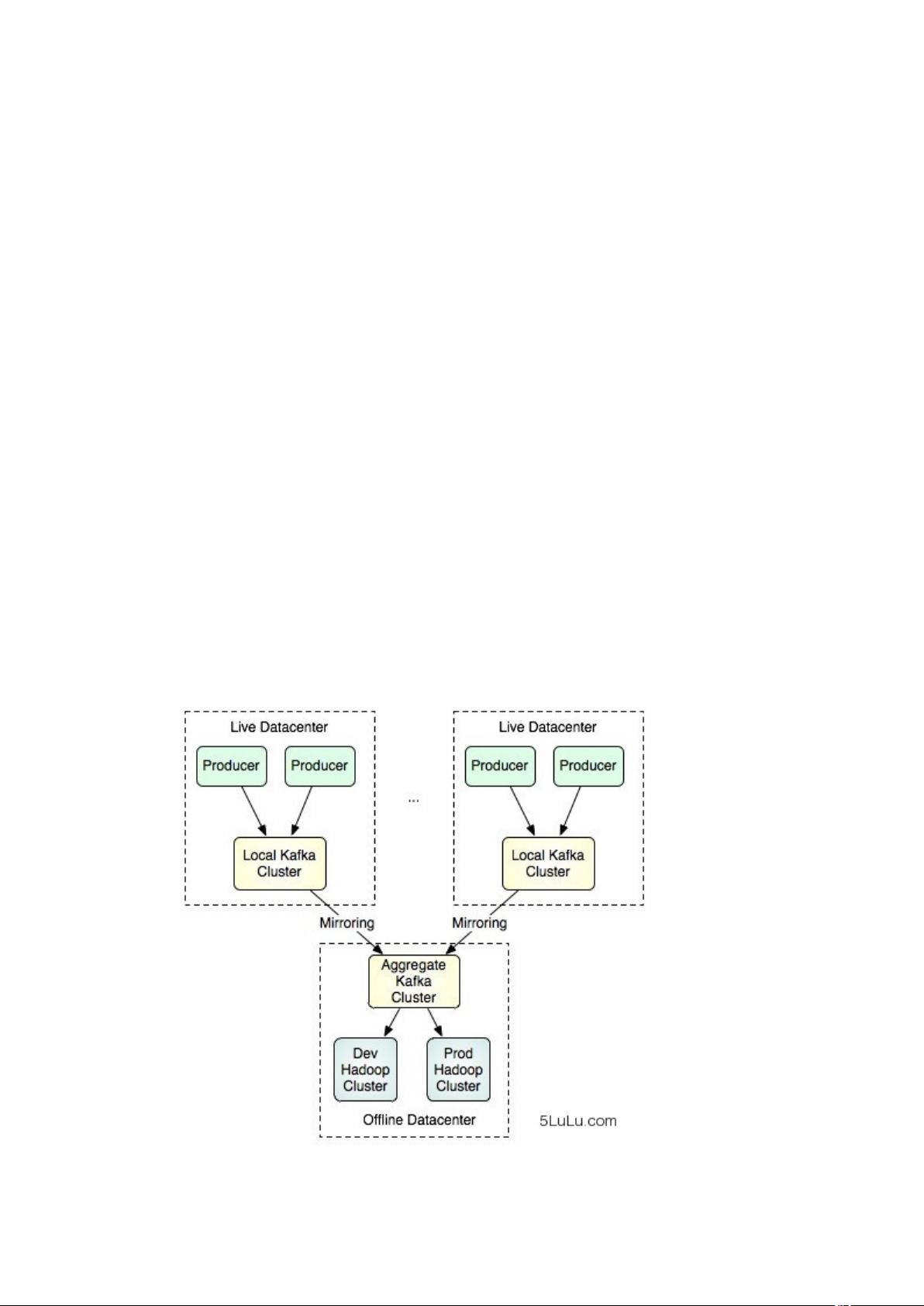
2) 通过一些配置,就可以将线上产生的数据同步到镜像中去,然后再由特定的集群区处理
大批量的数据。
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-20 上传
2023-12-12 上传
2020-06-29 上传
2021-10-26 上传

两斤香菜
- 粉丝: 19
- 资源: 297
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
