Informatica PowerCenter转换组件详解
需积分: 34 158 浏览量
更新于2024-09-17
收藏 1.38MB PDF 举报
"该文档是关于Informatica PowerCenter中常用转换组件的使用说明,涵盖了从基本的Expression到复杂的Joiner和Lookup等组件的介绍,包括它们的作用、用法以及一些关键属性设置。"
Informatica PowerCenter是一款强大的数据整合工具,其核心功能之一就是通过各种转换组件来处理和转换数据。以下是对各个组件的详细说明:
1. Expression (EXPTRANS):主要用于执行基于单行记录的表达式计算,可以进行任意非聚合计算。用户可以在Expression组件中添加所需字段,创建新的输出端口并编写表达式,确保端口数据类型与表达式结果匹配。
2. Aggregator (AGGTRANS):这个组件用于执行多组记录的聚合操作,如求和、平均值等。可以设置分组列,并定义聚合运算。配合Sort组件使用可以提升性能。其重要属性包括CacheDirectory(缓存目录)、SortedInput(预排序输入数据标志)、AggregatorDataCacheSize(数据缓存大小)和AggregatorIndexCacheSize(索引缓存大小)。
3. Union (UNTRANS):用于合并来自不同源的数据流,要求所有输入端口具有相同的数据类型和结构。命名惯例以UN_*开头。
4. SourceQualifier (SQTRANS):此组件用于在源连接和转换之间添加一个限定,确保数据符合PowerCenter的数据处理要求。命名规则为SQ_*
5. Filter (FILTRANS):过滤数据流,根据设定的条件保留或排除某些记录。命名约定为FIL_*
6. Router (RTRTRANS):根据字段值将数据路由到不同的输出路径,实现数据分流。命名规范为RTR_*
7. Sorter (SRTTRANS):对数据流进行排序,为聚合操作或其他需要有序数据的转换做准备。命名规则是SRT_*
8. UpdateStrategy (UPDTRANS):在更新数据库之前处理更新、插入和删除操作。命名惯例为UPD_*
9. Lookup (LKPTRANS):执行查找操作,从外部数据源中查找匹配项。命名约定为LKP_*
10. Joiner (JNRTRANS):实现不同数据流之间的连接,支持多种类型的连接操作。命名规则为JNR_*
11. SequenceGenerator (SEQTRANS):生成序列号或唯一标识符,通常用于主键生成。命名惯例为SEQ_*
12. Rank (RNKTRANS):根据指定的字段对数据进行排名,可以用于数据排序和分组分析。命名约定为RNK_*
每个组件都有其特定的用途和配置选项,理解并熟练运用这些组件是构建高效数据集成流程的关键。通过合理组合和配置这些组件,用户能够实现复杂的数据处理任务,包括数据清洗、转换、聚合、过滤、分组、排序和连接等,从而满足各种业务需求。在实际使用中,应根据具体项目需求选择合适的转换组件,并注意优化性能,如利用缓存和预排序等功能。
3
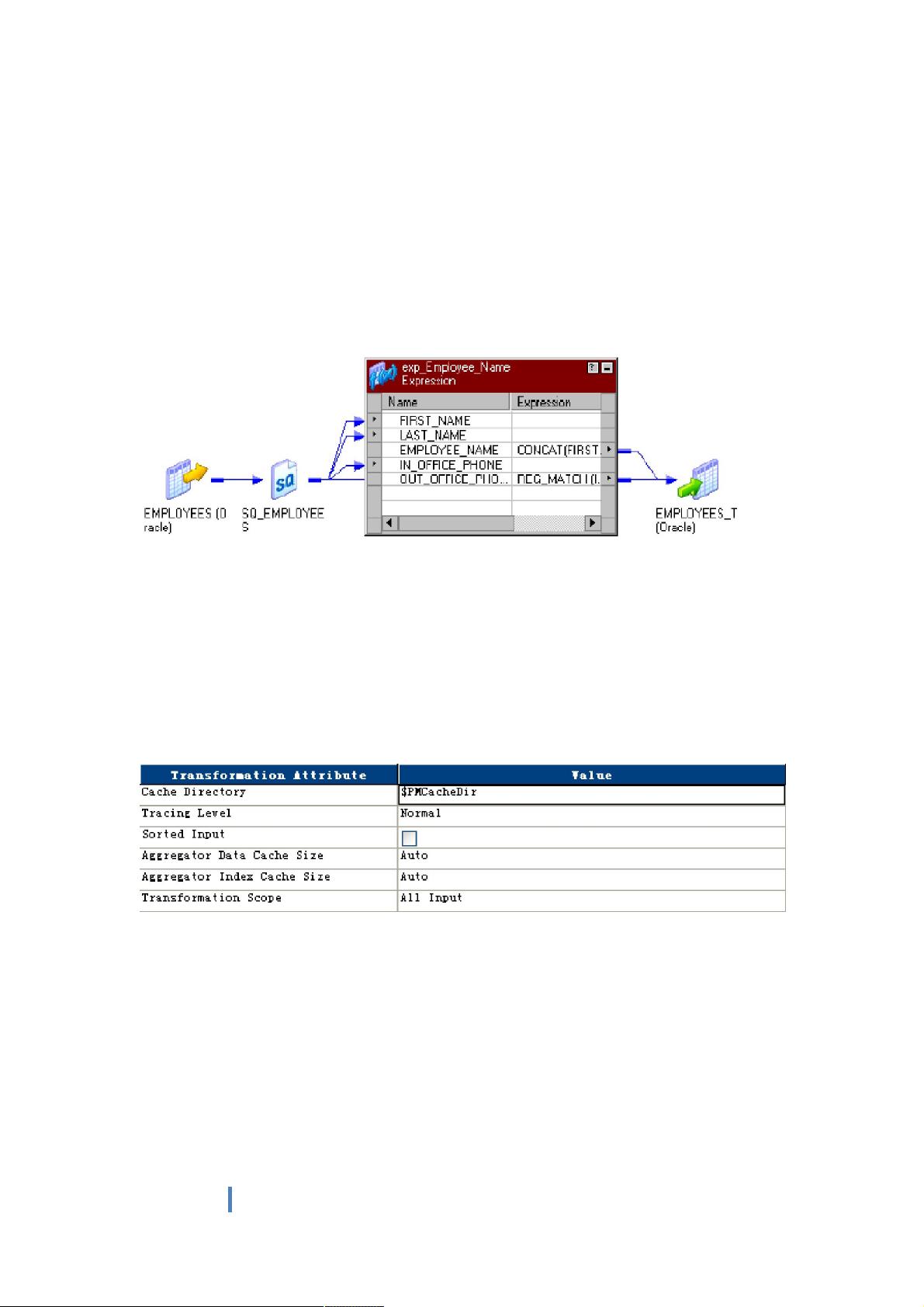
1 Expression
作用:实现基于单行记录的表达式计算,执行任意非聚合计算。
用法:创建 Expression 组件后,将需要用的字段从上一端口拖曳到 Expression 组件,双击组
件,打开编辑,新增创建所需的输出端口,只勾选“O”为只输出端口,在“Expression”中
编辑表达式,确保分配与表达式返回值相匹配的端口数据类型。输出端口的命名惯例为
OUT_PORTNAME。
可以利用一个 Expression 组件实现多个表达式转换工作,只要为多个输出端口输入一个
表达式,就可以在转换中创建任意多个输出端口。
2 Aggregator
作用:对多组记录执行聚合计算。
用法:将需要聚合运行的字段拖曳到 Aggregator 组件,双击组件,在 Port 选项卡中,勾选
要分组的列,新增输出端口,编辑聚合运算表达式。
与 sort 组件联合使用可提高性能。
常用属性:
Cache Directory 属性:创建索引和数据高速缓存文件的本地目录。
Sorted Input 属性:指示已按组预排序输入数据。用于改善会话性能。只有当映射将已
排序数据传递至聚合转换时,才选择此选项。
Aggregator Data Cache Size 属性:转换的数据高速缓存大小。
Aggregator Index Cache Size 属性:转换的索引高速缓存大小。
Transformation Scope 属性:指定 PowerCenter Server 如何将转换逻辑应用于接收数据:
-Transaction。将转换逻辑应用于事务中的所有行。如果数据行取决于同事务中的
所有行,但与其它事务中的行无关,则选择“Transaction”。
-All Input。将事务逻辑应用于所有传入数据。选择“All Input”时,PowerCenter
将放弃接收事务边界。如果数据行取决于源中的所有行,请选择“All Input”。
剩余11页未读,继续阅读
2011-07-21 上传
2023-07-30 上传
2023-09-12 上传
2023-07-28 上传
2023-05-12 上传
2023-11-30 上传
2024-06-30 上传
2023-07-12 上传
2023-06-27 上传

xld68
- 粉丝: 2
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
