深入解析HashMap原理与性能优化:从实现到实战
131 浏览量
更新于2024-08-29
收藏 542KB PDF 举报
HashMap原理分析及性能优化是一篇深入探讨Java中HashMap数据结构的关键文章,该数据结构在Java开发中被广泛应用,用于存储键值对。HashMap的设计核心在于其高效的数据存储和查找机制。
首先,HashMap是`java.util.Map`接口的一个实现,它基于键的`hashCode()`函数来确定存储位置,这使得在大多数情况下,插入和查找操作的时间复杂度可以达到O(1),提供了快速的访问速度。每个键值对(Entry)都存储在HashMap的主要组成部分——数组(Node[] table)中,数组下标由键的哈希码决定。
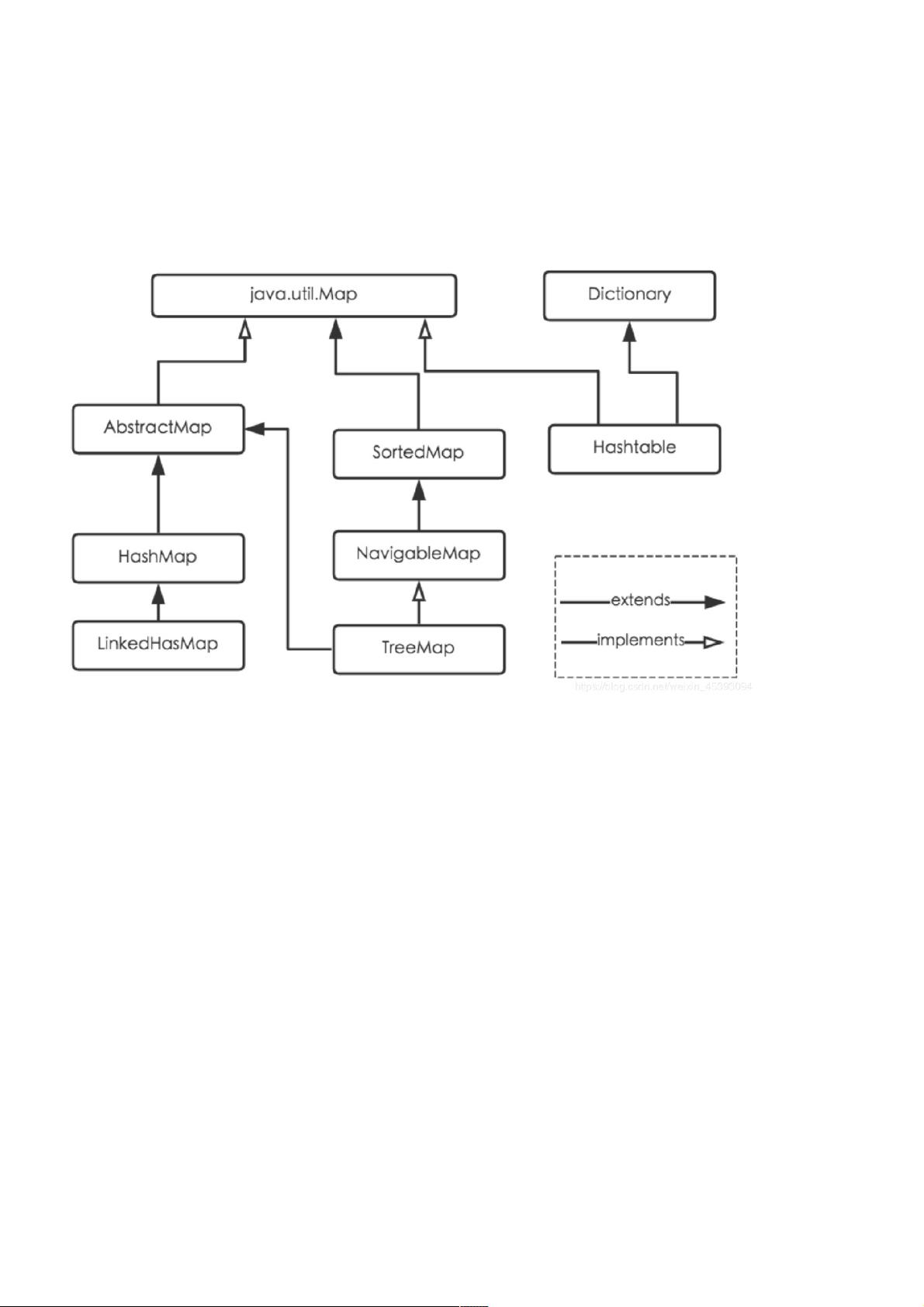
文章接着对比了HashMap与其继承类的关系,包括:
1. **HashMap**:它是最直接的实现,使用哈希表结构(数组+链表/红黑树),允许单个键为null,但值可以有多个为null。HashMap是非线程安全的,这意味着在多线程环境下可能造成数据一致性问题。若需线程安全,可以使用`synchronizedMap()`或`ConcurrentHashMap`。
2. **Hashtable**:作为遗留类,虽然功能类似HashMap,但它是线程安全的,仅允许单个线程写入。由于其线程同步机制,性能上会稍逊于HashMap。在新代码中,通常推荐使用HashMap,对于需要线程安全的场景,可以选择ConcurrentHashMap。
3. **LinkedHashMap**:它是HashMap的子类,保持元素的插入顺序,这对于需要保持插入顺序的应用场景很有价值。可以通过构造器指定访问顺序。
文章还详细解析了HashMap的内部机制,例如如何通过哈希函数计算数组索引,以及put方法的工作流程,包括碰撞处理和扩容策略。最后,讲解了HashMap的线程安全性问题和相应的解决方案。
理解并优化HashMap的性能至关重要,尤其是在高并发和对顺序性要求较高的场景。通过本文的学习,开发者可以更好地利用HashMap并避免潜在的问题,提高代码的效率和可维护性。
HashMap原理分析及性能优化原理分析及性能优化
文章目录文章目录一.HashMap是什么二.HashMap继承类对比分析三.HashMap源码相关单词含义四.HashMap如何确定哈希桶数组索引位置五. HashMap 的 put 方法分析六.HashMap扩容机
制七.HashMap线程安全性
一一.HashMap是什么是什么
HashMap是Java程序员使用频率最高的用于映射(键值对)处理的数据类型。
HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。
数据结构(JDK1.8):Node[] table; 数组+链表+红黑树
二二.HashMap继承类对比分析继承类对比分析
Java为数据结构中的映射定义了一个接口java.util.Map,此接口主要有四个常用的实现类,分别是HashMap、Hashtable、LinkedHashMap和TreeMap,
类继承关系如下图所示:
① HashMap :它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是确定的。 HashMap最多只允许一条记录的键为
null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的一致。如果需要满足线程安全,可以
CollectionssynchronizedMap方法使HashMap具有线程安全的能,或者使用ConcurrentHashMap。
②Hashtable :Hashtable是遗类,很多映射的常用功能与HashMap类似,同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性如
ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable建议在新代码中使用,需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用
ConcurrentHashMap替换。
③LinkedHashMap :LinkedHashMap是HashMap的一个子类,保存记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,
按照访问次序排序。
④TreeMap :TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较,当用Iterator遍历TreeMap时,得到的记录是排过序
的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运时抛出
java.lang.ClassCastException类型的异常。
小结小结:HashMap线程不安全,HashTable安全但是一般不会使用,如果要排序可以使用TreeMap
三三.HashMap源码相关单词含义源码相关单词含义
size,k-v的数量,map集合元素的个数
initialCapacity,初始容量,默认值为16,是一个折中值,不是太小也不是太大
capacity,容量,桶的数量=数组的长度
loadFactor,装载因子=size/ capacity,用来衡量表满的程度,默认为0.75是一个经验值,不会太满,也不会太少
threshold,扩容阀值,当表的size超过threshold时执行扩容操作= capacity * loadFactor
capacity+ loadFactor共同确定了hash表扩容时机
下面功能上会从以下四个方面分析下面功能上会从以下四个方面分析
下载后可阅读完整内容,剩余4页未读,立即下载
2020-09-02 上传
2014-10-15 上传
2020-09-02 上传
点击了解资源详情
2020-09-07 上传
2020-12-22 上传
2017-07-22 上传
点击了解资源详情
点击了解资源详情

weixin_38677585
- 粉丝: 5
- 资源: 938
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
