机器学习实战:Logistic回归深度解析
需积分: 29 114 浏览量
更新于2024-08-04
1
收藏 1.05MB PDF 举报
"《机器学习实战》第五章Logistic回归学习笔记主要讲解了Logistic回归的概念、应用及其在实际操作中的流程。Logistic回归是一种分类算法,它通过Sigmoid函数将连续的预测值转化为0或1的概率输出,适用于处理二分类问题。笔记详细介绍了Logistic回归的过程,包括数据收集、数据准备、数据分析、训练算法、测试算法以及使用算法的步骤。此外,还探讨了Logistic回归的优缺点和适用数据类型。在确定最佳回归系数时,引入了最优化方法,特别是梯度上升法,用于寻找使模型性能最优的参数。"
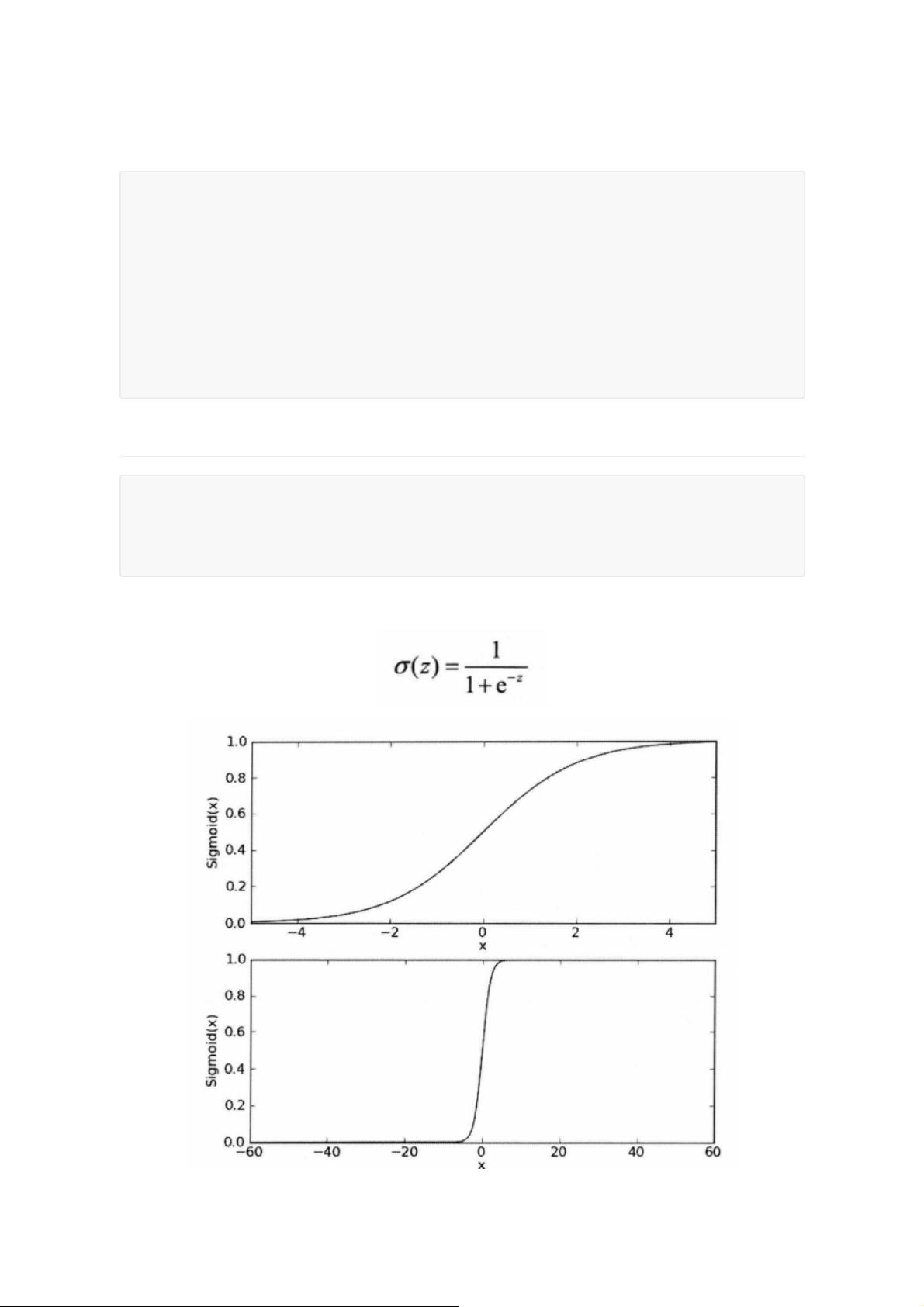
在Logistic回归中,回归并不意味着寻找最佳拟合直线,而是构建一个分类边界,使得数据点被正确分类。Sigmoid函数在此起着关键作用,它的输出范围限定在0到1之间,可以解释为正类的概率。当Sigmoid函数的输入z(特征与权重的线性组合)足够大时,输出接近1,反之接近0,从而实现分类。
训练Logistic回归模型的过程涉及以下步骤:
1. 收集数据:收集相关的数据集,用于训练模型。
2. 准备数据:将非数值型数据转换为数值型,确保数据适合进行数学计算,并且推荐使用结构化的数据格式。
3. 分析数据:对数据进行探索性分析,理解数据特性,发现潜在的关联或异常。
4. 训练算法:利用梯度上升法或其他优化算法调整权重,以找到最佳分类边界。
5. 测试算法:使用独立的数据集验证模型的性能,评估其分类准确性。
6. 使用算法:输入新数据,经过模型计算得出概率,依据阈值(通常为0.5)进行分类。
Logistic回归的优势在于其简单性和计算效率,但可能面临欠拟合问题,导致分类精度不高。它可以处理数值型和标称型数据,对于二分类问题尤为适用。在寻找最佳回归系数时,梯度上升法是一种常用方法,通过不断迭代更新参数,使损失函数(如对数似然损失)逐渐减小,从而达到优化模型的目的。
在实践中,梯度上升法会反复计算梯度,确定每次迭代的步长和方向,直至满足停止条件(如达到预设的迭代次数、梯度接近零或损失函数变化极小)。通过这种方式,Logistic回归能够找到一组权重,使得模型对训练数据的分类效果最佳,进而用于未知数据的预测。
回归:用一条直线对一些数据点进行拟合,该线称为最佳拟合直线。
Logistic回归主要思想:根据现有数据对分类边界线建立回归公式,回归线左右两侧标签值不同。
5.1基于Logistic回归和Sigmoid函数的分类
Sigmoid函数在跳跃点上从0瞬间跳跃到1,这个瞬间跳跃过程更易处理。
Logistic回归的一般过程
(1)收集数据:采用任意方法收集数据。
(2)准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据
格式则最佳。
(3)分析数据:采用任意方法对数据进行分析。
(4)训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
(5)测试算法:一旦训练步骤完成,分类将会很快。
(6)使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数
就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一
些其他分析工作。
Logistic回归
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
适用数据类型:数值型和标称型数据。
下载后可阅读完整内容,剩余8页未读,立即下载
2021-04-01 上传
2023-01-14 上传
2021-06-10 上传
2021-10-01 上传
2019-09-12 上传

Mr.狐友
- 粉丝: 581
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
