集合选择器驱动的粗糙集半监督特征选择方法
需积分: 5 11 浏览量
更新于2024-07-10
收藏 2.13MB PDF 举报
"通过集合选择器进行基于粗糙集的半监督特征选择"
这篇研究论文探讨了在半监督学习环境下,利用粗糙集理论进行特征选择的一种新方法,即通过集合选择器(ensemble selector)来优化特征子集。半监督学习是一种介于有监督学习和无监督学习之间的机器学习方法,特别适用于大量未标记数据和少量标记数据的情况。在这种环境中,特征选择尤其重要,因为它可以帮助提高模型的泛化能力,减少过拟合风险,并降低计算复杂度。
粗糙集理论是数据挖掘和知识发现的一个重要工具,它允许在不完全信息的情况下进行决策和知识提取。在特征选择中,粗糙集通过比较不同特征对决策边界的影响来识别冗余或不重要的特征。论文中提到的“邻居粗糙集”是粗糙集理论的一种变体,它利用数据实例的局部邻域信息来评估特征的重要性。
论文介绍的集合选择器方法是将多个单个特征选择器(如基于粗糙集的筛选方法)组合起来,形成一个集成模型。这种集成方法可以提高特征选择的稳定性和准确性,因为不同的选择器可能会捕获数据的不同方面。通过集成多个选择器的结果,可以得到更稳健的特征子集,从而在半监督学习任务中取得更好的性能。
文章详细描述了算法的实现过程,包括如何构建和训练单个选择器,如何结合这些选择器的决策,以及如何在部分标记数据上评估所选特征的有效性。此外,作者们还可能对比了他们的方法与传统的有监督和无监督特征选择方法,以证明其在处理部分标记数据时的优势。
关键词包括:集合选择器、特征选择、邻居粗糙集、部分标记数据和半监督学习。这些关键词揭示了论文的主要研究焦点,即在半监督环境中,如何利用粗糙集和集成学习策略进行有效的特征选择,以应对数据标注不足的挑战。
这篇论文为半监督学习环境下的特征选择提供了一种新的解决方案,利用粗糙集理论和集合选择器的思想,提高了在部分标记数据上的学习性能。这种方法对于处理大规模、标注成本高的数据集具有实际应用价值,特别是在数据科学和机器学习领域。
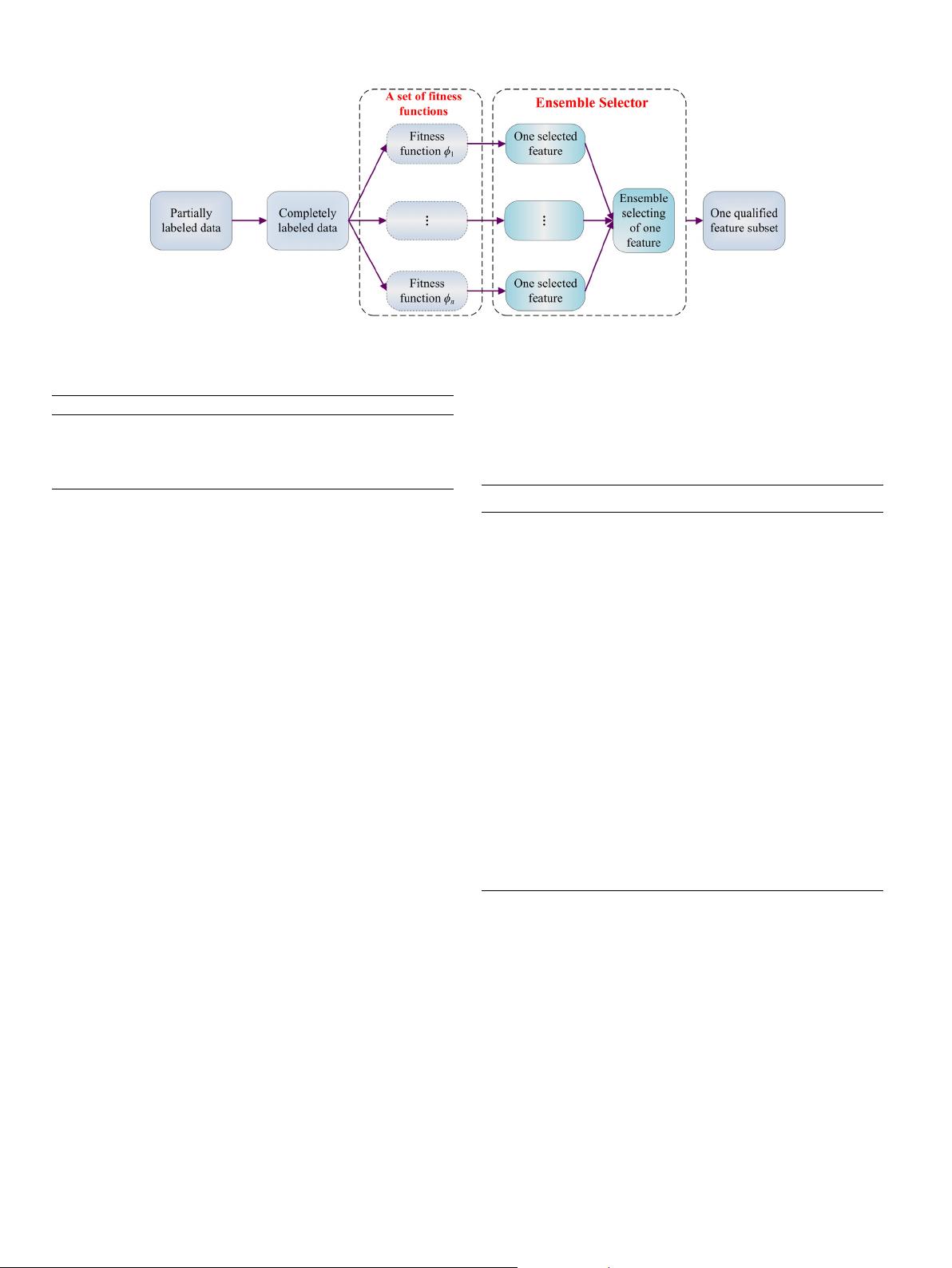
284 K. Liu, X. Yang, H. Yu et al. / Knowledge-Based Systems 165 (2019) 282–296
Fig. 2. Rough set based semi-supervised feature selection via ensemble selector.
Table 1
A decision system for partially labeled data.
U
l
∪ U
u
a
1
a
2
a
3
d
x
1
0.1 0.3 0.1 1
x
2
0.1 0.3 0.2 2
x
3
0.3 0.1 0.2 1
x
4
0.2 0.3 0.1 ∗
x
5
0.2 0.1 0.3 ∗
2.2. Semi-supervised feature selection methods for partially labeled
data
It is universally acknowledged that most of the traditional
feature selection methods are not suitable for dealing with par-
tially labeled data. To solve such problem, recently, various semi-
supervised feature selection methods have been proposed to han-
dle partially labeled data. As what have been pointed out in Sec-
tion 1, two frameworks of semi-supervised feature selections have
been addressed in partially labeled data. In the first framework, the
unlabeled samples should be predicted before feature selection,
and it follows that partially labeled data can be transformed into
completely labeled data. For example, in Refs. [16,19,20,52], var-
ious approaches included in this framework have been explored.
And in the second framework, the measurements for evaluating
the significance of each candidate feature are constructed by con-
sidering both labeled and unlabeled samples simultaneously. For
instance, a rough set based approach for measuring the significance
of feature has been reported by Dai et al. in Ref. [15].
2.2.1. Forward semi-supervised feature selection
As a representative method in the first framework, through
assigning labels to the unlabeled samples in partially labeled data,
Forward Semi-supervised Feature Selection (FSFS) proposed by
Ren et al. in Ref. [16], has been paid much attention by many
researchers.
The main process of FSFS includes the following four steps:
1. Supervised-sequential Forward Feature Selection (SFFS), one
of the most widely adopted supervised feature selection
methods, is used to select some features initially over the
labeled samples;
2. The selected features obtained in the first step are used to
train a classifier, and then the raw unlabeled samples can be
predicted based on such classifier;
3. Some updated labeled samples are randomly selected based
on a given sampling rate and combined with the raw labeled
samples, the new joint labeled samples are formed, and then
a feature subset is obtained over such joint labeled samples
through using SFFS;
4. The above step is repeated several times and then several
feature subsets have been obtained, the most frequently
selected feature which is not in the feature subset derived
by the first step is added into such subset.
The detailed algorithm of FSFS is described as follows.
Algorithm 1. Forward Semi-supervised Feature Selection (FSFS)
Inputs: DS, sampling rate ρ, sampling times s and entire itera-
tion times t;
Outputs: A qualified feature subset A.
1. A ← ∅;
2. Obtain the initial feature subset R in U
l
by using SFFS and
then A ← R;
3. For p =1 to t
(1) Train a classifier over U
l
with respect to A;
(2) ∀x
u
∈ U
u
, obtain the predicted labels of x
u
as d(x
u
);
(3) For q = 1 to s
(i) By ratio ρ, randomly select a set of samples in
U
u
, it is denoted by U
u
ρ
;
(ii) U
l∗
← U
l
∪ (U
u
ρ
);
(iii) Obtain the random feature subset A
q
in U
l∗
;
End For
(4) Obtain random feature subsets A
1
, A
2
, . . . , A
s
, find
the feature b which is the most frequently selected
in these random feature subsets while it is not in
A;
(5) A ← A ∪ {b};
End For
4. Return A.
Remark 1. The time complexity of SFFS is O(|U
l
|
2
× |AT |
2
). More-
over, the neighborhood classifier [53] is used to predict the unla-
beled samples in this paper and then the time complexity of the
third step is O(|U
l
|
2
× |AT | × t + |U
l∗
|
2
× |AT |
2
× s × t). Finally,
the overall complexity of Algorithm 1 is O(|U
l
|
2
× |AT |
2
+ |U
l
|
2
×
|AT | × t + |U
l∗
|
2
× |AT |
2
× s × t).
2.2.2. Rough set based semi-supervised feature selection
The above approach aims to transform the unlabeled samples
into labeled samples by some techniques and then execute feature
selection over the updated labeled samples. Another natural think-
ing is to execute feature selection over the whole data without
predicting the unlabeled samples. Such strategy requires the evalu-
ation of the significance of feature by considering both labeled and
unlabeled samples, simultaneously. From this point of view, Dai
et al. [15] have proposed a typical Rough set based Semi-supervised
剩余14页未读,继续阅读
2009-01-16 上传
2019-09-06 上传
2021-03-10 上传
2019-08-14 上传
2018-04-23 上传
2020-07-03 上传
2021-02-24 上传
2021-05-18 上传
2021-03-08 上传

weixin_38540782
- 粉丝: 4
- 资源: 870
 我的内容管理
展开
我的内容管理
展开







最新资源
- Material Design 示例:展示Android材料设计的应用
- 农产品供销服务系统设计与实现
- Java实现两个数字相加的基本代码示例
- Delphi代码生成器:模板引擎与数据库实体类
- 三菱PLC控制四台电机启动程序解析
- SSM+Vue智能停车场管理系统的实现与源码分析
- Java帮助系统代码实现与解析
- 开发台:自由职业者专用的MEAN堆栈客户端管理工具
- SSM+Vue房屋租赁系统开发实战(含源码与教程)
- Java实现最大公约数与最小公倍数算法
- 构建模块化AngularJS应用的四边形工具
- SSM+Vue抗疫医疗销售平台源码教程
- 掌握Spring Expression Language及其应用
- 20页可爱卡通手绘儿童旅游相册PPT模板
- JavaWebWidget框架:简化Web应用开发
- 深入探讨Spring Boot框架与其他组件的集成应用
