HANA存储过程与计算视图对比解析
需积分: 16 148 浏览量
更新于2024-09-09
收藏 398KB DOCX 举报
"该文档详细介绍了HANA存储过程的创建、使用和与计算视图的对比,旨在帮助读者深入理解这两种数据处理方法。文档通过举例和对比两种创建存储过程的方法——使用SQLEditor和创建向导,阐述了它们的异同,并涉及到权限模式、访问模式以及参数类型等关键概念。此外,还提到了存储过程的执行和调用方式。"
在SAP HANA数据库系统中,存储过程是一种可重复使用的程序模块,它可以采用SQLScript、L或R语言编写。存储过程的创建有两种主要途径:一是利用SQL Editor,二是通过Package的创建向导。这两种方式在保存位置、调用方式和参数处理上存在差异。
1. 使用SQL Editor创建存储过程时,你需要提供执行语言(默认为SQLScript)、权限模式(Definer或Invoker)以及访问模式(如READ ONLY)。你可以定义输入参数(支持基本类型和自定义表类型)和输出参数(同样支持基本类型和自定义表类型),并且可以使用WITHRESULTVIEW来创建一个列视图,其数据来源于存储过程的表类型输出参数。存储过程将被保存在特定的目录下。
2. 创建向导则提供了更为直观的界面,可以设定存储过程的名称、描述、默认Schema、运行权限(Definer或Invoker)以及语言。在这个向导中,输出参数必须是自定义的未预先定义的表类型,会在参数定义阶段自动创建。这种方式创建的存储过程也会被保存到指定目录,并在_SYS_BIC下生成相应的对象。
调用存储过程通常通过SQL Editor执行相关的SQL命令,或者在应用中集成调用。对于Definer权限的存储过程,只有拥有特定权限的用户才能执行;而Invoker权限的存储过程,系统会根据调用用户的权限来执行。
计算视图,另一方面,是HANA中用于构建复杂查询逻辑的视图,它可以组合多个源表、视图或函数,形成一个新的逻辑数据源。虽然存储过程和计算视图在某些方面有所重叠,如都可以实现复杂的业务逻辑,但它们在用途和执行机制上有所不同。计算视图主要用于数据的实时聚合和转换,而存储过程更侧重于封装可重复的业务逻辑,允许接受参数并返回结果。
通过对比分析,我们可以更好地理解何时使用存储过程,何时使用计算视图,从而优化HANA数据库中的数据处理流程。对于开发和DBA来说,了解这些细节对于提升系统的性能和可维护性至关重要。
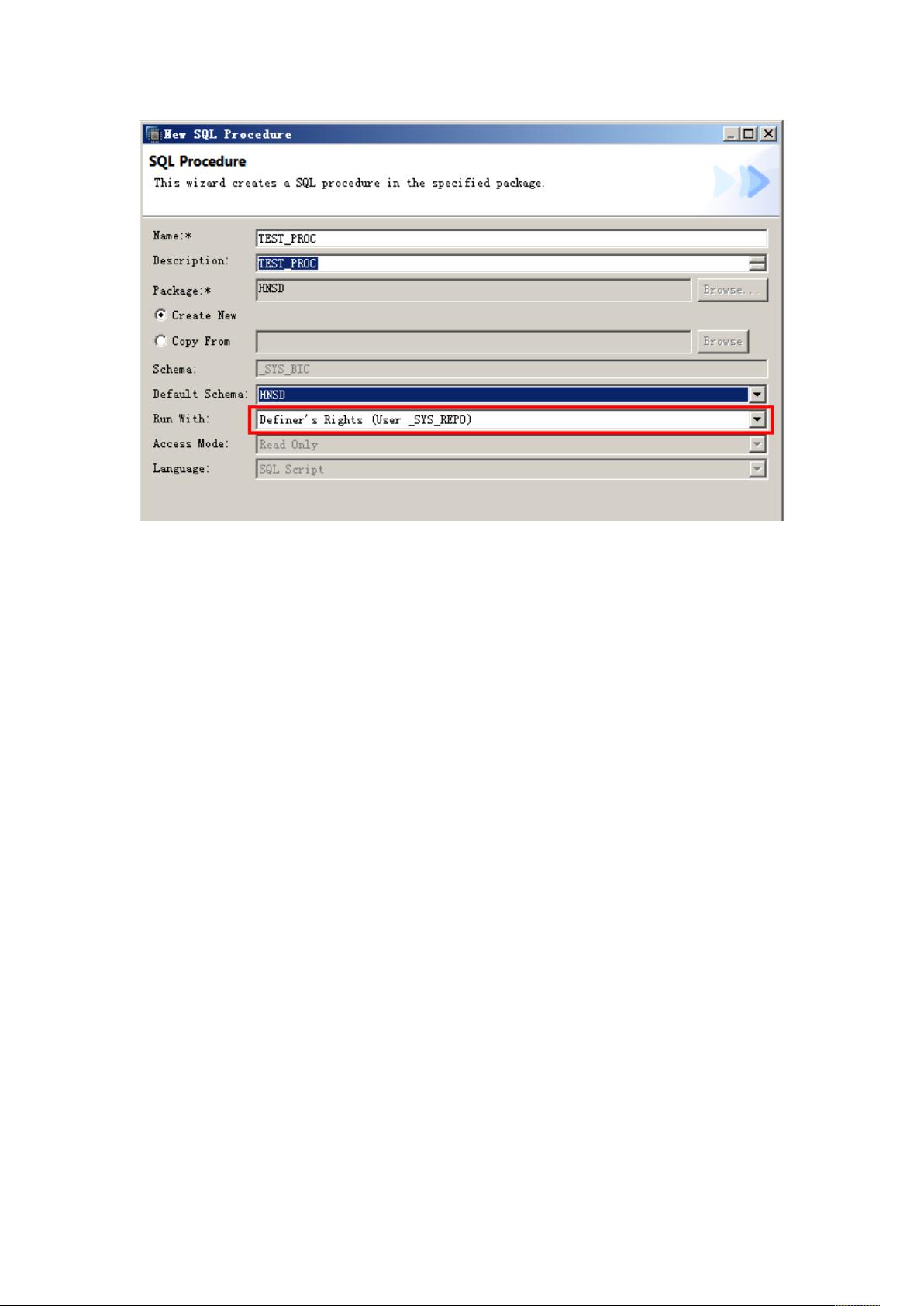
如上图所示,在创建页面有如下属性
-:存储过程名称
1":存储过程描述
2,&3- :默认的 3- 名称, 建议 选择 用户 所属 的 3- , 这个 关系 着在
4546) 中的存储过程名称
,"(3:!"定义者权限,)"#调用者权限,定义者权限将会限制其他用户调用该
存储过程,调用者权限将允许系统向其他用户授权调用该存储过程。
:"&',%(,但是在现使用 , 中不可选
",:,,,但是在现使用 , 中不可选
如下图,为存储过程的脚本编辑视图
剩余10页未读,继续阅读
2020-09-03 上传
2022-07-15 上传
2015-12-17 上传
2022-09-21 上传
2022-09-24 上传
2022-09-22 上传
2022-09-19 上传
2022-07-15 上传
2022-09-24 上传

hujue1
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Accuinsight-1.0.31-py2.py3-none-any.whl.zip
- 图上的交互式回归:通过手动选择回归区域对图中的绘制数据执行回归。-matlab开发
- ranvid:视频租赁店
- .NET网上鲜花销售系统的ASP毕业设计(源代码+论文).zip
- 转移学习
- MyWorks:这是我工作的地方
- fastformer:fastformer模型,数据和培训代码
- ShiroExploit-Deprecated:Shiro550Shiro721一键化利用工具,支持多种回显方式
- 基于PHP的最新小储云商城V1.782免授权PHP源码.zip
- numeric-expression-parser:可以处理歧义的数字表达式的解析器。 它可以在前缀和后缀中转换中缀表示法,并可以评估结果
- 神经控制教程 - 灵活旋转关节的应用:西班牙语教程,关于神经控制。 仅用于学术和教育用途。-matlab开发
- VS2019插件:ClaudiaIDE+ColorThemeEditor.rar
- templates:模板和脚本
- aabbtree-2.7.0-py2.py3-none-any.whl.zip
- Blue_Dentures:终极蓝牙伴侣计划。一套用于蓝牙的数字假牙
- 无 RS 码的 ofdm 传输与数字调制技术的比较:这是 OFDM 传输,无需 RSCode。也通过数字调制技术(bpsk,-matlab开发
