从入门到实践:自建网络爬虫教程
需积分: 11 59 浏览量
更新于2024-07-28
收藏 2.49MB PDF 举报
网络爬虫是一种自动化工具,用于在网络上抓取和解析数据,以满足各种信息需求。在本篇文章中,我们将深入探讨如何自己动手编写网络爬虫,从基础的网页抓取开始。首先,了解网络爬虫的工作原理与搜索引擎的工作模式,比如百度、Google的Spider(网络爬虫程序)如何实时抓取和更新大量网页。
章节1详细讲解了抓取网页的步骤,首先从URL(Uniform Resource Locator,统一资源定位符)入手。URL是用户在浏览器地址栏输入的标识符,用于定位网络上的资源,它通常由三部分构成:访问机制、主机名和资源路径。例如,`http://www.webmonkey.com.cn/html/h` 是一个典型的URL示例。
通过浏览器访问网页的过程,实际上是浏览器作为客户端向服务器发送请求,服务器响应后将资源内容发送回客户端。用户可以通过查看源文件(如图1.2所示),了解抓取的原始HTML代码。在实际操作中,我们可以通过编程实现抓取,这里提到的一个例子是使用Java语言进行网页抓取,并关注HTTP状态码,这是抓取过程中非常关键的一部分,因为它反映了服务器对请求的响应状态。
抓取过程中,处理HTTP状态码至关重要。常见的状态码包括200(成功)、404(未找到)和500(服务器内部错误)等。理解这些状态码可以帮助我们判断请求是否成功,以及如何处理可能的错误情况。
在企业环境中,自建网络爬虫可以整合和利用大量数据,将其作为数据分析和决策支持的重要来源。例如,抓取股票信息可以支持金融分析,而数据仓库则可能利用爬取的数据构建多维度的业务报告。网络爬虫技术的应用范围广泛,从政府机构到个人用户,都有其价值所在。
总结来说,本文将引导读者学习如何设计和实现自己的网络爬虫,掌握从理解URL到处理HTTP状态码的基础技能,以及如何将这些技术应用到实际场景中,以满足个性化和专业化的信息采集需求。通过本文的学习,读者将具备独立创建网络爬虫的能力,能够在信息海洋中自如地获取所需的数据。
12
1
的遍历的方式对互联网这个超级大 “ 图 ” 进行访问。图的遍历通常可分为宽度优先遍历和
深度优先遍历两种方式。但是深度优先遍历可能会在深度上过 “ 深 ” 地遍历或者陷入 “ 黑
洞 ” ,大多数爬虫都不采用这种方式。另一方面,在爬取的时候,有时候也不能完全按照
宽度优先遍历的方式 , 而是给待遍历的网页赋予一定的优先级 , 根据这个优先级进行遍历
,
这种方法称为带偏好的遍历。本小节会分别介绍宽度优先遍历和带偏好的遍历。
1.2.1 图的宽度优先遍历
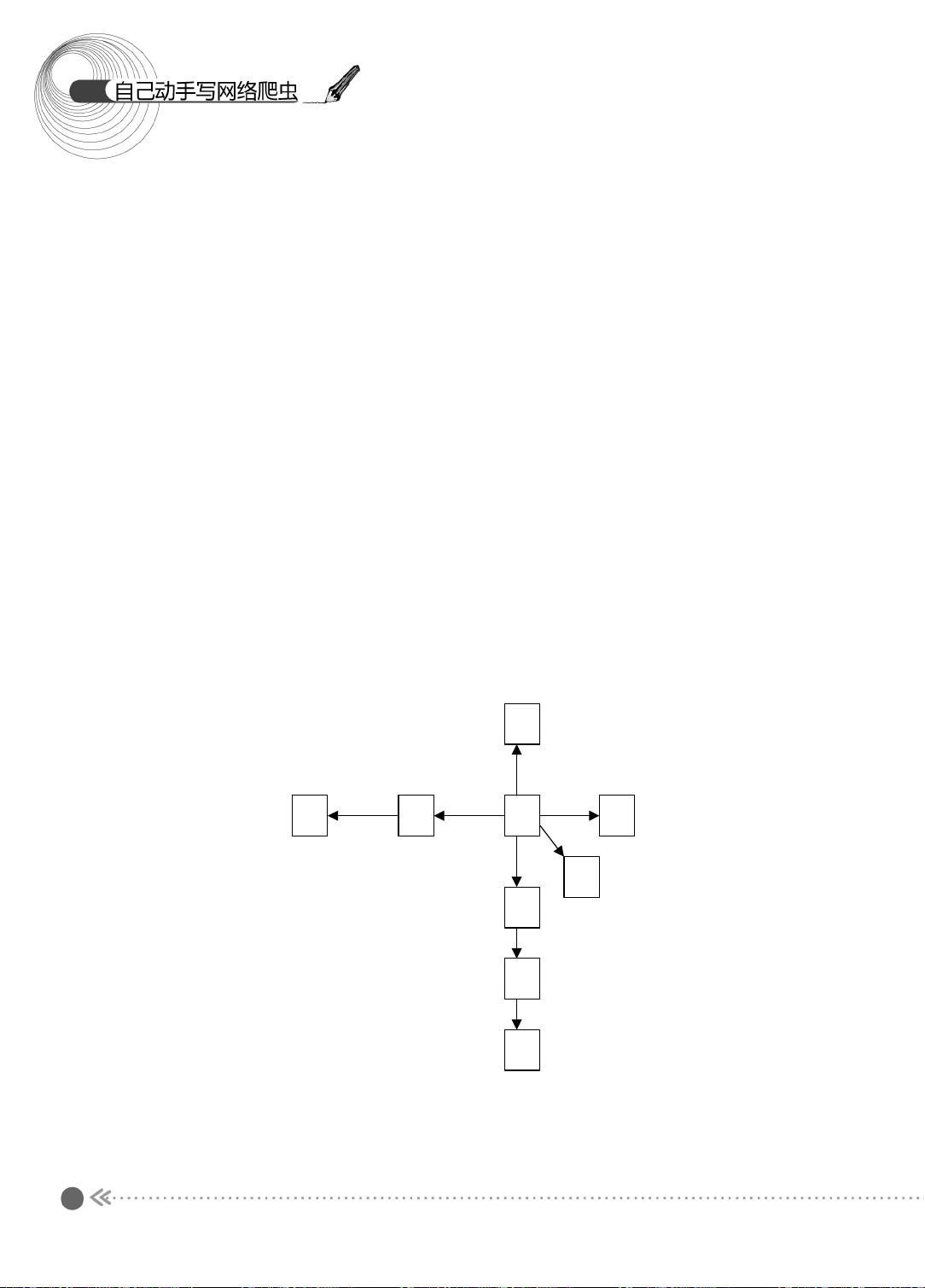
下面先来看看图的宽度优先遍历过程 。 图的宽度优先遍历 (BFS) 算法是一个分层搜索的
过程,和树的层序遍历算法相同。在图中选中一个节点,作为起始节点,然后按照层次遍
历的方式,一层一层地进行访问。
图的宽度优先遍历需要一个队列作为保存当前节点的子节点的数据结构。具体的算法
如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V ,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col 。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col ,转到步骤 (5) ,若 V 的所有邻接顶点都已经被访
问过,则转到步骤 (2) 。
下面,我们以图示的方式介绍宽度优先遍历的过程,如图 1.3 所示。
G
B
A
C
D
F
E
I
H
图 1.3 宽度优先遍历过程

剩余67页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-12-25 上传

wimdl5461
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 2019-is262b-techdmgt:is262b类访问的回购
- 基于java的开发源码-很不错的计算器.zip
- Royale:加利福尼亚州阿纳海姆市-Minecon 2016展览展示。 大逃杀
- poker:扑克培训网站
- GGRD_DataBase
- good-for-nothing-compiler:这是 Joel Pobar 和 Joe Duffy 于 2005 年在 PDC 上提出的 C# 中旧的 Good for Nothing Compiler 的延续
- 基于java的开发源码-局域网广播系统Java源码.zip
- PML-30:在Phys-Math Lyceum 30的“ CGSG”课程中制作的项目
- DesignPatterns:Java23种设计模式代码练习
- DSW-FedericoMurillo
- JS调试工具源码-易语言
- roformer-pytorch:Roformer的实现,这是一种带有旋转位置嵌入的变压器,这是一种未公开的相对位置编码新技术,正在中国的NLP圈子中流传
- 行业分类-设备装置-可随升降架运动的独立转料平台.zip
- Estudos-em-Geral:Projetos criados nas aulas e cursos
- JMS:基于Apache ActiveMQ JMS实现的远程服务分发提供程序
- node-redis-namespace:命名空间 Redis 键
