Apache Kylin 3.0新特性:使用Livy优雅管理Spark任务
186 浏览量
更新于2024-09-02
收藏 565KB PDF 举报
"Apache Kylin 3.0版本引入了使用Apache Livy递交Spark任务的功能,解决了用户在使用Spark时遇到的任务提交问题和构建节点稳定性问题。Apache Livy是一个基于Spark的开源REST服务,允许通过REST接口提交代码片段或序列化二进制代码到Spark集群执行,提供对Scala、Python和R语言的支持。使用Livy可以解决Spark的交互式处理和批处理方式带来的如资源负担、单点故障和管理不便等问题。Livy作为中间层,能减轻Gateway节点压力,支持远程提交和管理Spark任务,且便于集成审计和权限管理工具,如Apache Knox。"
Apache Kylin是一款开源的分布式分析型数据库,设计用于大数据分析,提供亚秒级的查询性能。在Kylin中优雅地使用Spark涉及到如何有效地利用Spark处理大规模数据。在传统的Spark使用中,用户通常需要直接在Gateway节点上提交和管理任务,这可能导致资源过度消耗和故障风险增加。Apache Livy作为解决方案,它作为一个RESTful服务,提供了一个安全、可扩展的途径,使得用户可以通过网络远程提交Spark作业,降低了对Gateway节点的依赖。
Livy的核心特性包括:
1. **代码片段提交**:用户可以提交Scala、Python或R的代码片段,Livy会将这些代码发送到Spark集群执行。
2. **Spark作业提交**:Java、Scala、Python编写的Spark作业可以通过Livy提交到远端集群,无需直接在Gateway节点执行。
3. **作业管理和监控**:Livy管理所有由用户启动的Spark任务,提供了状态查询、日志查看等功能。
4. **安全性与集成**:Livy支持身份验证和授权,方便与现有系统(如Apache Knox)集成,提供更好的安全性和审计能力。
通过集成Livy,Apache Kylin 3.0版本增强了其Spark任务的提交和管理体验,降低了系统的复杂性,提高了系统的稳定性和可靠性。这使得Kylin用户能够更高效、安全地处理大数据分析任务,避免了直接操作Spark集群可能带来的问题,同时提升了整体的运维效率。在实际应用中,开发人员和数据分析师可以利用这一特性,更便捷地构建和运行复杂的分析模型,进一步提升大数据分析的速度和质量。
如何在如何在 Kylin 中优雅地使用中优雅地使用 Spark
前言前言
Kylin 用户在使用 Spark的过程中,经常会遇到任务提交缓慢、构建节点不稳定的问题。为了更方便地向 Spark 提交、管理和监控任务,有些用户会使用 Livy 作为 Spark 的交互接口。在最新的 Apache
Kylin 3.0 版本中,Kylin 加入了通过 Apache Livy 递交 Spark 任务的新功能[KYLIN-3795],特此感谢滴滴靳国卫同学对此功能的贡献。
Livy 介绍介绍
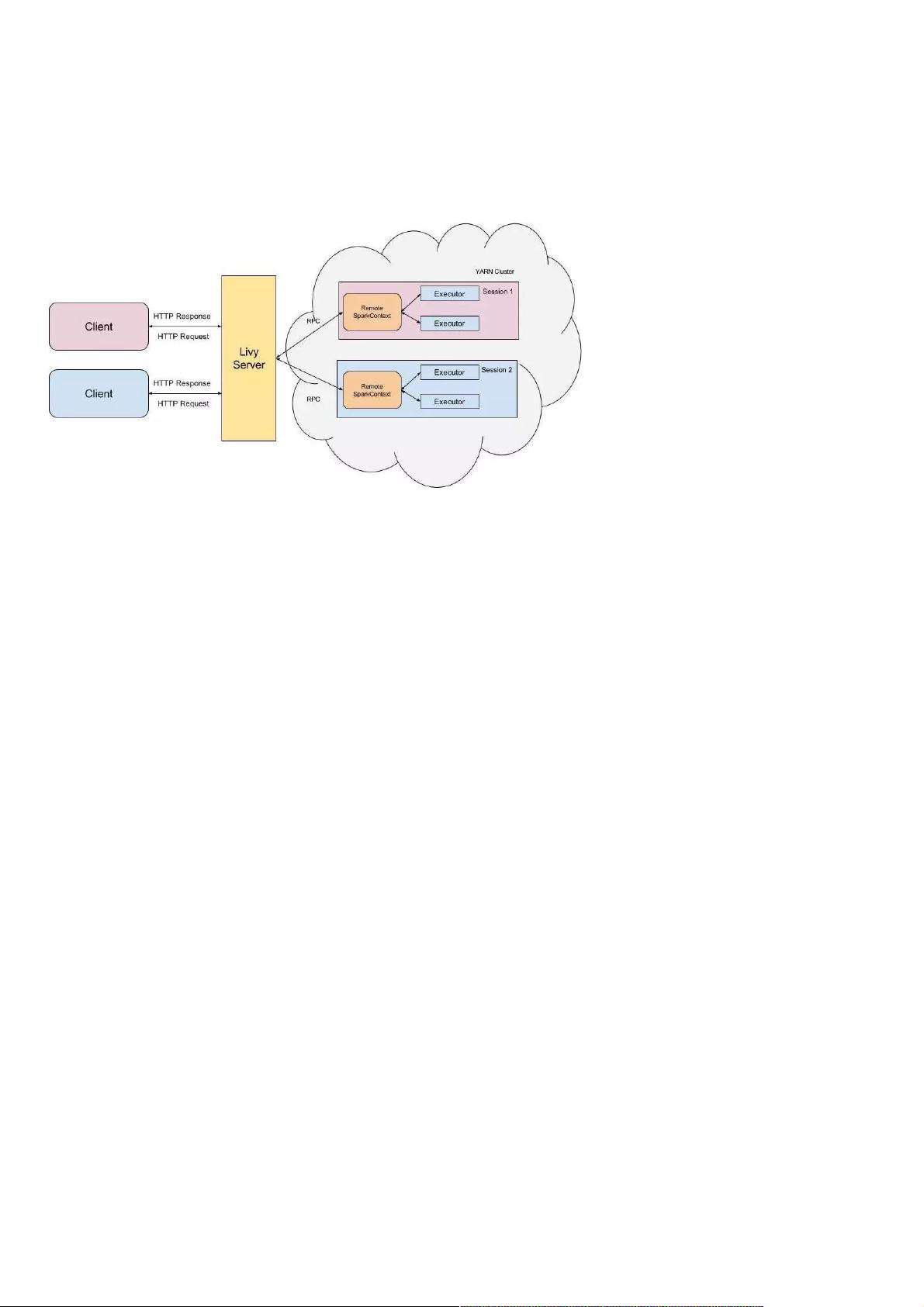
Apache Livy 是一个基于 Spark 的开源 REST 服务,是 Apache 基金会的一个孵化项目,它能够通过 REST 的方式将代码片段或是序列化的二进制代码提交到 Spark 集群中去执行。它提供了如下基本功
能:
提交 Scala、Python 或是 R 代码片段到远端的 Spark 集群上执行。
提交 Java、Scala、Python 所编写的 Spark 作业到远端的 Spark 集群上执行。
△ Apache Livy 架构
为什么使用为什么使用 Livy
1. 当前当前 Spark 存在的问题存在的问题
Spark 当前支持两种交互方式:
交互式处理
用户使用 spark-shell 或 pyspark 脚本启动 Spark 应用程序,伴随应用程序启动的同时,Spark 会在当前终端启动 REPL(Read–Eval–Print Loop) 来接收用户的代码输入,并将其编译成 Spark 作业。
批处理
批处理的程序逻辑由用户实现并编译打包成 jar 包,spark-submit 脚本启动 Spark 应用程序来执行用户所编写的逻辑,与交互式处理不同的是批处理程序在执行过程中用户没有与 Spark 进行任何的交
互。
两种方式都需要用户登录到 Gateway 节点上通过脚本启动 Spark 进程,但是会出现以下问题:
增加 Gateway 节点的资源使用负担和故障发生的可能性。
同时 Gateway 节点的故障会带来单点问题,造成 Spark 程序的失败。
难以管理、审计以及与已有的权限管理工具的集成。由于 Spark 采用脚本的方式启动应用程序,因此相比于 WEB 方式少了许多管理、审计的便利性,同时也难以与已有的工具结合,如 Apache Knox
等。
将 Gateway 节点上的部署细节以及配置不可避免地暴露给了登陆用户。
2. Livy 优势优势
一方面,接受并解析用户的 REST 请求,转换成相应的操作;另一方面,它管理着用户所启动的所有的 Spark 集群。
Livy 具有如下功能:
通过 Livy session 实时提交代码片段与 Spark 的 REPL 进行交互。
通过 Livy batch 提交 Scala、Java、Python 编写的二进制包来提交批处理任务。
多用户能够使用同一个服务器(支持用户模拟)。
能够通过 REST 接口在任何设备上提交任务、查看任务执行状态和结果。
Kylin with Livy
1. 引入引入 Livy 之前之前 Kylin 是如何使用是如何使用 Spark 的的
Spark 是在 Kylin v2.0 引入的,主要应用于 Cube 构建,构建过程介绍可以查看:https://kylin.apache.org/blog/2017/02/23/by-layer-spark-cubing/
下面是 SparkExecutable 类的 doWork 方法关于提交 Spark job 的一段代码,我们可以看到 Kylin 会从配置中获取 Spark job 包的路径(默认为 $KYLIN_HOME/lib),通过本地指令的形式提交 Spark job,然
后循环获取 Spark job 的执行状态和结果。我们可以看到 Kylin 单独开了一个线程在本地向 Spark 客户端发送来 job 请求并且循环获取结果,额外增加了节点系统压力。
@Override
protected ExecuteResult doWork(ExecutableContext context) throws ExecuteException {
//略...
String jobJar = config.getKylinJobJarPath(); //获取job jar的路径
//略...
final String cmd = String.format(Locale.ROOT, stringBuilder.toString(), hadoopConf,KylinConfig.getSparkHome(), jars, jobJar, formatArgs()); //构建本地command
//略...
//创建指令执行线程
Callable callable = new Callable<Pair<Integer, String>>() {
@Override
public Pair<Integer, String> call() throws Exception {
Pair<Integer, String> result;
try {
下载后可阅读完整内容,剩余4页未读,立即下载
2017-05-16 上传
2023-09-01 上传
2018-03-12 上传
2022-02-25 上传
161 浏览量
点击了解资源详情

weixin_38685608
- 粉丝: 1
- 资源: 995
 我的内容管理
展开
我的内容管理
展开







最新资源
- upptime-test:Kar Karan Kale的正常运行时间监控器和状态页面,由@upptime提供支持
- Practica:数据清洗与分析
- 渣浆泵过流部件的生产实践.rar
- Newsletter-Signup-Web-App:在Node中使用MailChimp API服务制作的Newsletter注册Web应用程序
- 使用SpringBoot + SpringCloudAlibaba(正在重构中)搭建的金融类微服务项目-万信金融. .zip
- 西安交大电力系统分析视频教程第27讲
- MDIN3xx_mainAPI_v0.2_26Aug2011.zip
- hibernate,java项目源码,java中如何查看方法的
- 七段图像创建:非常灵活的功能,您可以创建任意大小的七段图像。-matlab开发
- cv
- OnePortMeas:适用于一端口RF设备表征的Python App
- java,java源码网站,javaunsafe
- 网址状态
- 网络时间同步工具 NetTime 3.20 Alpha 3.zip
- css-grid-course
- Python库 | clay-3.2.tar.gz
