集成k-NN软件缺陷预测:基于Boosting的方法
需积分: 0 5 浏览量
更新于2024-08-05
收藏 457KB PDF 举报
"基于Boosting的集成k-NN软件缺陷预测方法_何亮1"
本文主要探讨了一种基于Boosting的集成k-NN(k-Nearest Neighbor)软件缺陷预测方法,旨在提升软件开发的质量和测试效率。软件缺陷预测是软件工程领域的一个重要课题,通过预测软件中的潜在缺陷,可以提前发现并修复问题,从而减少后期维护的成本。
Boosting是一种强大的机器学习技术,用于构建集成学习模型。它通过组合多个弱预测器形成一个强预测器,每个弱预测器在训练过程中关注前一轮被错误分类的数据点,从而提高整体预测的准确性。在此研究中,Boosting算法被应用到k-NN方法上,k-NN是一种基于实例的学习算法,通过寻找最近邻的k个数据点来决定新样本的类别。
文章介绍了以下主要步骤:
1. Bootstrap抽样:首先,使用Bootstrap抽样方法创建多个不同的训练数据子集。Bootstrap抽样是一种统计学上的重采样技术,它通过从原始数据集中随机抽取样本(允许重复)来构造新的样本集。
2. 生成基本预测器:在每个Bootstrap抽样数据集上训练一个k-NN预测器,形成一个基本预测器集合。这些预测器通常在不同的数据子集上会有不同的表现,因此能够提供多样性的预测结果。
3. 集成预测:当对软件模块进行预测时,每个基本预测器独立地进行预测,并且它们的预测结果被融合以生成最终的预测值。这通常涉及到加权平均或其他集成策略,以考虑不同预测器的权重。
4. 自适应分类阈值:为了判断软件模块是否为缺陷模块,文章提出了一个自适应学习方法来确定分类阈值。这个阈值会根据集成预测结果动态调整,以优化识别缺陷模块的准确性和召回率。
5. 实验验证:在NASAMDP和PROMISE AR两个标准软件缺陷数据集上进行了实验,比较了提出的集成k-NN方法与传统缺陷预测方法的性能。实验结果表明,集成k-NN方法在预测性能上有显著提升,进一步证明了软件度量元在缺陷预测中的价值。
关键词涉及的领域包括软件缺陷预测、k-近邻学习、软件度量元以及集成学习。这些关键词揭示了研究的核心内容和方法,以及其在软件工程领域的应用。
这项工作为软件质量保证提供了新的工具,通过集成Boosting和k-NN算法,提高了软件缺陷预测的准确性和效率,对于软件开发过程的质量控制具有重要意义。同时,它也强调了软件度量元在预测模型中的关键作用,这对于后续的软件工程研究和实践具有指导价值。
现此目标的
,
传统的
k-NN
方法仅能在一个原始数
据集上训练产生一个预测器
,
虽然可通过分割数据
集的方式生成多个训练子集
,
但对基于实例学习的
k-NN
方法而言
,
这样的处理方式将会使得参照样本
过少而不利于近邻的合理搜索
.
为了实现自适应的
k-NN
预测
,
需要若干个互不相同的
k-NN
预测器构
成的学习器集合
,Boosting
集成方法可较好地解决
k-NN
算法单一
k
值预测方式的不足
.
Boosting
是一种具有数据集实例权重更新机制
的集成方法
[15]
.
该方法首先在原始数据集上依照实
例权重分布抽样生成一个训练集并建立一个基本学
习模型
,
然后以该模型对原始数据集中各实例的预
测误差为基础调整实例权重
,
那些预测精度较差的
实例将被赋予更高的权重
,
这样后续的抽样和训练
过程将集中于这些较难实例的学习
,
如此反复
,
即可
生成一个基本学习模型集合
.
由于
Boosting
是一种
算法无关的集成理论
,
因此可适应于不同的弱学习
器学习算法
.
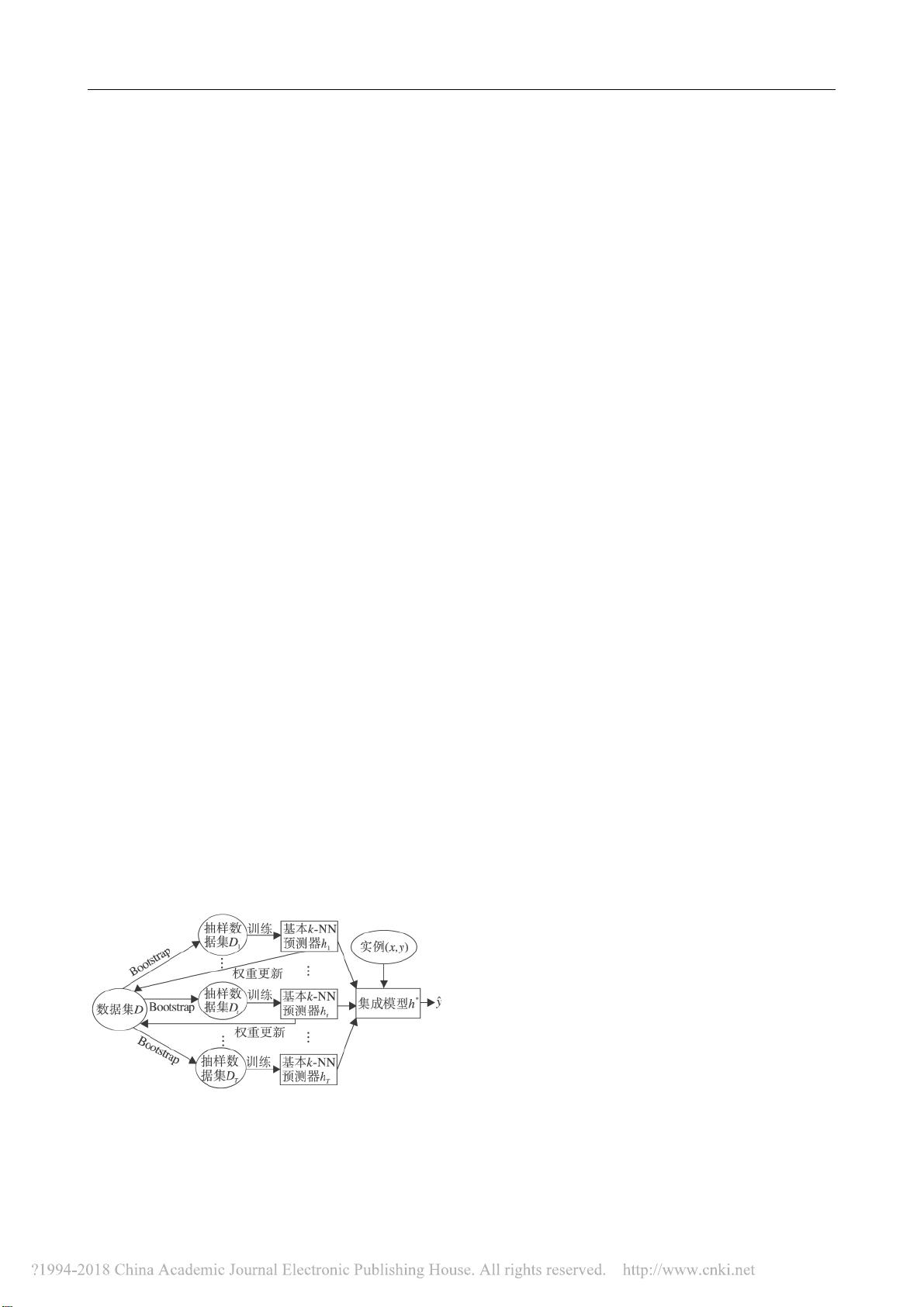
以
Boosting
理论为基础
,
图
1
给出集成
k-NN
软
件缺陷预测模型
,
该模型由一系列基本
k-NN
预测
器构成
,
每个预测器由以下两个步骤建立
. 1)
从原
始数据集
D
中经
Bootstrap
抽样生成一个新的训练
集
D
t
,t
=
1,2,…,T; 2)
在
D
t
上建立基本
k-NN
预测
器
h
t
.
由于
Bootstrap
抽样是有放回抽样
,
因此各抽
样数据集
D
t
的大小与原始数据集
D
一致
,
但部分实
例可能会重复出现于同一抽样集中
,
而另外的一些
实例则不在某个抽样集中出现
.
训练过程总是倾向
于那些重复的实例
,
基本预测器
h
t
应使
D
t
中的实例
获得尽可能理想的总体预测精度
. Bootstrap
抽样迭
代进行
T
次后即可生成
T
个基本
k-NN
预测器
,
各抽
样数据集的差异性是
T
个基本预测器对不同特性未
知实例适应能力的重要保证
.
图
1
集成
k-NN
软件缺陷预测模型
Fig. 1 Ensemble model for k-NN def ect prediction
如图
1
所示
,
我们以值对
( x,y)
表示一个实例
,
即软件模块
,
其中
x
为模块在各个软件度量元上的
取值
,y
为目标属性值
,
集成模型
h
*
对实例
( x,y)
的预测结果为
^
y.
通常
,
软件缺陷数据集在目标属性
上的取值包括模块所含缺陷数量及是否为缺陷模块
的二元标示
( True /False)
两种情况
.
本文集成
k-NN
预测模型以各实例目标属性取值为数值方式进行训
练预测
,
对于目标属性为二元标示的数据集预先将
其转换为数值
1
或
0.
在集成方法中
,
各基本预测器输出结果的集成
策略是影响集成模型预测精度的重要因素
,
应用中
可采用不同方式实现基本预测值的集成
,
如均值
、
中
位数
、
加权和等
.
考虑到缺陷预测数据分布的倾斜性
及中位数对离群点数据的不敏感性等因素
,
集成
k-NN
预测模型以各基本预测值的中位数作为最终
的集成预测结果
.
不可避免的
,
集成预测方法较之单
一学习器需要更多开销
,
不过对于预测精度的提升
而言
,
这样的付出是值得的
.
2. 2
基本
k-NN
预测器
每个基本
k-NN
预测器均由两个参数描述
: 1
个
合理的
k
值及相应的属性子集
,
训练过程以最小化
总体误差的方式筛选出这两个参数
.
具体的
,
误差可
通过各种绝对或相对度量方式计算
.
对于软件缺陷
预测而言
,
由于缺陷通常仅分布于少量模块中
,
其余
模块均为不含缺陷的正常模块
,
因此数据集中大部
分实例在目标属性
y
上的取值为
0,
这使得相对误差
难以计算
.
在此情况下
,
采用平均绝对误差度量每个
k
值及相应属性子集在抽样集上的预测性能
.
值得
注意的是
,
通常以最小化平均绝对误差为条件选择
模型参数时可能会出现偏好极端实例的情况
.
例如
,
对于个别具有很大
y
值的实例
,
如果某参数恰好可
准确预测此类实例
,
则在计算平均绝对误差时其降
幅就会较显著
,
该组
k
值及属性子集被选为模型参
数的可能性也会较高
,
但实际情况可能仅仅是个别
实例获得理想的预测精度
,
这并不符合参数选择的
初衷
.
我们更希望选定的模型参数应使训练集获得
最理想的总体预测精度而不仅仅是实现个别实例的
准确预测
.
集成
k-NN
预测可在一定程度上避免该现
象的出现
.
训练集中因
Bootstrap
抽样产生的重复实
例将具有相同的预测误差
,
此外
,
特征相似的实例其
预测误差也较接近
,
这些实例在参数学习过程中将
会影响平均绝对误差的计算
,
同时也会降低那些目
标属性值较大的实例在平均绝对误差计算中的干
扰
,
最终选择的基本预测器参数往往会在这些实例
上取得较好的预测精度
,
这亦是
Boosting
方法的目
的所在
.
实例权重的不断更新保证了抽样数据集的
497
模式识别与人工智能
25
卷
剩余10页未读,继续阅读
2022-08-03 上传
2021-11-05 上传
2021-10-03 上传
2022-09-19 上传
2022-07-14 上传
2021-02-11 上传
2011-06-28 上传
2022-06-20 上传
2022-07-15 上传

好运爆棚
- 粉丝: 32
- 资源: 342
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
