SVM入门详解:优势、理论基础与应用
SVM (Support Vector Machine) 是一种强大的机器学习算法,最初由Cor
tes和Vapnik在1995年提出,特别适用于小样本、非线性和高维模式识别任务。它的核心思想建立在统计学习理论的基础之上,尤其是VC维理论和结构风险最小化原则。VC维是一种衡量函数类复杂性的指标,表示一个模型能够区分不同数据的能力,数值越大,问题越复杂。SVM通过优化模型复杂性和泛化能力之间的平衡,达到最佳性能。
SVM的优势在于其独立于样本维度,即使面对上万个特征维度的数据集,如文本分类问题,也能有效地处理,这是通过引入核函数实现的。核函数将低维数据映射到高维空间,使得原本非线性的问题变得线性可分。这样,SVM并不直接处理原始输入,而是工作在特征空间,简化了问题的复杂性。
结构风险最小化原理指的是在训练误差(即模型对训练数据的拟合程度)和泛化误差(模型对未知数据的预测能力)之间寻找一个最优的权衡。由于真实模型无法直接获取,我们通过结构风险最小化来评估和改进模型,避免过度拟合(过度适应训练数据导致对新数据表现不佳)。
与传统的机器学习方法不同,如基于规则或启发式的方法,SVM提供了更为精确的学习效果估计和对样本数量需求的分析,使得构建分类系统更加有指导性和原则性。《Statistical Learning Theory》这本书详细阐述了这一理论框架,强调了统计机器学习的严谨性与传统方法的直观性之间的差异。
SVM作为一门强大的工具,不仅在理论上具有深厚的统计学习理论基础,而且在实践中展现出优秀的适应性和推广能力,尤其适合处理复杂和高维的数据问题,对于初学者来说,理解和掌握SVM的原理和应用是非常有价值的。
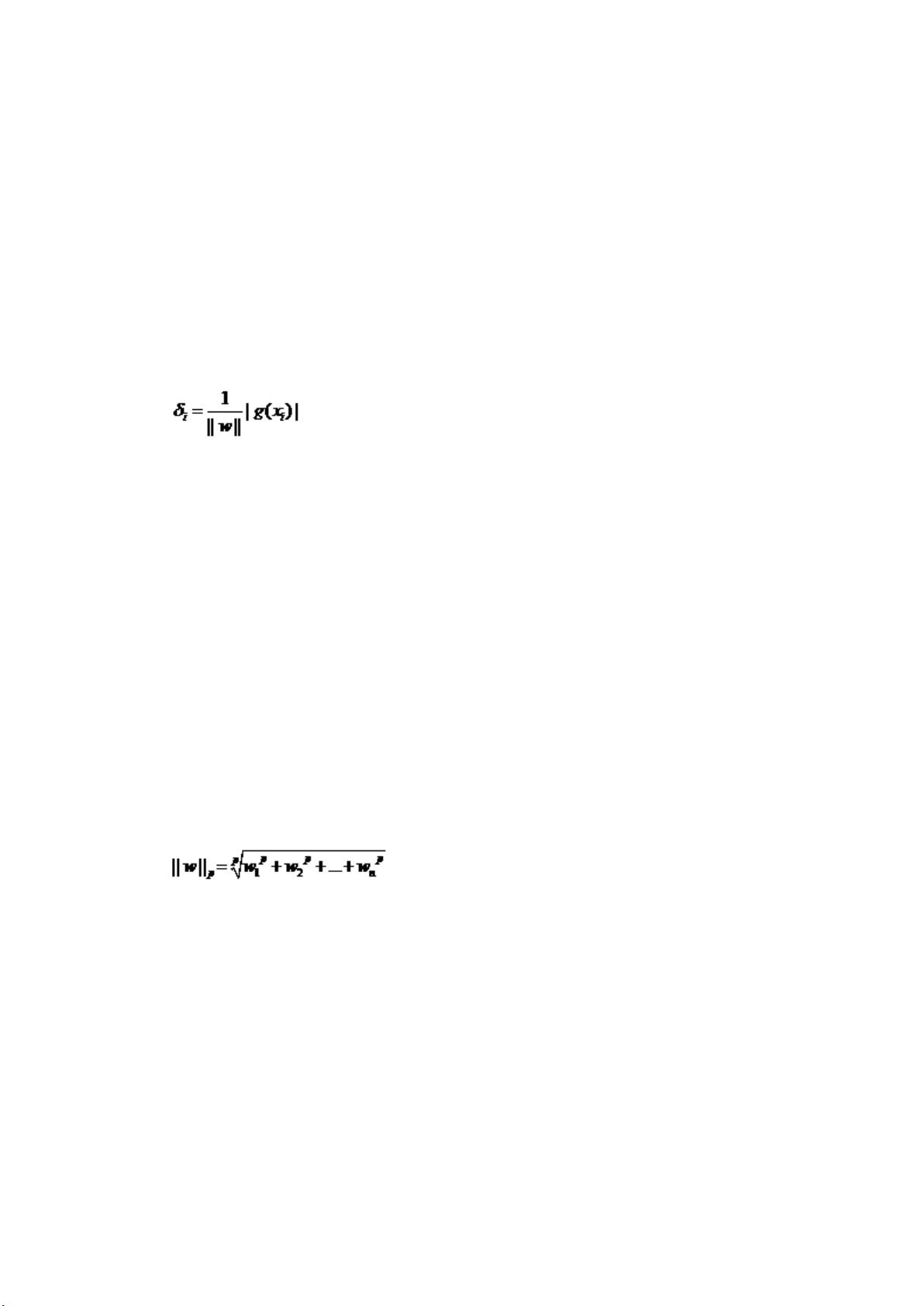
首先注意到如果某个样本属于该类别的话,那么 wxi+b>0(记得么?这是因为我们所选
的 g(x)=wx+b 就通过大于 0 还是小于 0 来判断分类),而 yi 也大于 0;若不属于该类别的
话,那么 wxi+b<0,而 yi 也小于 0,这意味着 yi(wxi+b)总是大于 0 的,而且它的值就等于|
wxi+b|!(也就是|g(xi)|)
现在把 w 和 b 进行一下归一化,即用 w/||w||和 b/||w||分别代替原来的 w 和 b,那么间
隔就可以写成
这个公式是不是看上去有点眼熟?没错,这不就是解析几何中点 xi 到直线 g(x)=0 的距
离公式嘛!(推广一下,是到超平面 g(x)=0 的距离, g(x)=0 就是上节中提到的分类超平面)
小 Tips:||w||是什么符号?||w||叫做向量 w 的范数,范数是对向量长度的一种度量。我
们常说的向量长度其实指的是它的 2-范数,范数最一般的表示形式为 p-范数,可以写成如
下表达式
向量 w=(w1, w2, w3,…… wn)
它的 p-范数为
看看把 p 换成 2 的时候,不就是传统的向量长度么?当我们不指明 p 的时候,就像||w|
|这样使用时,就意味着我们不关心 p 的值,用几范数都可以;或者上文已经提到了 p 的值,
为了叙述方便不再重复指明。
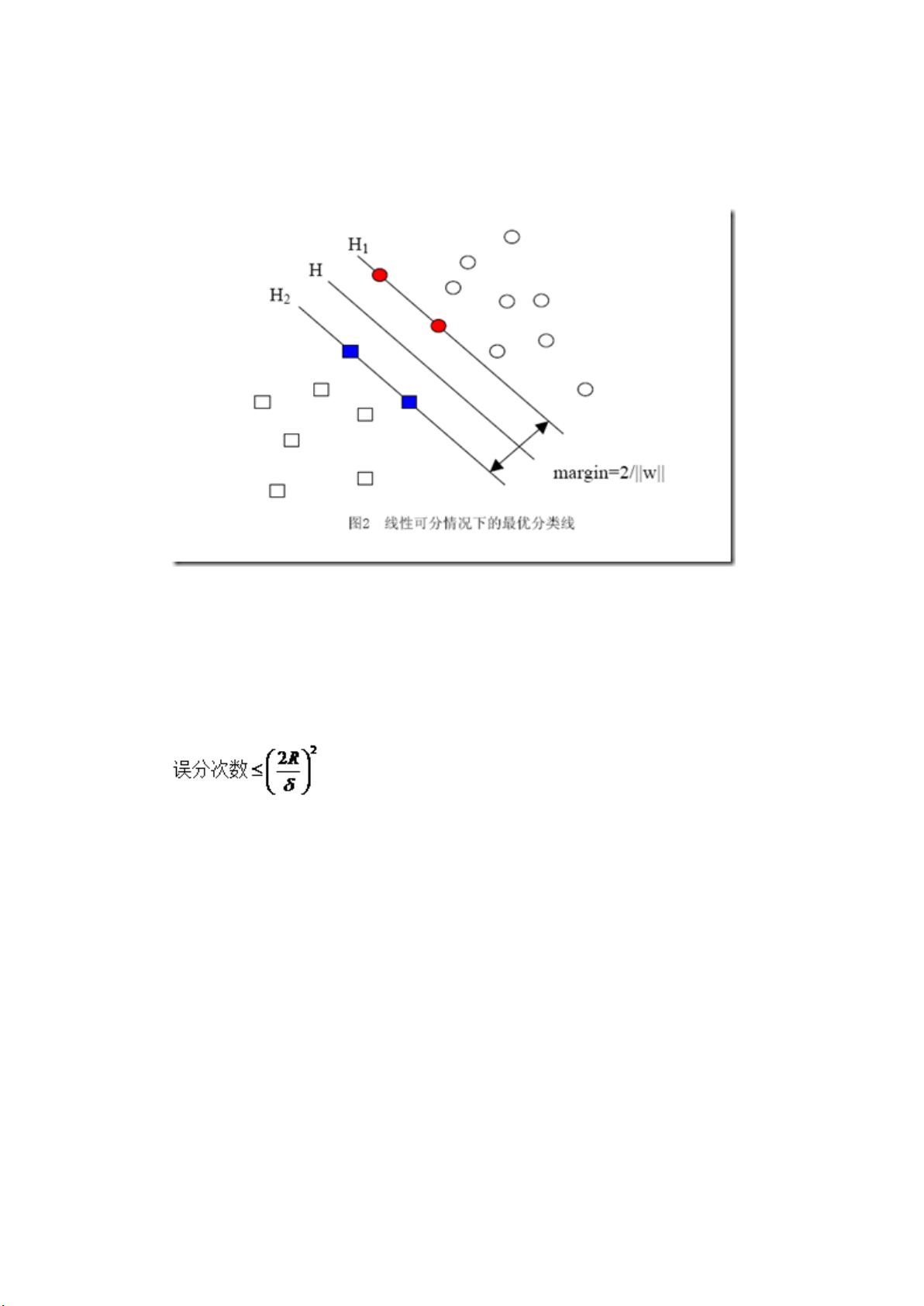
当用归一化的 w 和 b 代替原值之后的间隔有一个专门的名称,叫做几何间隔,几何间
隔所表示的正是点到超平面的欧氏距离,我们下面就简称几何间隔为“距离”。以上是单个点
到某个超平面的距离(就是间隔,后面不再区别这两个词)定义,同样可以定义一个点的集
剩余30页未读,继续阅读
2023-06-01 上传
2024-09-10 上传
2023-09-14 上传
2023-03-16 上传
2023-05-16 上传
2023-04-22 上传
2023-09-27 上传
2024-07-15 上传

yamier712
- 粉丝: 1
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
