腾讯大数据分析架构优化与瓶颈突破
需积分: 15 168 浏览量
更新于2024-07-16
收藏 3.71MB PDF 举报
"彭渊-如何突破腾讯大数据分析架构瓶颈"
这篇文档主要探讨了在腾讯公司面临的海量数据处理和分析架构的挑战以及相应的解决方案。以下是基于提供的部分内容解析的关键知识点:
1. **大数据处理框架:**
- Storm:一个实时计算框架,用于处理持续的数据流,保证每个事件被恰好处理一次(Exactly-once语义)。
- Spark Streaming:基于Apache Spark的微批处理框架,提供高吞吐量和低延迟的流处理能力。
- Flink:Apache Flink是一个开源流处理框架,支持批处理和流处理,并且提供了Exactly-once语义。
2. **SQL查询:**
- 在大数据分析中,SQL查询是常见的数据查询方式,文档中提到的`sql85`可能是指特定的SQL优化或版本,用于高效地处理大数据集。
3. **数据统计:**
- `count^T`可能是对某个字段的计数操作,统计特定数据的数量。
- `App1_&41_
81`等结构可能是特定应用的统计数据,例如用户行为或交易记录。
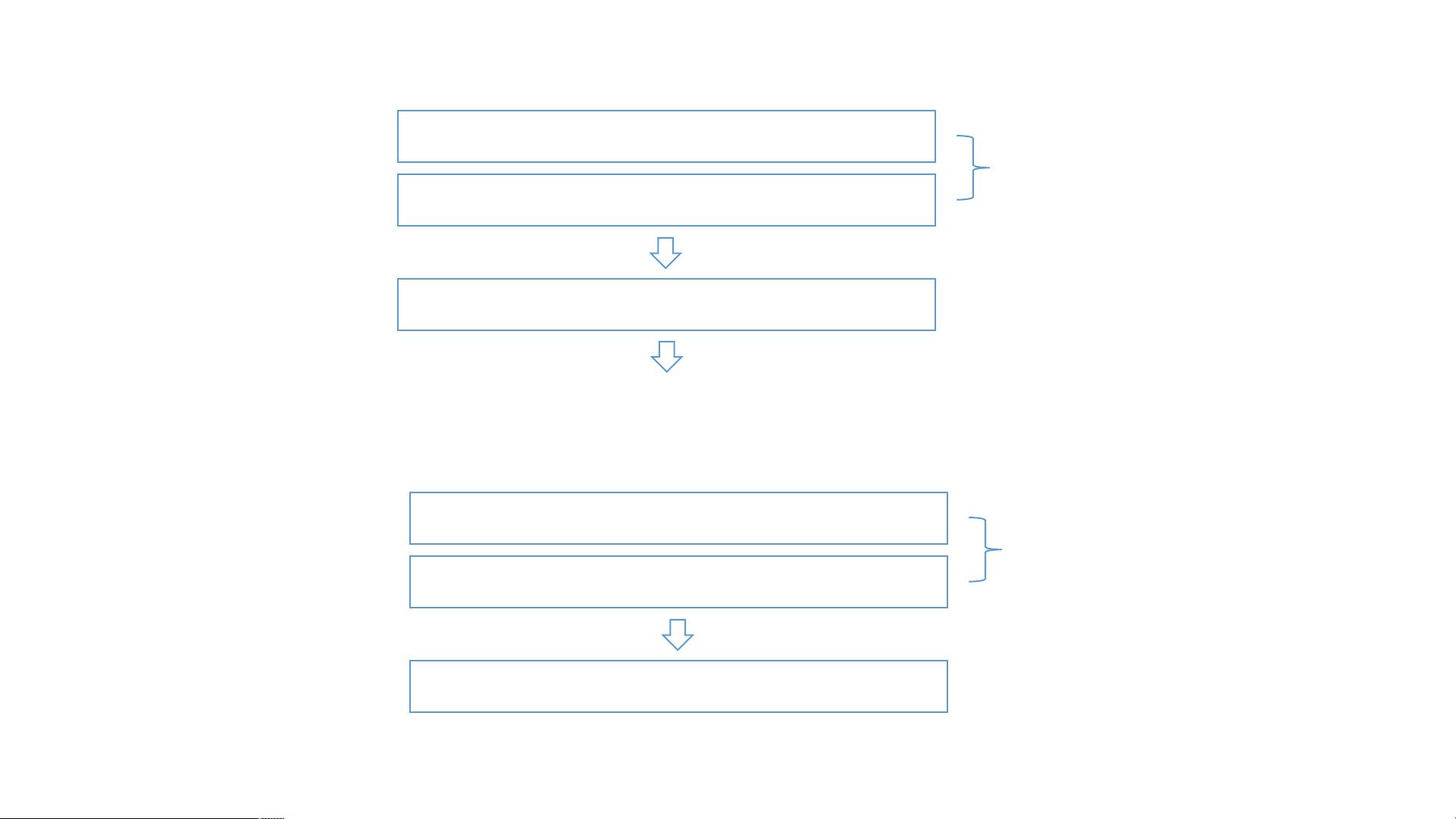
4. **位图索引(Bitmap Index):**
- 位图索引是一种高效的存储和检索稀疏数据的方法,尤其适用于处理大量离散值的列。文档中的`byte-0`到`byte[n]`表示位图的各个字节,`Index=17`指出第17位被设置为1。
- `BitMap1*{h`可能是一个位图的标识或编码,用于快速查找和匹配数据。
5. **数据处理流程:**
- 文档中提到了多个步骤,如`App1`、`App2`、`App3`,这些可能是数据处理的不同阶段或者不同的应用程序。
- `-2(`、`5(`等可能是数据转换或过滤操作的代码表示。
- `Pv`和`Uv`可能分别代表页面浏览量(Pageviews)和唯一访问者(Unique Visitors)等网站分析指标。
6. **数据存储与查询:**
- `hadoop/hivedm`暗示了使用Hadoop和Hive进行大数据存储和管理,Hive是基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能。
- `select distinct count…from…group by join…`展示了标准的SQL聚合查询,用于获取数据的唯一计数,分组和连接操作。
7. **性能优化:**
- `sqlbL>q{@@`和`5[:AYt4O?B/`可能涉及到SQL查询的性能优化技术,如使用索引、优化查询计划等。
这些内容反映了腾讯在大数据分析架构上所面临的挑战,包括实时性、效率、准确性和可扩展性,并展示了使用各种工具和技术来解决这些问题的实例。通过不断优化和创新,腾讯能够处理和分析海量数据,从而驱动业务决策和提升用户体验。
BitMap
byte-0
10000000 00100000 10010000 00110000……
byte-1byte-2byte-3byte[n]
Index=17
bitmap
1id1bit20id20bit
238m200k
2bitmapbitmap
hadoop/hiveselect disAnct
count…from…groupby join…sql30
sqljoin
剩余36页未读,继续阅读
2018-01-13 上传
2022-01-16 上传
点击了解资源详情
点击了解资源详情
2024-10-26 上传
2024-10-26 上传
2024-10-26 上传

没读过书的孩子
- 粉丝: 98
- 资源: 162
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握压缩文件管理:2工作.zip文件使用指南
- 易语言动态版置入代码技术解析
- C语言编程实现电脑系统测试工具开发
- Wireshark 64位:全面网络协议分析器,支持Unix和Windows
- QtSingleApplication: 确保单一实例运行的高效库
- 深入了解Go语言的解析器组合器PARC
- Apycula包安装与使用指南
- AkerAutoSetup安装包使用指南
- Arduino Due实现VR耳机的设计与编程
- DependencySwizzler: Xamarin iOS 库实现故事板 UIViewControllers 依赖注入
- Apycula包发布说明与下载指南
- 创建可拖动交互式图表界面的ampersand-touch-charts
- CMake项目入门:创建简单的C++项目
- AksharaJaana-*.*.*.*安装包说明与下载
- Arduino天气时钟项目:源代码及DHT22库文件解析
- MediaPlayer_server:控制媒体播放器的高级服务器
