多索引哈希:汉明空间的快速搜索
15 浏览量
更新于2024-08-25
收藏 407KB PDF 举报
“Fast Search in Hamming Space with Multi-Index Hashing”是计算机科学领域的一篇研究论文,由Mohammad Norouzi、Ali Punjani和David J. Fleet共同撰写,来自多伦多大学计算机科学系。这篇论文关注的是在视觉应用中使用紧凑型二进制编码进行快速近邻搜索的问题。
在图像处理和计算机视觉领域,二进制编码常被用来将数据映射到紧凑的形式,以便于执行近似最近邻(Approximate Nearest Neighbor, ANN)搜索。传统的做法是将这些二进制码作为哈希表的直接索引,但通常只限于32位或更短的代码。然而,这篇论文指出,超过32位的二进制代码并未被充分利用,因为之前认为这种方式效率不高。
作者提出了一种新的方法,即使用多索引哈希(Multi-Index Hashing)来对较长的二进制码子串构建多个哈希表,从而实现精确的K近邻搜索。这种方法易于实现,存储效率高,并且在均匀分布的代码中具有亚线性的时间复杂度。实验结果表明,相比于线性扫描基准,这种方法能显著提升搜索速度,即使是在包含十亿个项目的大型数据集上,以及使用64位或128位的二进制码和搜索半径高达25位的情况下,性能提升也非常显著。
1. 引言
随着计算机视觉技术的发展,将图像数据转化为紧凑的二进制码进行快速近邻搜索已经成为一种趋势。这种方法被广泛应用于诸如图像分类、检索和识别等任务中。传统的二进制编码方法受限于代码长度,超过一定长度后,其在哈希表中的直接索引性能下降。这篇论文的创新之处在于,它挑战了这一观点,通过多索引哈希策略,使长码能够有效地用于精确的近邻搜索,这对于大规模数据集的处理尤其重要。
2. 多索引哈希算法
多索引哈希算法的核心是将长二进制码分割成多个较短的子串,然后为每个子串建立一个独立的哈希表。这样,当查询一个二进制码时,可以分别在各个哈希表中进行查找,结合所有结果得到近邻列表。这种方法能够减少因码长增加而带来的搜索时间增加,同时保持搜索的准确性。
3. 实验与评估
论文通过实验证明了提出的多索引哈希算法在实际应用中的高效性。在不同大小的数据集、不同的代码长度和搜索半径下,该方法都表现出明显的性能优势,特别是在处理大量数据和长码的情况下,搜索速度显著快于传统的线性扫描方法。
4. 结论与未来工作
多索引哈希为长二进制码的近邻搜索提供了一个有效的解决方案,它在存储和计算效率方面都表现出良好的性能。未来的研究可能涉及进一步优化算法,如提高哈希函数的设计,以及适应非均匀分布的数据集。
"Fast Search in Hamming Space with Multi-Index Hashing"这篇论文揭示了一种利用长二进制码进行高效近邻搜索的新方法,为图像处理和计算机视觉领域的数据检索技术提供了重要的理论支持和实践指导。
Fast Search in Hamming Space with Multi-Index Hashing
Mohammad Norouzi Ali Punjani David J. Fleet
Department of Computer Science
University of Toronto
{norouzi,alipunjani,fleet}@cs.toronto.edu
Abstract
There has been growing interest in mapping image data
onto compact binary codes for fast near neighbor search in
vision applications. Although binary codes are motivated
by their use as direct indices (addresses) into a hash ta-
ble, codes longer than 32 bits are not being used in this
way, as it was thought to be ineffective. We introduce a
rigorous way to build multiple hash tables on binary code
substrings that enables exact K-nearest neighbor search in
Hamming space. The algorithm is straightforward to im-
plement, storage efficient, and it has sub-linear run-time
behavior for uniformly distributed codes. Empirical results
show dramatic speed-ups over a linear scan baseline and
for datasets with up to one billion items, 64- or 128-bit
codes, and search radii up to 25 bits.
1. Introduction
There has been growing interest in mapping image data
onto compact binary codes for fast near neighbor search in
vision applications (e.g., [20, 21, 23]). Binary codes are
storage efficient and comparisons require just a small num-
ber of machine instructions; millions of binary codes can be
compared to a query in less than a second. But the most
compelling reason for binary codes is their use as direct
indices (addresses) into a hash table, yielding a dramatic
increase in search speed compared to an exhaustive linear
scan (e.g., [24, 19, 16]).
The problem is that, in practice, using binary codes as
hash indices is not necessarily efficient. To find near neigh-
bors one needs to examine all hash table entries (or buck-
ets) within some Hamming ball around the query. And the
number of such buckets grows near-exponentially with the
search radius (Fig. 2a). Even with a small search radius, the
number of buckets to examine may be larger than the num-
ber of items in the database, hence slower than linear scan.
Recent papers on binary codes mention the use of hash ta-
bles, but resort to linear scan when codes are longer than 32
bits (e.g., [23, 19, 12, 16]), although longer codes are often
necessary to preserve sufficient similarity (e.g., see Fig. 5).
200 500 1000
0
5
10
15
20
time per query (s)
dataset size (millions)
Linear scan
1000−NN
100−NN
10−NN
200 500 1000
0
0.05
0.1
0.15
0.2
dataset size (millions)
Linear scan
1000−NN
100−NN
10−NN
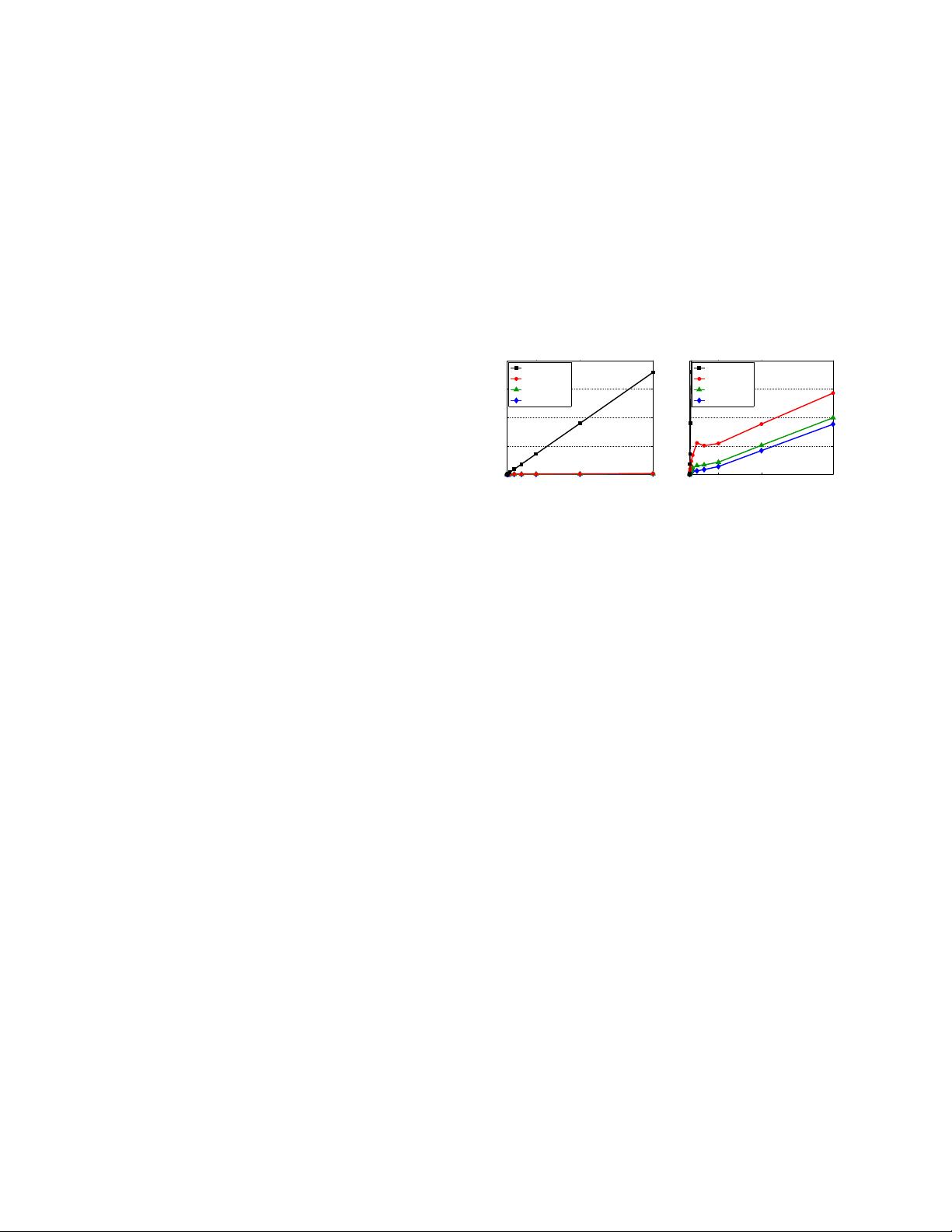
Figure 1. Nearest-neighbor search on a database of 64-bit binary
codes learned from SIFT descriptors. Run-times per query are
shown for the proposed multi-index hashing algorithm, searching
for 10, 100, and 1000 nearest neighbors. They are compared to
a linear scan baseline. Left and right plots show different vertical
scales; i.e., the vertical axis of the right plot is 100 times smaller
than the left, showing query times between 0 and 0.2s.
This paper presents a new algorithm for exact K-nearest
neighbor search on binary codes that is dramatically faster
than linear scan. This has been an open problem since
the introduction of hashing techniques with binary codes.
Our new multi-index hashing algorithm exhibits sub-linear
search times, is storage efficient, and straightforward to im-
plement. As an example, Fig. 1 plots CPU run-times per
query as a function of the size of a database comprising
64-bit codes learned from SIFT descriptors with Minimal
Loss Hashing [16]. Our current implementation searches a
dataset of a billion codes hundreds of times faster than lin-
ear scan, on a single computer.
1.1. Background: Problem and Related Work
Nearest neighbor (NN) search on binary codes has been
used for image search [18, 23, 24], matching local fea-
tures [9, 21], and parameter estimation [20]. Such tech-
niques begin with a similarity-preserving mapping from
high-dimensional data to binary codes. For many prob-
lems one wants to preserve Euclidean distance (e.g., [5,
12, 18, 21, 24]), while others focus on semantic similarity
(e.g., [16, 20, 19, 23]). Our algorithm does not depend on
the specific method for generating the binary codes. Rather,
we are primarily concerned with fast search in Hamming
1
下载后可阅读完整内容,剩余7页未读,立即下载
2017-12-27 上传
2021-02-09 上传
2024-10-01 上传
2021-05-29 上传
2021-05-30 上传
2021-04-26 上传
2013-03-05 上传
2021-06-01 上传
2013-01-25 上传

weixin_38692928
- 粉丝: 6
- 资源: 913
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
