Jupyter 中如何重新导入已修改的 Python 模块
PDF格式 | 403KB |
更新于2024-08-28
| 80 浏览量 | 举报
"在Jupyter环境中,如何有效地重新导入已修改的Python模块,确保每次运行都能使用最新的代码,是数据分析工作中常见的一种需求。本文将探讨在Jupyter Notebook中遇到的问题及解决方案,特别是当需要调用外部模块,如`analyze.py`,并且该模块被频繁修改时的处理方式。"
在Jupyter Notebook中,通常我们可以通过`import`语句来引入外部Python模块,例如`from analyze import FathersAnalyzer`。然而,一旦`analyze.py`被修改,Jupyter Notebook并不会自动更新导入的模块,而是继续使用旧版本的代码。这是因为Python的导入机制会在首次导入后缓存模块,后续的相同导入请求会被忽略。
面对这个问题,有三种可行的解决方案:
1. **使用`importlib.reload()`**:
可以在每个需要使用`analyze`模块的Cell顶部使用`importlib.reload(analyze)`来强制重新加载模块。但这需要在每个Cell中都进行此操作,可能导致代码可读性和维护性的降低。
2. **利用Jupyter的 `%autoreload` 魔术命令**:
`%load_ext autoreload` 命令可以扩展Jupyter的功能,然后使用 `%autoreload 1` 或 `%autoreload 2` 来设置自动重载模块。`%autoreload 1` 会在执行每个Cell时检查并重新加载所有导入的模块,而 `%autoreload 2` 更进一步,它会递归地重新加载所有依赖的模块。这种方法使得在修改模块后,无需手动在每个Cell中添加`reload`命令,提高了代码的可维护性。
示例:
```
%load_ext autoreload
%autoreload 1
import analyze
```
3. **使用 `%run` 魔术命令**:
如果模块是一个独立的Python脚本,可以使用 `%run analyze.py` 直接运行脚本,这样每次运行都会使用最新的代码。但请注意,这种方式不会将模块内容导入到当前Notebook的命名空间中,所以可能需要使用全局变量或返回值来访问模块功能。
在选择合适的解决方案时,应考虑代码的可读性、可维护性以及团队协作的需求。`%autoreload` 魔术命令通常是最方便的选择,因为它可以在不干扰代码结构的情况下自动处理模块的更新。然而,在大型项目中,确保所有开发者了解并正确使用这些技巧至关重要,以避免潜在的错误和混淆。
总结来说,理解Jupyter Notebook的运行机制和Python的导入系统对于高效的数据分析工作至关重要。通过掌握如何正确地重新导入和更新模块,可以在迭代开发过程中节省大量时间,避免因使用旧代码而导致的错误。在实际应用中,根据项目需求灵活运用上述方法,能够提升开发效率和代码质量。
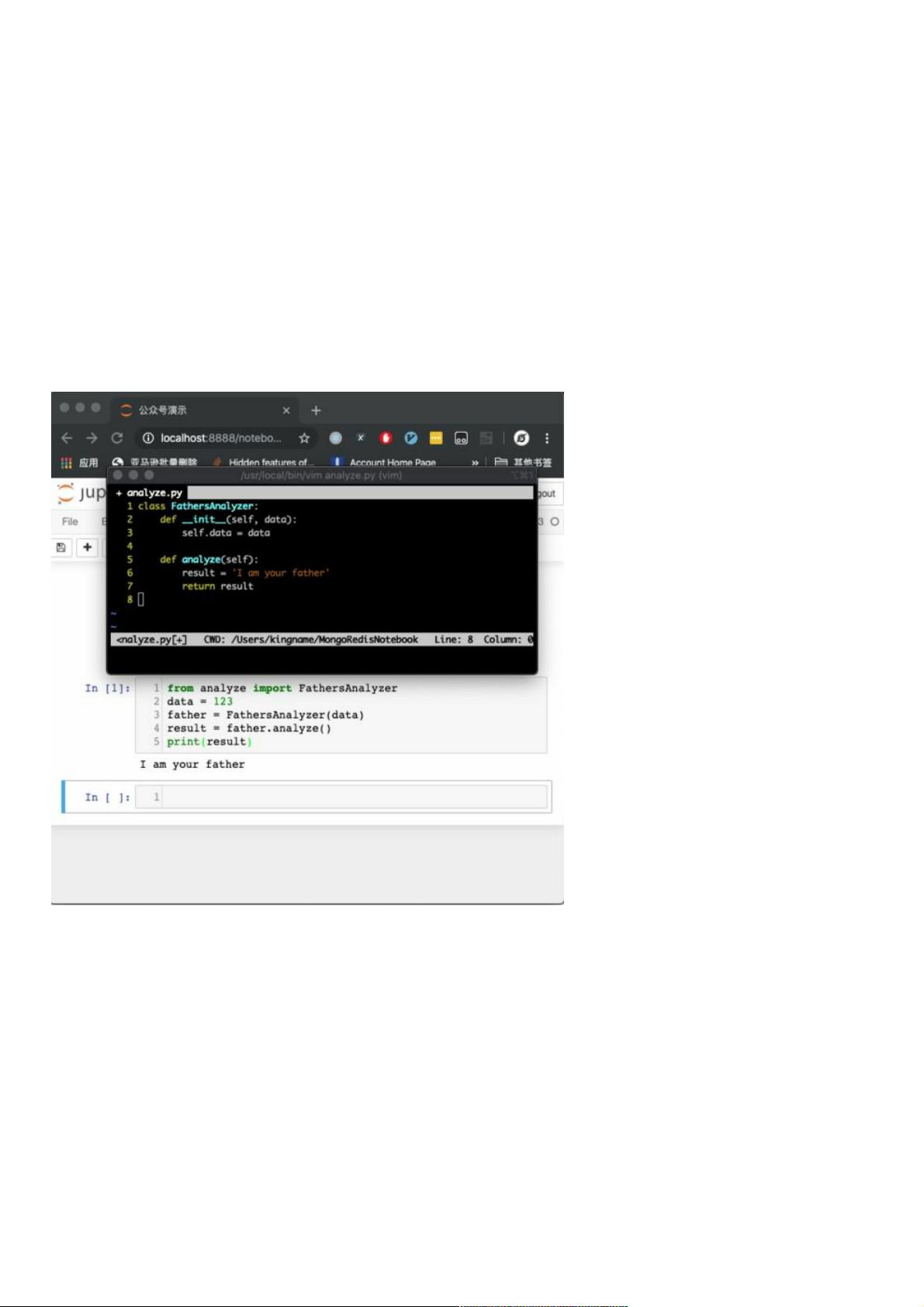
在在 Jupyter 中重新导入特定的中重新导入特定的 Python 文件文件(场景分析场景分析)
Jupyter 是数据分析领域非常有名的开发环境,使用 Jupyter 写数据分析相关的代码会大大节约开发时间。
设想这样一个场景:别的部门的同事传给你一个数据分析的模块,用于实现对数据的高级分析。模块里面有上百个函数。
如果直接写 Python 文件来调用数据分析模块,那么使用方法非常简单:
from analyze import FathersAnalyzer
data = [...] father = FathersAnalyzer(data)
result = father.analyze()
print(f'分析结果为:{result}')
现在,你需要使用 Jupyter 来调用这个分析模块。你应该怎么在 Jupyter里面调用?
你可能会觉得,这还不简单吗?直接把这个模块的代码与 Jupyter Notebook 的 .ipynb 文件放在一起,然后在 Jupyter 里面像导
入普通模块那样导入即可,如下图所示:
那么现在问题来了,如果我此时修改了 analyze.py 文件,会出现什么情况呢?
我们改一下看看,如下图所示。
下载后可阅读完整内容,剩余3页未读,立即下载
相关推荐




weixin_38500047
- 粉丝: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- STM32F103VE跑马灯实验程序:GPIO控制
- React表单验证新方案:calidation库的使用指南
- SSM框架整合教程:实现电影系统增删改查及三级联动功能
- 情人节创意PPT模板:爱意动效设计
- 全面解析Java数据结构与算法源码
- 掌握React:初学者的自学资源仓库
- Npoi 2.0实现无需Office的Word/Excel操作
- 16X16点阵显示屏课程设计与仿真实践
- 使用Hermite过滤器在JavaScript中实现高效画布图像缩放
- 免费版EasyCam桌面录像精灵:操作简便的视频录制工具
- 掌握ArcGIS导出图片技巧:自定义大小的完美截图
- STM32-F3/F4/F7/H7系列双机SPI通信实践与分析
- 使用公共API信息进行实验性JavaScript项目
- MyBatis核心包及Spring整合包下载指南
- 构建高效优化的静态网站样板
- CentOS 6.5安装配置详细步骤
