搭建Hadoop集群实战:环境配置与Linux运维提升
需积分: 10 158 浏览量
更新于2024-07-20
收藏 6.64MB PDF 举报
本文档是一篇关于Hadoop集群机安装配置与应用的小结,旨在通过实践操作帮助读者深入了解Hadoop的工作原理和在Linux环境中的实际运用,提升运维技能。作者首先明确了实验的目的,即通过搭建Hadoop集群环境,实现理论学习与实践经验相结合。
实验环境要求包括:
1. 至少三台装有Linux操作系统的主机,可以选择物理机或虚拟机。在这里,推荐使用vmware虚拟机,如vmware Workstation或vmware Fusion,提供30天的免费试用版本,以方便部署和管理。对于Windows用户,可以从官方网址下载安装。
2. 必须安装Java Development Kit (JDK),作者推荐的是JDK 8u91版本,适用于32位和64位系统,但建议根据主机系统的具体配置选择对应版本。文中还提及了之前CentOS上可能存在的不同版本JDK,如JDK 1.8.0_73。
3. Hadoop版本选择的是较早期的Hadoop 0.20.2,尽管这可能不是最新版本,但对于教学和理解基础架构是有价值的。读者可以在Apache官网找到Hadoop的官方下载地址。
文档接下来可能会详细讲解如何在Ubuntu 14.04.4、Kali 2.0和CentOS 7这三种常见的Linux发行版上安装Hadoop,包括设置环境变量、配置文件、启动守护进程等步骤。此外,还可能涉及Hadoop的分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce编程模型的配置与使用。在配置过程中,作者可能会强调对Linux命令行的理解和操作,以及如何处理可能出现的问题和优化性能。
这篇小结提供了构建Hadoop集群的入门指南,不仅涵盖了技术细节,还有助于读者提高在Linux环境下进行Hadoop项目的部署和运维能力。通过阅读和实践,读者将能够更好地理解和应用Hadoop技术。

在正式开始相关操作之前,我们看一看搭建 hadoop 的必要条件。知道了必要条
件就能更加容易的理解后面我们的操作是怎么一回事,为什么要这么做。知其所以然,
才能有的放矢,个性发展。
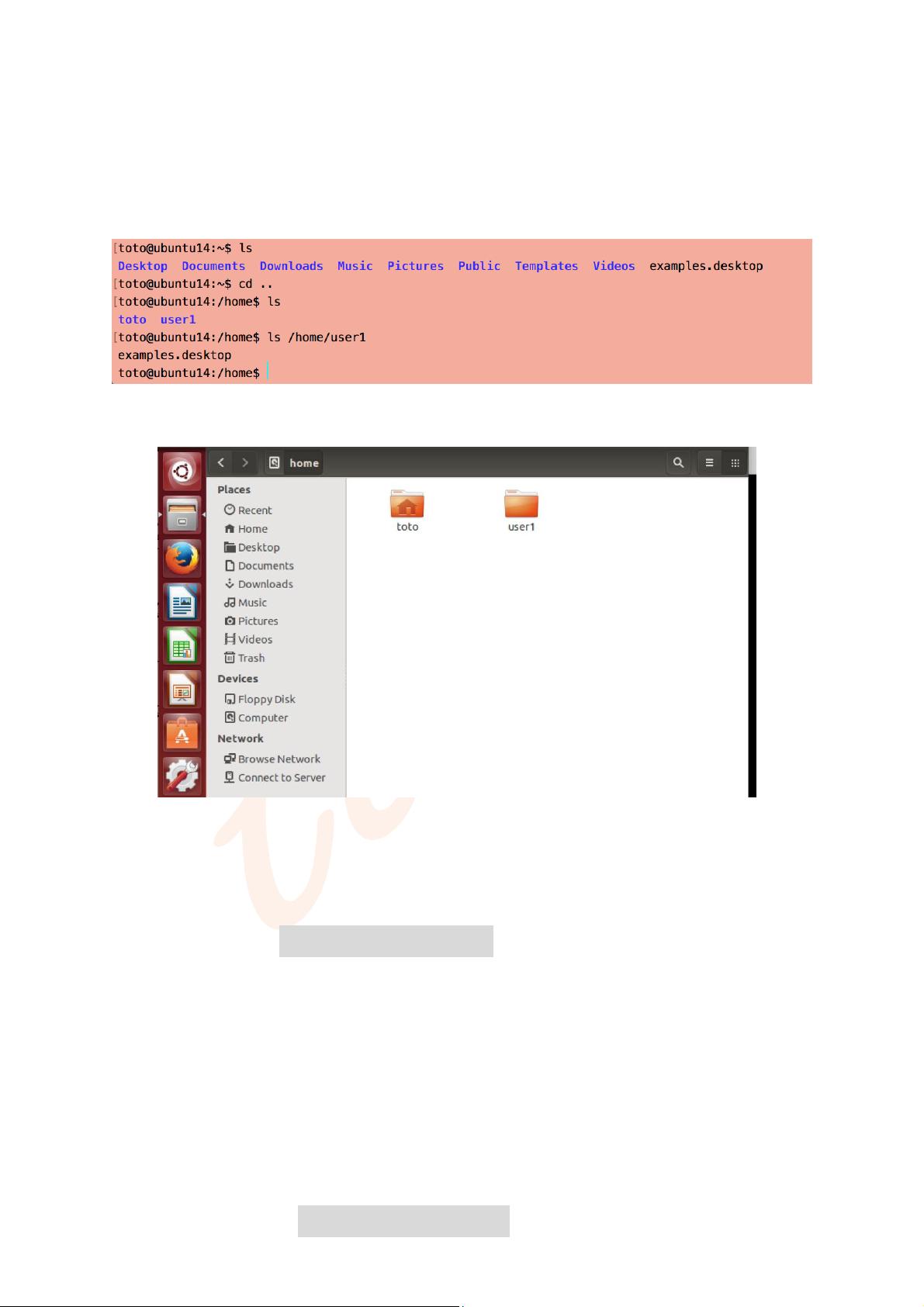
多节点分布式环境下的两个必要条件:
a. 每个节点拥有相同的账户名(运行所需的基础权限都必须有)。
b. Hadoop 的文件路径相同。如/home/user1/hadoop。
也正因为如此,推荐大家和我一样用普通账户安装 hadoop。这样在安装系统的
时候就不必考虑三个节点都要创建相同的(管理员)账户。
下面进入实际动手环节:
4.2.1 Linux 系统账户创建与授权
4.2.1.1 用系统管理员账户登录,创建一个用户。
比如名字叫做 user1,你可以根据自己情况随便发挥。但是注意这三个机器都
要创建这么一个用户。(系统管理员就是你安装虚拟机系统或者安装实体主机系统的
时候设置的账户和密码。)
方法一:适用于所有 Linux 版本
sudo useradd -m user1;
sudo passwd user1;
/* 以默认配置方式(比如创建用户目录)添加一个名为 user1 的(标准)用户*/
/* 执行命令后输入你要修改的的账户密码。注意在输入密码的时候密码完全不可
见(区别于平时注册时输入的密码显示为****),连**都不会有。所以密码要一口气


剩余71页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-09-19 上传
2018-09-20 上传
2018-04-13 上传
2022-11-02 上传
2018-05-02 上传
2019-07-30 上传

等风来6321
- 粉丝: 2
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
